2023大厂八股文
前言
2022有的大厂面试题不会在2023再次出现(也有可能会因为粗心加上,欢迎issue或者PR指正和修改),如果想要了解可以先看2022大厂面试版本。
🐦Java 基础
ArrayList线程安全吗?把ArrayList变成线程安全有哪些方法?(2023 美团)
将ArrayList变成线程安全有几种方法:
- 使用Collections.synchronizedList() 方法将ArrayList转换为线程安全的List。该方法会返回一个线程安全的List,使用该List时需要在访问它的方法上添加synchronized关键字,以保证多线程访问的安全性。
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
List<String> synchronizedList = Collections.synchronizedList(list);
}
}
- 使用CopyOnWriteArrayList类来代替ArrayList。CopyOnWriteArrayList是一种线程安全的List实现,它通过在写操作时复制整个数组来保证线程安全性,在读操作时不需要加锁,因此可以提高读取效率。
import java.util.concurrent.CopyOnWriteArrayList;
public class Main {
public static void main(String[] args) {
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
}
}
- 使用Lock接口来实现同步。可以使用ReentrantLock类来实现对ArrayList的同步操作,该类提供了与synchronized类似的功能,但是具有更高的灵活性。比如可以使用tryLock()方法来尝试获取锁,避免了线程的长时间等待。
Lock lock = new ReentrantLock();
...
lock.lock();
try {
// 对 ArrayList 的操作
} finally {
lock.unlock();
}
- 使用读写锁来实现同步。可以使用ReentrantReadWriteLock类来实现对ArrayList的读写操作的同步。该类提供了读锁和写锁两种锁,多个线程可以同时获取读锁,但是只有一个线程可以获取写锁,在写操作时需要先获取写锁,以保证线程安全。
ReadWriteLock rwLock = new ReentrantReadWriteLock();
...
rwLock.readLock().lock();
try {
// 对 ArrayList 的读操作
} finally {
rwLock.readLock().unlock();
}
...
rwLock.writeLock().lock();
try {
// 对 ArrayList 的写操作
} finally {
rwLock.writeLock().unlock();
}
- 使用 Vector: Vector 是一个线程安全的类,与 ArrayList 非常相似,可以作为替代品。但是,由于 Vector 的所有方法都是同步的,这可能会导致性能问题。
参考文献:
- https://stackoverflow.com/questions/2444005/how-do-i-make-my-arraylist-thread-safe-another-approach-to-problem-in-java 如何使我的ArrayList线程安全?Java问题的另一种方法?
- https://stackoverflow.com/questions/18983362/how-to-prove-arraylist-is-not-thread-safe-with-a-test 如何用测试证明数组列表不是线程安全的?
- https://stackoverflow.com/questions/300519/arraylist-vs-vectors-in-java-if-thread-safety-isnt-a-concern ArrayList与vector,Java如果线程安全不是一个问题
Java中有哪些常用的容器呢?(2023 阿里)
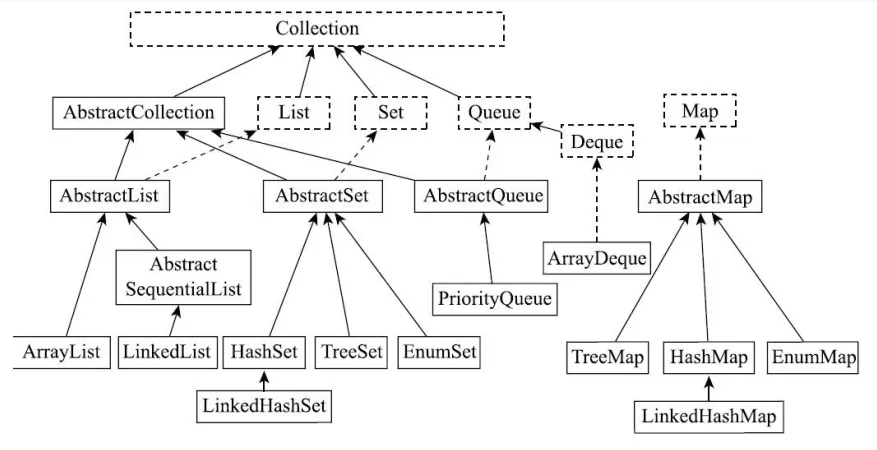
List是有序的Collection,使用此接口能够精确的控制每个元素的插入位置,用户能根据索引访问List中元素。常用的实现List的类有LinkedList,ArrayList,Vector,Stack。
- ArrayList是容量可变的非线程安全列表,其底层使用数组实现。当几何扩容时,会创建更大的数组,并把原数组复制到新数组。ArrayList支持对元素的快速随机访问,但插入与删除速度很慢。
- LinkedList本质是一个双向链表,与ArrayList相比,,其插入和删除速度更快,但随机访问速度更慢。
Set不允许存在重复的元素,与List不同,set中的元素是无序的。常用的实现有HashSet,LinkedHashSet和TreeSet。
- HashSet通过HashMap实现,HashMap的Key即HashSet存储的元素,所有Key都是用相同的Value,一个名为PRESENT的Object类型常量。使用Key保证元素唯一性,但不保证有序性。由于HashSet是HashMap实现的,因此线程不安全。
- LinkedHashSet继承自HashSet,通过LinkedHashMap实现,使用双向链表维护元素插入顺序。
- TreeSet通过TreeMap实现的,添加元素到集合时按照比较规则将其插入合适的位置,保证插入后的集合仍然有序。
Map 是一个键值对集合,存储键、值和之间的映射。Key 无序,唯一;value 不要求有序,允许重复。Map 没有继承于 Collection 接口,从 Map 集合中检索元素时,只要给出键对象,就会返回对应的值对象。主要实现有TreeMap、HashMap、HashTable、LinkedHashMap、ConcurrentHashMap
- HashMap:JDK1.8 之前 HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突),JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间
- LinkedHashMap:LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
- HashTable:数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
- TreeMap:红黑树(自平衡的排序二叉树)
- ConcurrentHashMap:Node数组+链表+红黑树实现,线程安全的(jdk1.8以前Segment锁,1.8以后CAS锁)
HashMap是线程不安全的,那有什么线程安全的办法吗?(2023 阿里)
HashMap不是线程安全的,Hashtable和ConcurrentHashMap 都是线程安全的。
Hashtable和Collections.synchronizedMap返回的装饰器类SynchronizedMap都是通过synchronized关键字来保证多线程操作的线程安全,但使用synchronized会有一个问题,就是锁的粒度太大,同时只能有一个线程进行操作,导致并发度低下,影响了操作的性能。
比如:Hashtable的get和put方法,都使用了关键字synchronized修饰,这就意味着当一个线程调用put方法添加元素时,其它线程不能再同时执行put添加元素,也不能调用get方法获取数据。
为了解决synchronized并发度低的问题,ConcurrentHashMap使用了cas+synchronized解决共享遍历操作原子性问题,使用volatile保障共享变量的内存可见性问题。
ArrayList的并发修改异常了解吗?单线程情况下会发生吗?(2023 小红书)
这种异常通常发生在对ArrayList进行遍历时,同时尝试修改它的结构(例如添加或删除元素)。这种异常被称为ConcurrentModificationException。
在单线程情况下,这种异常也可能发生。当你在使用迭代器遍历ArrayList集合时,如果使用ArrayList的方法(如add()或remove())修改了集合的结构,就可能触发这个异常。这是因为ArrayList的内部实现使用了一个modCount变量来跟踪结构修改的次数。当迭代器检测到modCount发生变化时,它会抛出ConcurrentModificationException异常。
为了避免这种异常,你可以在遍历ArrayList时采用以下方法:
- 使用Iterator的remove()方法来删除元素,而不是直接使用ArrayList的remove()方法。这样可以确保modCount的值在迭代过程中保持一致。
- 如果需要遍历过程中添加元素,可以考虑使用ListIterator,它提供了add()方法,允许在遍历过程中修改列表结构。
- 另一种方法是使用Java 8的Stream API,它提供了一种更安全的方式来处理集合的并发修改问题。
- 如果你确实需要在遍历过程中修改ArrayList,可以考虑先复制一个新的ArrayList,然后在新的ArrayList上进行修改。遍历完成后,再将新的ArrayList赋值给原来的引用。这样可以避免在遍历过程中修改原始ArrayList的结构。
参考:
- https://stackoverflow.com/questions/602636/why-is-a-concurrentmodificationexception-thrown-and-how-to-debug-it 为什么会抛出它会抛出ConcurrentModificationException异常以及如何调试它
- https://www.javatpoint.com/concurrentmodificationexception-in-java
什么情况下会导致并发修改异常?(2023 快手)
在Java集合(如List、Set、Map)被一个线程进行迭代操作时,如果另一个线程同时修改了该集合的结构(如添加或删除元素),就有可能导致ConcurrentModificationException的发生
面向过程的方法存在哪些问题?(2023 美团)
- 可维护性较差:面向过程编程主要依赖于函数和过程,随着代码规模的增大,可能会导致代码结构复杂,不易维护。
- 可复用性较低:面向过程编程难以实现模块化,导致代码难以复用,进一步增加开发时间和成本。
- 扩展性不足:面向过程编程在代码逻辑发生变化时,往往需要对程序进行大量的修改,这样的代码扩展性不足。
- 抽象能力有限:面向过程编程主要关注过程和算法,而不是数据结构和对象,这使得它在表达现实世界的复杂问题时抽象能力有限。
- 封装性差:面向过程编程没有提供良好的封装机制,程序中的数据和处理过程容易暴露,可能导致数据安全性和程序稳定性问题。
- 强耦合:面向过程编程的方法往往导致程序组件之间存在强耦合,当一个组件发生变化时,可能会影响其他组件的正常工作。
面向过程好处是什么?(2023 美团)
- 面向过程编程采用自顶向下的编程方式,将问题分解为一个个小的模块,便于理解和编写。
- 每个模块相对独立,出现问题时可以单独调试,降低了调试难度。
- 面向过程编程适合解决简单、逻辑性强的问题,对于初学者来说,学习成本较低。
object 有哪些方法(2023百度)
当面试官问到 Java 中 Object 类的方法时,如果你无法记住所有的方法,可以采用以下回答策略:
- 强调基本方法:首先提及最常用和最基本的几个方法,如 equals()、hashCode()、toString(),这些方法几乎在每个对象中都会用到。
- equals(Object obj): 检查当前对象是否与另一个对象相等。
- hashCode(): 返回对象的哈希码值。
- toString(): 返回对象的字符串表示。
- 提及重要的方法:接下来可以提及一些较为重要的方法,如 getClass() 用于获取对象的运行时类,clone() 用于创建对象的副本等。
- clone(): 创建并返回当前对象的副本。
- getClass(): 返回对象的运行时类。
- 谈论对象间的通信:强调 wait()、notify()、notifyAll() 这些用于线程间通信的方法,说明其在多线程编程中的作用。
- notify(): 唤醒在该对象上等待的单个线程。
- notifyAll(): 唤醒在该对象上等待的所有线程。
- wait(): 导致当前线程等待,直到另一个线程调用该对象的 notify() 或 notifyAll() 方法。
- 谈论垃圾回收:提及 finalize() 方法,它在对象被垃圾回收之前调用,可以用于执行一些清理操作。
- finalize(): 在对象被垃圾回收器回收之前调用。
如果让你自己实现一个 map 你会怎么做(2023百度)
- 定义Map接口,包括get,put,remove,size,isEmpty等方法
public interface MyMap {
public Object get(Object key);
public void put(Object key, Object value);
public Object remove(Object key);
public int size();
public boolean isEmpty();
}
- 实现HashMap,使用哈希表和链表解决hash冲突
public class MyHashMap implements MyMap {
private int size;
private LinkedList[] buckets;
public MyHashMap() {
buckets = new LinkedList[16];
}
public Object get(Object key) {
int hash = key.hashCode();
int index = hash % buckets.length;
LinkedList list = buckets[index];
if (list != null) {
for (Node node : list) {
if (node.key.equals(key)) {
return node.value;
}
}
}
return null;
}
public void put(Object key, Object value) {
// 省略实现...
}
// 其他方法省略...
}
- 实现TreeMap,使用红黑树排序并存储key-value
public class MyTreeMap implements MyMap {
private Node root;
private class Node {
Object key;
Object value;
Node left;
Node right;
// 省略构造方法...
}
public Object get(Object key) {
Node node = root;
while (node != null) {
if (key.compareTo(node.key) < 0) {
node = node.left;
} else if (key.compareTo(node.key) > 0) {
node = node.right;
} else {
return node.value;
}
}
return null;
}
public void put(Object key, Object value) {
// 省略实现...
}
}
作为 map 的 key 需要重写哪些方法?(2023 完美世界)
首先,先理解面试题的意思,可以理解为:如果你要用自己的类的对象作为Map的键,你需要重写这个类的哪些方法?
- 在Java中,Map接口是基于键值对的,每个键都必须是唯一的。Java使用键对象的hashCode()方法来计算哈希值,这个哈希值用于确定在Map内部存储结构中的位置。同时,Java也使用键对象的equals()方法来检查两个键是否相等。
- 所以,如果你的类的对象要作为Map的键使用,那么通常需要你重写这个类的hashCode()和equals()方法,以确保它们的行为符合预期。
- 如果不重写这两个方法,那么默认的hashCode()方法将返回每个对象的内存地址,equals()方法将仅比较两个对象的内存地址。这可能会导致不符合预期的行为,比如两个内容完全相同但内存地址不同的对象被视为不同的键。
在Java中,作为Map的键(key),你通常需要重写以下两个方法:
- hashCode():这个方法返回对象的哈希码,用于确定在哈希表中的存储位置。如果两个对象被认为相等(根据equals()方法),那么它们的hashCode()方法必须返回相同的值。
- equals():这个方法用来判断两个对象是否相等。在Java的Map中,当我们调用get(key)或containsKey(key)方法时,Map实现会用这个方法来查找与给定键匹配的键。
当你创建自定义的类并打算将其实例用作Map的键时,通常需要覆盖这两个方法以确保它们的行为符合预期。如果不这样做,Map可能无法正确地查找、添加或删除键值对。
List的实现类(2023 阿里)
Java中的List接口有多个实现类,常用的包括:
- ArrayList:基于动态数组实现,优势在于支持随机访问和快速插入/删除元素,适用于频繁读取和遍历的场景。
- LinkedList:基于双向链表实现,优势在于支持快速插入/删除元素,适用于频繁插入/删除元素的场景。
- Vector:和ArrayList类似,但由于其线程安全性,适用于多线程环境。
- Stack:基于Vector实现,是一个后进先出(LIFO)的数据结构,适用于需要按照后进先出顺序处理元素的场景。
List和Set的区别(2023 阿里)
- 顺序:List是有序的集合,它可以按照元素插入的顺序进行存储和访问。而Set是无序的集合,元素在集合中的位置是不固定的。
- 重复元素:List允许存储重复的元素,即可以有多个相同的对象。Set不允许存储重复的元素,即每个对象在集合中只能出现一次。
- 实现类:List的常用实现类有ArrayList和LinkedList,分别使用数组和链表作为底层数据结构。Set的常用实现类有HashSet、LinkedHashSet和TreeSet,分别基于哈希表、链表+哈希表和红黑树实现。
- 性能:由于底层数据结构的差异,List和Set在增加、删除、查找等操作上的性能表现有所不同。例如,ArrayList在随机访问元素时性能较好,而LinkedList在插入和删除元素时性能较好。HashSet在查找、添加和删除元素时性能较好,但不保证元素顺序。TreeSet在保持元素排序的同时,也能提供较好的查找性能。
补充: Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。 Map(用 key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),"x" 代表 key,"y" 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
针对你说的List和Set的性质,那你会用这两种结构解决哪些问题(2023 阿里)
List(列表)适用于以下场景:
- 有序数据:列表中的元素按照插入顺序存储,因此适用于需要保持元素顺序的场景。
- 允许重复元素:列表允许存储重复的元素,因此适用于需要统计元素出现次数的场景。
- 需要根据索引进行查找、插入和删除操作:列表允许通过索引值直接访问、插入或删除元素,适用于需要频繁进行这些操作的场景。
Set(集合)适用于以下场景:
- 去重:集合中的元素不能重复,因此适用于去除数据中重复元素的场景。
- 无需关心元素顺序:集合中的元素没有固定顺序,适用于元素顺序无关紧要的场景。
- 快速判断元素是否存在:集合提供了高效率的查找算法,适用于需要快速判断某个元素是否存在于数据集中的场景。
- 集合运算:集合支持交集、并集、差集等运算,适用于需要进行这些运算的场景。
Java创建对象的几种方式,除了new和反射还有其他吗?(2023 阿里实习)
- 使用 new 关键字: 这是创建对象最常见的方式。例如:
MyClass obj = new MyClass();
- 使用 Java 反射 (Reflection) API,主要是 java.lang.Class 类中的 newInstance() 方法或者 java.lang.reflect.Constructor 类中的 newInstance() 方法。例如:
Class<?> clazz = Class.forName("com.example.MyClass");
MyClass obj = (MyClass) clazz.newInstance();
- 使用 java.lang.Cloneable 接口和 clone() 方法:这种方法用于创建现有对象的复制品。对象需要实现 Cloneable 接口,并重写 clone() 方法。
MyClass obj1 = new MyClass();
MyClass obj2 = (MyClass) obj1.clone();
- 使用 Java 序列化 (java.io.Serializable 接口) 和反序列化:这种方法通常用于创建现有对象的复制品,但它不调用构造器。对象需要实现 Serializable 接口。
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("data.obj"));
out.writeObject(obj1);
out.close();
ObjectInputStream in = new ObjectInputStream(new FileInputStream("data.obj"));
MyClass obj2 = (MyClass) in.readObject();
in.close();
- 使用 java.lang.ClassLoader 或者 java.lang.Class 的 defineClass() 方法:这种方法用于从一个类的二进制名称或者字节码创建一个新的类和对象。
ClassLoader classLoader = MyClass.class.getClassLoader();
Class<?> clazz = classLoader.loadClass("com.example.MyClass");
MyClass obj = (MyClass) clazz.newInstance();
Java9以后推荐的写法是:
ClassLoader classLoader = MyClass.class.getClassLoader();
Class<?> clazz = classLoader.getClass();
MyClass obj = (MyClass)clazz.getDeclaredConstructor().newInstance();
hashmap,为什么要转成红黑树,不是一开始就用?(2023 阿里实习)
在Java中,HashMap使用了链表和红黑树两种数据结构来存储数据。原因是,这两种数据结构在不同的情况下各有优缺点。让我们了解一下HashMap在何时以及为什么会将链表转换为红黑树。
链表
- 优点:相比于红黑树,链表结构更简单,占用空间较少,且在哈希冲突较少的情况下具有良好的性能。
- 缺点:链表在哈希冲突较多的情况下(即链表长度较长时),查找性能会明显下降,因为需要遍历链表。
红黑树
- 优点:红黑树是一种自平衡的二叉查找树,它能保证查找、插入和删除的时间复杂度为O(log n),在哈希冲突较多的情况下性能更优。
- 缺点:相比于链表,红黑树结构更复杂,占用空间较多,且在哈希冲突较少的情况下性能优势不明显。
为了在空间和时间上达到一个平衡,Java的HashMap采用了一种折中的策略。它在初始化时使用链表结构来存储数据,但当链表长度达到一定阈值时(默认为8),会将链表转换为红黑树结构。这样,当哈希冲突较少时,HashMap可以利用链表的空间优势;而在哈希冲突较多时,HashMap则能从红黑树的时间性能上受益。
因此,在Java中,HashMap不是一开始就使用红黑树,而是根据实际情况动态地选择并转换数据结构,以达到最佳性能。
Long 的长度和范围,为什么要减 1 ?(2023 快手)
先来复习一下 Java 中的 8 种基本数据类型:
6 种数字类型:
- 4 种整数型:
byte、short、int、long - 2 种浮点型:
float、double
- 4 种整数型:
1 种字符类型:
char1 种布尔型:
boolean。
这 8 种基本数据类型的默认值以及所占空间的大小如下:
| 基本类型 | 位数 | 字节 | 默认值 | 取值范围 |
|---|---|---|---|---|
byte | 8 | 1 | 0 | -128 ~ 127 |
short | 16 | 2 | 0 | -32768(-2^15) ~ 32767(2^15 - 1) |
int | 32 | 4 | 0 | -2147483648 ~ 2147483647 |
long | 64 | 8 | 0L | -9223372036854775808(-2^63) ~ 9223372036854775807(2^63 -1) |
char | 16 | 2 | 'u0000' | 0 ~ 65535(2^16 - 1) |
float | 32 | 4 | 0f | 1.4E-45 ~ 3.4028235E38 |
double | 64 | 8 | 0d | 4.9E-324 ~ 1.7976931348623157E308 |
boolean | 1 | false | true、false |
可以看到,像 byte、short、int、long能表示的最大正数都减 1 了。这是为什么呢?这是因为在二进制补码表示法中,最高位是用来表示符号的(0 表示正数,1 表示负数),其余位表示数值部分。所以,如果我们要表示最大的正数,我们需要把除了最高位之外的所有位都设为 1。如果我们再加 1,就会导致溢出,变成一个负数。
对于 boolean,官方文档未明确定义,它依赖于 JVM 厂商的具体实现。逻辑上理解是占用 1 位,但是实际中会考虑计算机高效存储因素。
另外,Java 的每种基本类型所占存储空间的大小不会像其他大多数语言那样随机器硬件架构的变化而变化。这种所占存储空间大小的不变性是 Java 程序比用其他大多数语言编写的程序更具可移植性的原因之一(《Java 编程思想》2.2 节有提到)。
JAVA 异常的层次结构(2023 快手)
Java 异常类层次结构图概览:
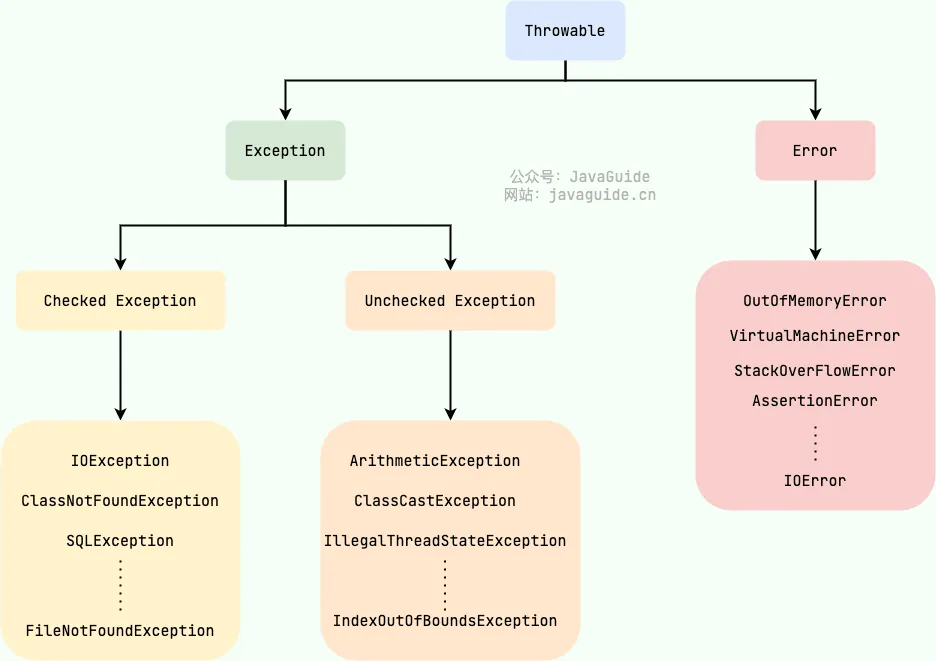
在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable类。Throwable 类有两个重要的子类:
Exception:程序本身可以处理的异常,可以通过catch来进行捕获。Exception又可以分为 Checked Exception (受检查异常,必须处理) 和 Unchecked Exception (不受检查异常,可以不处理)。Error:Error属于程序无法处理的错误 ,我们没办法通过catch来进行捕获不建议通过catch捕获 。例如 Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
JAVA 的集合类有了解么?(2023 快手)
Java 集合, 也叫作容器,主要是由两大接口派生而来:一个是 Collection接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。对于Collection 接口,下面又有三个主要的子接口:List、Set 和 Queue。
Java 集合框架如下图所示:
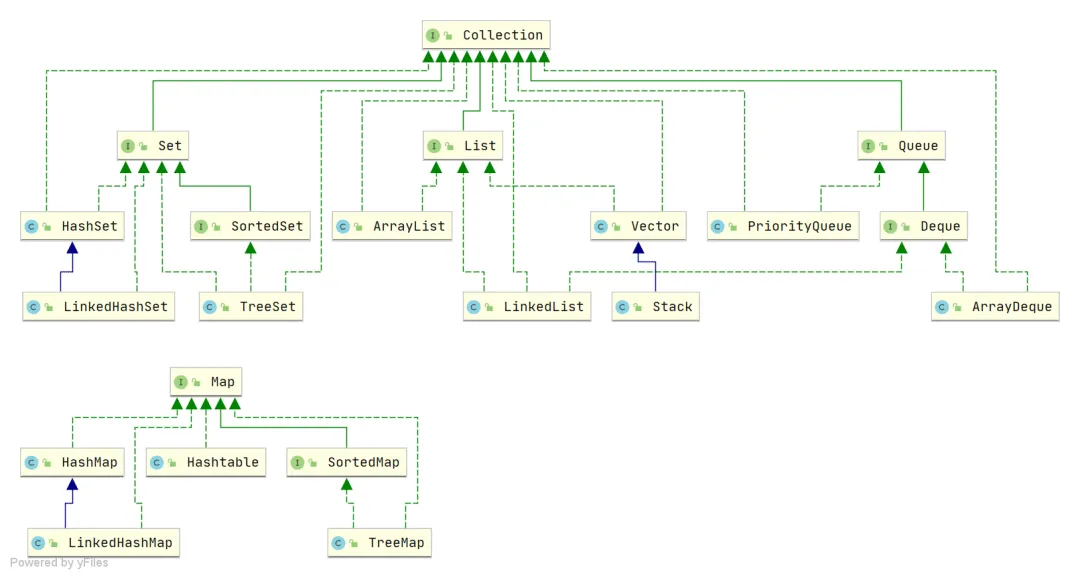
注:图中只列举了主要的继承派生关系,并没有列举所有关系。比方省略了AbstractList, NavigableSet等抽象类以及其他的一些辅助类,如想深入了解,可自行查看源码。
List(对付顺序的好帮手): 存储的元素是有序的、可重复的。Set(注重独一无二的性质): 存储的元素不可重复的。Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。Map(用 key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),"x" 代表 key,"y" 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
try{return “a”} fianlly{return “b”}这条语句返回啥(2023 快手)
finally块中的return语句会覆盖try块中的return返回,因此,该语句将返回"b"。
String s = new String(“abc”)执行过程中分别对应哪些内存区域?(2023 快手)
首先,我们看到这个代码中有一个new关键字,我们知道new指令是创建一个类的实例对象并完成加载初始化的,因此这个字符串对象是在运行期才能确定的,创建的字符串对象是在堆内存上。
其次,在String的构造方法中传递了一个字符串abc,由于这里的abc是被final修饰的属性,所以它是一个字符串常量。在首次构建这个对象时,JVM拿字面量"abc"去字符串常量池试图获取其对应String对象的引用。于是在堆中创建了一个"abc"的String对象,并将其引用保存到字符串常量池中,然后返回;
所以,如果abc这个字符串常量不存在,则创建两个对象,分别是abc这个字符串常量,以及new String这个实例对象。如果abc这字符串常量存在,则只会创建一个对象。
Default修饰符和Proteted修饰符区别(2023 用友)
在Java中,访问修饰符决定了类及其成员的可见性。Java提供了四种访问级别,但在此我们将专注于“默认”(无修饰符)和“protected”修饰符。
默认访问修饰符(没有修饰符):
- 当一个类或其成员没有使用任何访问修饰符,它使用默认访问级别。
- 这被称为“包私有”或“包默认”。
- 在这种情况下,类或成员只能被其所在包内的其他类访问。
- 它们不能被包外的任何类访问。
// 在somepackage包中 class DefaultModifierClass { void defaultMethod() { System.out.println("This is a default method"); } }上述类
DefaultModifierClass及其方法defaultMethod只能在somepackage包中被访问。protected 访问修饰符:
- 当类或其成员使用protected修饰符时,它可以被其所在包中的所有类访问。
- 更重要的是,它还可以被外部包中的子类访问,但只能通过子类对象来访问。
- 不能直接被外部包中的其他类访问。
// 在somepackage包中 public class ProtectedModifierClass { protected void protectedMethod() { System.out.println("This is a protected method"); } }ProtectedModifierClass中的protectedMethod方法可以在somepackage中的任何地方被访问,并且还可以在其他包中的ProtectedModifierClass的子类中被访问。
自定义排序怎么实现?(2023 用友)
在Java中,实现自定义排序可以通过以下几种方法:
- 实现Comparable接口:该接口定义了一个compareTo方法,用于定义对象之间的比较规则。自定义的类需要实现Comparable接口,并在compareTo方法中实现比较逻辑。然后可以使用Arrays.sort()或Collections.sort()进行排序。
- 实现Comparator接口:Comparator接口定义了一个compare方法,用于定义对象之间的比较规则。自定义的类可以创建一个实现Comparator接口的比较器类,在比较器类中实现compare方法。然后可以使用Arrays.sort()或Collections.sort()并传入比较器对象进行排序。
下面是使用实现Comparable接口和Comparator接口的示例代码:
使用实现Comparable接口的方法:
public class Person implements Comparable<Person> {
private String name;
private int age;
// 构造函数和getter/setter方法省略
@Override
public int compareTo(Person other) {
if (this.age == other.age) {
return this.name.compareTo(other.name);
} else {
return Integer.compare(this.age, other.age);
}
}
}
// 使用Arrays.sort()进行排序
Person[] people = new Person[3];
people[0] = new Person("Alice", 23);
people[1] = new Person("Bob", 25);
people[2] = new Person("Charlie", 20);
Arrays.sort(people);
使用实现Comparator接口的方法:
public class PersonAgeComparator implements Comparator<Person> {
@Override
public int compare(Person p1, Person p2) {
return Integer.compare(p1.getAge(), p2.getAge());
}
}
// 使用Collections.sort()进行排序
List<Person> people = new ArrayList<>();
people.add(new Person("Alice", 23));
people.add(new Person("Bob", 25));
people.add(new Person("Charlie", 20));
Collections.sort(people, new PersonAgeComparator());
以上是两种常用的实现自定义排序的方法。通过实现Comparable接口或实现Comparator接口,可以根据自定义的比较规则对对象进行排序。
arraylist的addAll方法,如果容量为1,addAll一个容量为100000的数组,怎么扩容?(2023 用友)
在 Java 的 ArrayList 类中,当你使用 addAll 方法添加一个大量元素的集合时,内部会进行动态数组扩容。这个过程大致可以分为以下几步:
- 检查是否需要扩容:首先,会检查当前的
ArrayList是否有足够的空间来容纳新增的元素。如果没有,就需要进行扩容。 - 计算新的容量:
ArrayList的扩容机制通常是:新的容量 =(旧容量 * 3)/2 + 1。然而,在调用addAll的情况下,如果需要添加的元素数量比这个扩容后的新容量还要大,那么新容量将会设为需要添加的元素数量。 - 分配新数组并复制元素:根据计算出的新容量,会创建一个新的内部数组。然后,旧数组的元素会被复制到这个新数组中。
- 添加新元素:新的元素会被添加到新数组中的适当位置。
假设初始容量为1,然后你使用 addAll 添加一个容量为 100,000 的数组。在这种情况下,ArrayList 会首先计算需要多大的新容量才能存储所有新添加的元素,即最小需要 100,001 的容量。然后,它会创建一个这么大的新数组,并把旧数组和新添加的数组中的元素都复制到这个新数组中。
这样的扩容机制通常是为了优化性能。通过一次性分配一个足够大的数组,ArrayList 减少了多次扩容和数组复制的需要,从而提高了效率。
请注意,扩容操作是有代价的,因为它涉及到数组的复制。因此,在初始化 ArrayList 时,如果你已经知道会存储大量的元素,最好通过构造函数指定一个足够大的初始容量,以减少后续的扩容操作。
枚举类,可以new出来么(2023 用友)
Java枚举类是一种特殊的类,用于定义一组固定的常量。枚举类的实例在定义时就已经固定,无需使用new操作符进行实例化。
枚举类的实例必须放在第一行显示,每个实例都是public static final修饰的,最终以分号结束。在Java中,枚举类的定义方式如下:
public enum DayOfWeek {
SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY
}
在上述代码中,DayOfWeek是一个枚举类,它包含了一周的所有天数。这些枚举实例SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY都是DayOfWeek类的实例,可以通过DayOfWeek.SUNDAY等方式进行访问。
枚举类的实例在编译时即已确定,无法通过new操作符再次实例化。枚举类中的构造函数默认为私有化,不允许被外部调用。
Java抽象类和抽象方法抽象字段之间的因果关系?(2023 用友)
在Java中,抽象类、抽象方法和“抽象字段”之间的关系并不是真正的因果关系,但它们是紧密相关的。首先,我们来澄清各自的定义和概念:
抽象类 (Abstract Class):不能被实例化的类。它可能包含抽象方法和具体方法。它通常作为其他类的基类,并由子类提供实现。创建抽象类的目的是为了提供一个通用的、不能被实例化的基础框架。
public abstract class Animal { // ... 其他代码 }抽象方法 (Abstract Method):在抽象类中声明但没有实现的方法。子类继承抽象类时,必须实现这些抽象方法,除非子类也是抽象类。
public abstract class Animal { public abstract void makeSound(); }Java实际上并没有“抽象字段”的概念。当我们在抽象类中声明字段时,这些字段都是具有实际存储值的字段,即使它们在抽象类中。但是,你可以在抽象类中定义字段并期望子类提供具体的值或使用。
关系总结:
- 一个类如果有一个或多个抽象方法,那么这个类必须被声明为抽象类。
- 抽象类可以没有抽象方法。
- 抽象类不能被实例化,但它可以有构造方法,这通常用于子类调用。
- 抽象方法必须在子类中被实现,除非子类也是一个抽象类。
- 抽象类可以有字段(成员变量),这些字段不是抽象的,并且可以被子类使用或重写。
这种设计使得Java能够强制实现某些方法,而不仅仅是提供一个接口的框架,这为面向对象设计提供了很大的灵活性。
多线程下如何保证HashSet的安全性?(2023 用友)
在Java中,HashSet 是非线程安全的,这意味着如果多个线程同时修改一个HashSet,而没有适当的同步,那么它的行为是不确定的。要在多线程环境中保证 HashSet 的安全性,您可以考虑以下方法:
使用
Collections.synchronizedSet(): Java 的Collections类提供了一个synchronizedSet()方法,可以将给定的集合包装成线程安全的集合。Set<Object> set = Collections.synchronizedSet(new HashSet<>());使用这种方式时,需要注意的是,迭代这个集合仍然需要外部同步,因为可能在迭代期间其他线程进行了修改。例如:
synchronized(set) { for(Object item : set) { // do something } }使用
ConcurrentHashMap为基础的Set:ConcurrentHashMap是一个线程安全的Map实现。虽然它是一个Map,但我们可以使用它来创建一个线程安全的Set:Set<Object> set = Collections.newSetFromMap(new ConcurrentHashMap<>());这样得到的
Set是线程安全的,并且它的并发性能通常比synchronizedSet更好。使用
CopyOnWriteArraySet: 如果你预计集合的写操作相对较少,而读操作非常频繁,那么CopyOnWriteArraySet可能是一个很好的选择。这个集合在每次写操作时都会复制一份数据,从而确保读操作永远不会受到并发修改的干扰。但是,如果写操作非常频繁,性能可能会受到很大的影响。Set<Object> set = new CopyOnWriteArraySet<>();手动同步: 你可以选择为
HashSet操作添加自己的同步机制。但这通常是不推荐的,因为容易出错。
线程池的 BlockingQueue 有什么需要特别注意的(长度溢出相关)?(2023 得物)
Java线程池中的BlockingQueue是一种特殊的队列,它在多线程环境下实现了线程安全和阻塞的功能。在使用Java线程池中的BlockingQueue时,有几点需要特别注意:
- 类型选择:Java线程池提供了不同类型的BlockingQueue,例如ArrayBlockingQueue、LinkedBlockingQueue等,不同的类型适用于不同的场景。需要根据具体需求选择合适的BlockingQueue类型。
- 🌟 容量限制:线程池的BlockingQueue可以设置容量上限,这是为了控制任务的排队和执行。需要根据实际情况合理设置队列的容量,避免任务积压过多或者队列溢出。(高负载情况下,如果队列过长,可能会积累大量的任务,这样会占用大量的内存。设置过大的队列可能会导致内存溢出或者资源过度占用。)
- 阻塞机制:当BlockingQueue已满时,新的任务将被阻塞,直到队列中有空余位置。同样,当BlockingQueue为空时,获取任务的操作也会被阻塞,直到有新任务加入队列。需要注意处理好阻塞机制,避免出现死锁或线程饥饿等问题。
- 内存使用: 高负载情况下,如果队列过长,可能会积累大量的任务,这样会占用大量的内存。
引入专门的监控体系可以帮助你了解队列的使用状态,例如队列长度、处理速度等,这样可以及时进行调整。
ConcurrentHashMap 为什么 key 和 value 不能为 null?(2023 美团)
设计ConcurrentHashMap的作者是这样回答的:The main reason that nulls aren't allowed in ConcurrentMaps (ConcurrentHashMaps, ConcurrentSkipListMaps) is that ambiguities that may be just barely tolerable in non-concurrent maps can't be accommodated. The main one is that if map.get(key) returns null, you can't detect whether the key explicitly maps to null vs the key isn't mapped. In a non-concurrent map, you can check this via map.contains(key), but in a concurrent one, the map might have changed between calls.
主要原因是并发映射(ConcurrentMaps,ConcurrentHashMaps,ConcurrentSkipListMaps)不允许使用null的原因是,在非并发映射中可能勉强可以容忍的歧义无法适应。主要的一个问题是,如果map.get(key)返回null,你无法检测到该键是显式映射到null还是该键未映射(意思是:如果map可以保存null,则无法判断get返回null,是因为该值没有键,还是因为该值为null)。在非并发映射中,您可以通过map.contains(key)来检查此问题,但在并发映射中,调用之间可能会更改映射。
参考:
https://stackoverflow.com/questions/698638/why-does-concurrenthashmap-prevent-null-keys-and-values
如果不理解则进一步解释:当 map.get(key) 返回 null 时,我们不能确定这个 null 是因为键值实际上被映射为 null,还是因为这个键在映射中不存在。在一个非并发的 HashMap 中,你可以通过额外调用 map.contains(key) 来解决这个问题,从而确认这个键是否真的存在于映射中。然而,在并发环境下,这种额外的检查并不可靠,因为映射可能在 get 和 contains 调用之间被其他线程修改。也就是说,即使 contains 返回 true,也没有办法保证键仍然存在于映射中,或者其值没有被改变。这样的不确定性在并发环境中可能导致严重的问题或bug。为了解决这个问题,ConcurrentHashMap 简单地禁止了 null 值,这样 get 方法返回 null 就唯一地表示该键在映射中不存在。这消除了潜在的歧义,并使得代码更容易理解和维护。
HashMap在多线程情况下会产生哪些问题?会产生死锁吗?(2023 得物)
在多线程环境下,HashMap可能会遇到以下几个问题:
- 数据不一致:多个线程同时修改HashMap,可能导致数据状态不一致。
- 死循环:在扩容(rehashing)的过程中,如果两个线程同时尝试对同一个键进行插入,可能会造成链表转为环形,从而导致死循环。
- 结构不一致:一个线程在遍历HashMap的元素时,另一个线程修改了HashMap的结构(比如添加或删除元素),可能会抛出
ConcurrentModificationException。
至于死锁,HashMap本身的操作通常不会导致死锁,因为它不涉及多个资源的锁定。然而,在特定的使用场景或复杂的操作序列中,还是有可能产生死锁,但这通常是由于应用逻辑,而非HashMap本身造成的。如果需要在多线程环境下使用,建议使用线程安全的版本,如ConcurrentHashMap。
对于会变成环状的情况,在Java的HashMap实现中,有一个转移(transfer)的操作,该操作在HashMap扩容时进行。在这个过程中,如果两个线程同时尝试进行这个操作并且没有合适的同步机制,可能会导致链表形成一个环,从而使得HashMap进入一个无限循环状态。
这个问题在JDK 1.7中尤为明显,因为在这个版本中,链表没有优化为红黑树(JDK 1.8之后对这点进行了优化)。
下面的代码段是一个简化示例,并不是实际HashMap源码。但它可以用来说明在不同步的环境下如何可能导致一个循环链表。
class Node {
int key;
int value;
Node next;
Node(int key, int value) {
this.key = key;
this.value = value;
}
}
public class SimpleHashMap {
private Node[] table;
private int size;
public SimpleHashMap(int initialCapacity) {
table = new Node[initialCapacity];
size = 0;
}
public void put(int key, int value) {
if (size >= table.length * 0.75) { // 假设负载因子为0.75
resize();
}
int index = indexFor(key, table.length);
Node newNode = new Node(key, value);
newNode.next = table[index];
table[index] = newNode;
size++;
}
private void resize() {
Node[] newTable = new Node[table.length * 2];
transfer(newTable);
table = newTable;
}
private void transfer(Node[] newTable) {
for (Node node : table) {
if (node != null) {
// 下面的代码只是一个示例,没有考虑所有的细节。
// 如果两个线程同时执行这一段代码,可能会导致链表的环形结构。
int newIndex = indexFor(node.key, newTable.length);
Node newNode = new Node(node.key, node.value);
newNode.next = newTable[newIndex];
newTable[newIndex] = newNode;
}
}
}
private int indexFor(int key, int length) {
return key % length;
}
}
这个简化的HashMap实现在put方法中包含一个resize操作,该操作会在HashMap达到某个负载因子时被触发。
如果两个线程同时执行transfer方法,并且尝试修改相同的链表,由于没有适当的同步,可能会导致这些链表项互相引用,形成一个环。
要注意,这个例子只是为了演示可能的问题,并不是实际的HashMap实现。在实际的JDK实现中,这种问题可能更难以复现,但理论上是可能的。
假设有个hashmap上锁put,get不上锁会有线程安全问题吗?为什么?(2023 快手)
这样的做法会有线程安全问题。当你对HashMap进行put操作上锁,但get操作不上锁时,以下几种情况可能发生:
- 数据不一致:一个线程正在进行put操作,而另一个线程在进行get操作,这可能导致get操作返回一个不一致或者错误的数据。
- 内部结构问题:HashMap在扩容或者重新哈希时,其内部数据结构会发生变化。如果在这一过程中进行get操作,可能会导致不可预料的行为或错误。
- 可见性:如果一个线程修改了一个元素,但这个修改没有被其他线程看到(因为没有适当的内存屏障),那么其他线程获取到的将是一个过期或不正确的值。
🕝 并发编程
Java的线程池有哪些?(2023 阿里)
- ScheduledThreadPool:可以设置定期的执行任务,它支持定时或周期性执行任务,比如每隔 10 秒钟执行一次任务,我通过这个实现类设置定期执行任务的策略。
- FixedThreadPool:它的核心线程数和最大线程数是一样的,所以可以把它看作是固定线程数的线程池,它的特点是线程池中的线程数除了初始阶段需要从 0 开始增加外,之后的线程数量就是固定的,就算任务数超过线程数,线程池也不会再创建更多的线程来处理任务,而是会把超出线程处理能力的任务放到任务队列中进行等待。而且就算任务队列满了,到了本该继续增加线程数的时候,由于它的最大线程数和核心线程数是一样的,所以也无法再增加新的线程了。
- CachedThreadPool:可以称作可缓存线程池,它的特点在于线程数是几乎可以无限增加的(实际最大可以达到 Integer.MAX_VALUE,为 2^31-1,这个数非常大,所以基本不可能达到),而当线程闲置时还可以对线程进行回收。也就是说该线程池的线程数量不是固定不变的,当然它也有一个用于存储提交任务的队列,但这个队列是 SynchronousQueue,队列的容量为0,实际不存储任何任务,它只负责对任务进行中转和传递,所以效率比较高。
- SingleThreadExecutor:它会使用唯一的线程去执行任务,原理和 FixedThreadPool 是一样的,只不过这里线程只有一个,如果线程在执行任务的过程中发生异常,线程池也会重新创建一个线程来执行后续的任务。这种线程池由于只有一个线程,所以非常适合用于所有任务都需要按被提交的顺序依次执行的场景,而前几种线程池不一定能够保障任务的执行顺序等于被提交的顺序,因为它们是多线程并行执行的。
- SingleThreadScheduledExecutor:它实际和 ScheduledThreadPool 线程池非常相似,它只是 ScheduledThreadPool 的一个特例,内部只有一个线程。
线程池队列的底层?(2023 美团)
Java线程池的底层原理主要基于两个核心概念:线程复用和任务队列。
- 线程复用: 创建线程是一个昂贵的操作,线程池通过复用已创建的线程来降低资源消耗。这样,多个任务可以在预先创建的线程上执行,而不需要为每个任务都创建一个新线程。
- 任务队列: 当所有线程都在忙碌状态时,新来的任务会被放入一个队列中,等待线程空闲后再执行。
具体操作流程如下:
- 当一个新任务提交给线程池时,线程池首先会判断是否有空闲线程可用。如果有,直接在空闲线程上执行该任务。
- 如果没有空闲线程,但是线程池的线程数还未达到最大值,那么线程池会创建一个新线程来执行该任务。
- 如果所有线程都在忙碌状态,并且线程数已达最大值,该任务就会被放入任务队列。
- 线程池里的线程完成任务后会检查任务队列,看是否有等待的任务。如果有,它们会从队列中取出任务并执行。
- 在一些配置下,如果线程长时间处于空闲状态,它可能会被终止,以释放资源。
这样,线程池既可以复用线程,减少创建和销毁线程的开销,也能有效地管理和调度任务。常用的Java线程池实现有ExecutorService接口和其实现类,如ThreadPoolExecutor和ScheduledThreadPoolExecutor。
线程池的队列又分哪几种呢?(2023 美团)
首先看一下线程池参数:
public ThreadPoolExecutor(int corePoolSize, //线程池的核心线程数量
int maximumPoolSize, //线程池的最大线程数
long keepAliveTime, //当线程数大于核心线程数时,多余的空闲线程存活的最长时间
TimeUnit unit, //时间单位
BlockingQueue<Runnable> workQueue, //任务队列,用来储存等待执行任务的队列
ThreadFactory threadFactory, //线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler //拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
)
探究的就是BlockingQueue<Runnable> workQueue类型:
- ArrayBlockingQueue: 基于数组结构的有界阻塞队列,需要预先设定其容量。
- LinkedBlockingQueue: 基于链表结构的阻塞队列,可以是有界的,也可以是无界的(理论上,直到内存耗尽)。
- PriorityBlockingQueue: 一个具有优先级的无界阻塞队列。
- SynchronousQueue: 一个没有存储空间的阻塞队列,每个插入操作必须等待一个相应的删除操作。
- DelayedQueue: 一个阻塞队列,只有当任务到达指定的延迟时间时才能从队列中提取。
不同类型的队列有各自的适用场景和优缺点。例如,ArrayBlockingQueue和LinkedBlockingQueue通常用于存储大量的任务,而SynchronousQueue通常用于直接将任务传递给工作线程。
线程池的拒绝策略能自定义拒绝策略吗?(2023 阿里)
Java线程池拒绝策略是可以自定义的。你可以使用RejecttedExecutionHandler接口来定义你自己的拒绝策略。该接口只有一个方法拒绝执行(Runnable r,ThreadPoolExecator执行器),当执行器无法执行任务时调用。你可以实现这个方法来定义你自己的拒绝策略。
示例:
public class CustomRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// Your custom rejection policy here
}
}
ThreadPoolExecutor executor = new ThreadPoolExecutor(
corePoolSize,
maxPoolSize,
keepAliveTime,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(),
new CustomRejectedExecutionHandler()
);
线程池配置无界队列了之后,拒绝策略怎么搞,什么时候用到无界对列?(2023 快手)
线程池配置无界队列了之后,拒绝策略其实就失去了意义,因为无论有多少任务提交到线程池,都会被放入队列中等待执行,不会触发拒绝策略。不过,这样可能堆积大量的请求,从而导致 OOM。因此,一般不推荐使用误解队列。
假设不是无界队列的话,如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,ThreadPoolTaskExecutor 定义一些拒绝策略:
ThreadPoolExecutor.AbortPolicy:抛出RejectedExecutionException来拒绝新任务的处理。ThreadPoolExecutor.CallerRunsPolicy:调用执行自己的线程运行任务,也就是直接在调用execute方法的线程中运行(run)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。ThreadPoolExecutor.DiscardPolicy:不处理新任务,直接丢弃掉。ThreadPoolExecutor.DiscardOldestPolicy:此策略将丢弃最早的未处理的任务请求。
举个例子:
Spring 通过 ThreadPoolTaskExecutor 或者我们直接通过 ThreadPoolExecutor 的构造函数创建线程池的时候,当我们不指定 RejectedExecutionHandler 饱和策略的话来配置线程池的时候默认使用的是 ThreadPoolExecutor.AbortPolicy。在默认情况下,ThreadPoolExecutor 将抛出 RejectedExecutionException 来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。对于可伸缩的应用程序,建议使用 ThreadPoolExecutor.CallerRunsPolicy。当最大池被填满时,此策略为我们提供可伸缩队列(这个直接查看 ThreadPoolExecutor 的构造函数源码就可以看出,比较简单的原因,这里就不贴代码了)。
使用多线程要注意哪些问题?(2023 美团)
使用多线程时需要注意以下问题:
- 线程安全:当多个线程同时访问某一数据时,如果不进行正确的同步控制,可能会导致数据的不一致。需要通过使用synchronized,Lock,volatile等机制来保证线程安全。
- 死锁:死锁是指两个或两个以上的线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力干涉那他们都将无法推进下去。我们应避免在代码中产生死锁。
- 活锁:活锁指的是线程虽然没有被阻塞,但是由于某种条件没有被满足,始终无法向前执行,就像在原地踏步。
- 饥饿:由于线程的优先级设置不合理或者锁机制不公平,导致某些线程始终无法获取到CPU资源或者锁资源,从而无法进行工作。
- 资源消耗:每个线程都会占用一定的内存资源,过多的线程可能会导致系统资源消耗过大。同时,线程上下文切换也会消耗CPU资源,过多的线程也可能会导致CPU负载过大。
- 数据共享和可见性:多线程之间共享数据,需要保证一个线程对数据的修改对其他线程可见,可以使用volatile或者Atomic类来保证。
- 线程的生命周期管理:需要合理的创建、启动、暂停、恢复、终止线程,不合理的管理可能会导致程序错误或者资源泄漏。
- 线程异常处理:线程中的未捕获异常会导致线程终止,而且这个异常不能被外部捕获。需要为线程设置UncaughtExceptionHandler来处理未捕获的异常。
保证数据的一致性有哪些方案呢?(2023 美团)
在Java中,有多种方式可以保证数据的一致性:
- 同步语句块(Synchronized Blocks):在Java中,你可以使用synchronized关键字对一个对象或者方法进行锁定,来保证在一个时刻只有一个线程可以访问该对象或者方法,从而避免数据的不一致。
- Volatile关键字:volatile关键字可以保证变量的可见性。当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去主存中读取新值。
- 原子类(Atomic Classes):Java提供了一组原子类(如AtomicInteger、AtomicLong等),它们使用了高效的机器级指令来保证原子性操作,从而避免了复杂的同步。
- Lock接口和相关类:Java并发库提供了显式的锁机制,包括ReentrantLock、ReadWriteLock等,可以提供比synchronized更灵活的锁定机制。
- 并发集合(Concurrent Collections):Java提供了一组并发集合类(如ConcurrentHashMap、CopyOnWriteArrayList等),它们内部已经实现了并发控制,可以在并发环境中安全使用。
- 事务(Transactions):在数据库和某些支持事务的系统中,可以通过事务来保证数据的一致性。Java中的JPA和Spring等框架提供了对事务的支持。
以上就是在Java中保证数据一致性的一些常用方案,选择哪种方案取决于具体的应用场景和需求。
怎么获取子线程的返回值?(2023 阿里实习)
在Java中,若要获取子线程的返回值,可以使用Callable接口和Future类。Callable接口允许你定义一个返回值的任务,而Future类则代表这个任务的结果。为了获取子线程的返回值,首先创建一个实现Callable接口的类,并重写call()方法。然后,将这个Callable对象提交给ExecutorService,它会返回一个Future对象。通过调用Future对象的get()方法,主线程可以等待并获取子线程的返回值。
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class Main {
public static void main(String[] args) {
ExecutorService executor = Executors.newSingleThreadExecutor();
Callable<Integer> task = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
// 这里写你的子线程逻辑,并返回结果
int result = 0;
for (int i = 1; i <= 10; i++) {
result += i;
}
return result;
}
};
Future<Integer> future = executor.submit(task);
try {
// 主线程等待并获取子线程的返回值
Integer result = future.get();
System.out.println("子线程的返回值: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} finally {
executor.shutdown();
}
}
}
子线程抛异常,主线程 try-catch 是否可以获取到异常?(2023 阿里实习)
答案:可以。
当使用 Callable 和 Future 时,如果子线程在执行过程中抛出异常,主线程可以通过调用 Future.get() 方法时捕获异常来获取它。Future.get() 方法可以抛出一个 ExecutionException,这个异常包装了子线程抛出的真实异常。要获取子线程的异常,你可以在主线程的 try-catch 语句中捕获 ExecutionException,然后调用 getCause() 方法来获取子线程的异常。
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class Main {
public static void main(String[] args) {
ExecutorService executor = Executors.newSingleThreadExecutor();
Callable<Integer> task = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
// 这里故意抛出一个异常
throw new RuntimeException("子线程抛出异常");
}
};
Future<Integer> future = executor.submit(task);
try {
// 主线程等待并获取子线程的返回值
Integer result = future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
// 获取并处理子线程抛出的异常
Throwable cause = e.getCause();
System.out.println("子线程抛出的异常: " + cause.getMessage());
} finally {
executor.shutdown();
}
}
}
AtomicInteger是怎么更新保证原子性的?(2023 小红书)
AtomicInteger 是 Java 并发包 java.util.concurrent.atomic 中的一个类,它用于执行原子操作。原子操作是一种不可中断的操作,无论在任何情况下,只要这个操作开始,就会运行到结束,不会出现中间态。这是一种避免多线程并发问题的常用手段。
AtomicInteger 在内部通过很低级的原子硬件指令直接支持原子性。主要使用了一种名为“Compare and Swap”(CAS,比较并交换)的算法来实现原子性。这种算法使用三个参数:一个内存位置 V、预期的原始值 A 和新值 B。该算法仅当内存位置 V 的当前值与预期的原始值 A 相匹配时,才会将内存位置 V 的值更新为新值 B。如果内存位置 V 的当前值与预期值 A 不匹配,那么操作会失败,通常这个操作会在一个循环中进行,直到操作成功。
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
AtomicInteger 的源码中,使用 Unsafe 类的 CAS 操作来实现:
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
unsafe.getAndAddInt() 方法实现了 CAS,它会获取当前值,加 1,并比较当前值是否改变,如果没有改变则更新,否则重新获取值。
所以 AtomicInteger 通过 CAS 无锁操作实现了线程安全的递增操作。
Future抛出的两个异常的对比,都有什么用?(2023 百度提前批)
在Java中,Future接口在其方法执行过程中可能会抛出以下异常:
InterruptedException:当线程在等待、睡眠或其他占用时间的操作中被中断时可能会抛出此异常。例如,
Future.get()方法会在等待计算完成时抛出此异常,如果线程在等待过程中被中断。Future<Integer> future = executor.submit(callable); try { Integer result = future.get(); } catch (InterruptedException e) { // handle exception }ExecutionException:如果
Future的计算抛出异常,那么Future.get()方法会抛出这个异常。这个异常的原因可以通过ExecutionException.getCause()获得。Future<Integer> future = executor.submit(callable); try { Integer result = future.get(); } catch (ExecutionException e) { Throwable cause = e.getCause(); // handle exception }TimeoutException:当
Future.get(long timeout, TimeUnit unit)在超时时间内没有得到结果时,会抛出此异常。Future<Integer> future = executor.submit(callable); try { Integer result = future.get(5, TimeUnit.SECONDS); } catch (TimeoutException e) { // handle exception }CancellationException:当尝试取回已经取消的任务的结果时,会抛出此异常。
Future<Integer> future = executor.submit(callable); future.cancel(true); try { Integer result = future.get(); } catch (CancellationException e) { // handle exception }
请注意,这些异常都必须被捕获和处理,因为它们都是java.lang.Exception的子类,是已检查的异常。
参考:
- https://stackoverflow.com/questions/2665569/in-what-cases-does-future-get-throw-executionexception-or-interruptedexception 在什么情况下Future. get()抛出ExecutionException或InterruptedException
- https://stackoverflow.com/questions/2248131/handling-exceptions-from-java-executorservice-tasks 处理ExecutorService任务Java异常
- https://www.baeldung.com/java-future
- https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/Future.html
线程池任务提交,比如调用execute或submit API之后的流程有了解吗?(2023 影石360)
在Java中,线程池是一个在后台运行的线程集合,可以用来执行并发任务。当我们在线程池中调用execute或submit方法时,线程池会处理任务的调度和执行。以下是一个简要的流程描述:
- 任务提交:当一个新任务通过
execute()或submit()方法提交到线程池时,线程池首先会判断当前活跃的线程数量是否小于corePoolSize(核心线程数)。 - 任务分配:
- 如果小于
corePoolSize,线程池会创建一个新的线程来执行这个任务,即使其他线程是空闲的。 - 如果大于或等于
corePoolSize,线程池会尝试将任务添加到工作队列(workQueue)。 - 如果工作队列已满,且活跃线程数量小于
maximumPoolSize(最大线程数),线程池会创建一个新的线程来处理这个任务。 - 如果工作队列已满,且活跃线程数量等于
maximumPoolSize,线程池会根据其饱和策略(RejectedExecutionHandler)来处理这个任务。
- 如果小于
- 任务执行:线程池中的线程从工作队列中取出任务并执行。如果线程在执行任务时发生异常,将会被线程池捕获,并根据具体的情况决定是否需要替换这个线程。
- 任务完成:当一个任务完成时,线程会返回到线程池并保持空闲状态,等待下一个任务的分配。
请注意,execute()方法和submit()方法有一些区别:
execute()方法用于提交没有返回值的任务,所以它不会返回任何东西。submit()方法用于提交需要返回值的任务。它返回一个Future对象,通过这个Future对象可以获取任务的结果。
AQS队列中的任务怎么知道锁被释放了?(2023 美团)
AQS 使用一个 int 成员变量来表示同步状态,并基于一个 FIFO 队列来管理那些尝试获取资源但失败的线程。
当线程尝试获取资源但失败时,它会被包装成一个节点(Node)并加入到 AQS 的等待队列中。每个节点包含一个指向前一个节点的链接(prev)和一个指向后一个节点的链接(next),这形成了一个双向链表。
那么,一个节点(线程)如何知道锁已经被释放了呢?这主要是通过以下方式来实现的:
- 状态变量:AQS 中的状态变量是一个核心组件。当一个线程释放锁时,它会尝试将状态变量设为 0 或相应的值。任何尝试获取锁的线程都会首先检查这个状态变量。
- 前驱节点:当一个线程尝试获取锁并失败时,它会被放到等待队列中,并且通常会进入休眠模式。当它前面的节点(它的前驱)成功获取并随后释放锁时,这个节点的线程会被唤醒。这是通过前驱节点直接唤醒其后继节点的线程来实现的。
- LockSupport:AQS 使用
LockSupport.park()和LockSupport.unpark(thread)方法来挂起和唤醒线程。当一个线程不能获取锁时,它会被挂起(即调用LockSupport.park())。当锁被释放时,相应的线程(通常是等待队列中的头部线程)会被唤醒,即调用LockSupport.unpark(thread)。
综上所述,当锁被释放时,正在等待的线程知晓这个变化是通过检查状态变量、前驱节点的通知,以及 LockSupport 的挂起/唤醒机制来实现的。
🍃 常用框架
MyBatis运用了哪些常见的设计模式?(2023 美团)
- 工厂模式,工厂模式在 MyBatis 中的典型代表是 SqlSessionFactory
- 建造者模式,建造者模式在 MyBatis 中的典型代表是 SqlSessionFactoryBuilder
- 单例模式,单例模式在 MyBatis 中的典型代表是 ErrorContext
- 适配器模式,适配器模式在 MyBatis 中的典型代表是 Log
- 代理模式,代理模式在 MyBatis 中的典型代表是 MapperProxyFactory
- 模板方法模式,模板方法在 MyBatis 中的典型代表是 BaseExecutor
- 装饰器模式,装饰器模式在 MyBatis 中的典型代表是 Cache
- 迭代器模式,如迭代器模式Properties tyTokenizer;
- 组合模式,如SqlNode和每个子类ChooseSqlNode;
参考文献:
- https://programming.vip/docs/6200e8e7b682c.html 【Mybatis源码解析】Mybatis源码涉及的设计模式总结
- https://programming.vip/docs/mybatis-design-pattern.html Mybatis设计模式
MyBatis中创建了一个Mapper接口,在写一个xml文件,java的接口是要实现的,为什么这没有实现呢?(2023 美团)
MyBatis中的Mapper接口并不需要实现,它只是定义了一组方法签名。MyBatis会根据Mapper接口中的方法名、参数类型和返回值类型,自动生成实现方法。因此,Mapper接口中的方法不需要实现,也不需要在该接口中编写任何方法体。
相反,你需要编写一个与Mapper接口同名的XML文件,来实现这些方法的具体SQL操作。这样,当你在Java代码中调用Mapper接口中的方法时,MyBatis会自动将该方法映射到对应的XML文件中的SQL语句,并执行该语句。
与传统的JDBC相比,MyBatis的优点?(2023 美团)
在面试中,可以按照以下的方式来回答:
- 首先,我认为最大的优点是MyBatis提供了更高的灵活性。我们可以直接编写SQL,这样可以充分利用数据库的特性并且更好地控制查询。
- 其次,MyBatis使我们无需手动转换数据,它能自动将结果集映射到Java对象,这大大简化了编程工作。
- 此外,MyBatis支持动态SQL,我们可以在SQL语句中使用动态元素,如if、choose等,从而能够创建更复杂的查询。
- 除此之外,MyBatis将SQL语句放在XML文件或注解中,实现了SQL与Java代码的分离,这使得代码更加易于维护。
- MyBatis也能更好地处理一对多、多对多等复杂关系。
- 最后,MyBatis提供了一些JDBC无法提供的特性,如延迟加载,这对于性能优化是非常有用的。
JDBC连接数据库的步骤(2023 美团)
- 加载数据库驱动程序:首先,我们需要加载数据库驱动。这可以通过 Class.forName() 方法实现,例如 Class.forName("com.mysql.jdbc.Driver")。
- 建立数据库连接:使用DriverManager.getConnection()方法建立与数据库的连接,需要指定数据库的URL、用户名和密码,例如:Connection conn = DriverManager.getConnection("jdbc:mysql://localhost/mydatabase", "username", "password");
- 创建Statement对象:使用Connection对象的createStatement()方法创建一个Statement对象,用于执行SQL语句,例如:Statement stmt = conn.createStatement();
- 执行SQL语句:使用Statement对象的executeQuery()或executeUpdate()方法执行SQL语句,例如:ResultSet rs = stmt.executeQuery("SELECT * FROM mytable");
- 处理查询结果:如果执行的是查询语句,需要使用ResultSet对象来处理查询结果,例如:while (rs.next())
- 关闭数据库连接:在程序结束时,需要使用Connection对象的close()方法关闭数据库连接,例如:conn.close();
怎么理解SpringIoc?(2023 美团)
IoC(Inversion of Control)是“控制反转” 的缩写,是一种设计思想,也是Spring框架的核心。IoC是将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。如何理解好IoC呢?可以从以下几点来看:
- 控制反转:传统的程序是由我们自己在对象内部通过new进行创建对象,是由程序控制对象的创建。在Spring框架中,对象的创建是由Spring容器来进行的,它负责控制对象的生命周期。所谓“控制反转”就是把传统的有我们自己控制的对象创建过程交给Spring框架来做。
- 依赖注入:IoC的一个重要的具体实现方法是DI(Dependency Injection),也叫作依赖注入。在我们设计好的对象中会有一些其他对象的引用(即依赖),如果没有Spring容器,我们需要使用很多复杂的方法来管理这些依赖。而有了Spring容器,我们只需要告诉Spring这些依赖即可,Spring会自动把这些依赖注入到对象中。
- 容器:在Spring的IoC下,Spring容器是一个非常重要的角色,它包含并管理了应用中定义的各种组件,负责实例化、配置、装配对象,管理对象的整个生命周期。
- 减轻耦合:通过IoC,对象间的耦合度可以降低,对象只需要关注自身的业务逻辑,而不需要关心其他对象是如何创建和管理的,大大增强了代码的可维护性和可测试性。
- 提供配置:Spring容器可以使用XML、Java注解、Java代码等多种方式来进行配置,提供了非常大的灵活性。
如果让你设计一个SpringIoc,你觉得会从哪些方面考虑这个设计?(2023 美团)
- Bean的生命周期管理:需要设计Bean的创建、初始化、销毁等生命周期管理机制,可以考虑使用工厂模式和单例模式来实现。
- 依赖注入:需要实现依赖注入的功能,包括属性注入、构造函数注入、方法注入等,可以考虑使用反射机制和XML配置文件来实现。
- Bean的作用域:需要支持多种Bean作用域,比如单例、原型、会话、请求等,可以考虑使用Map来存储不同作用域的Bean实例。
- AOP功能的支持:需要支持AOP功能,可以考虑使用动态代理机制和切面编程来实现。
- 异常处理:需要考虑异常处理机制,包括Bean创建异常、依赖注入异常等,可以考虑使用try-catch机制来处理异常。
- 配置文件加载:需要支持从不同的配置文件中加载Bean的相关信息,可以考虑使用XML、注解或者Java配置类来实现。
Spring给我们提供了很多扩展点,这些有了解吗?(2023 美团)
- BeanFactoryPostProcessor:允许在Spring容器实例化bean之前修改bean的定义。常用于修改bean属性或改变bean的作用域。
- BeanPostProcessor:可以在bean实例化、配置以及初始化之后对其进行额外处理。常用于代理bean、修改bean属性等。
- PropertySource:用于定义不同的属性源,如文件、数据库等,以便在Spring应用中使用。
- ImportSelector和ImportBeanDefinitionRegistrar:用于根据条件动态注册bean定义,实现配置类的模块化。
- Spring MVC中的HandlerInterceptor:用于拦截处理请求,可以在请求处理前、处理中和处理后执行特定逻辑。
- Spring MVC中的ControllerAdvice:用于全局处理控制器的异常、数据绑定和数据校验。
- Spring Boot的自动配置:通过创建自定义的自动配置类,可以实现对框架和第三方库的自动配置。
- 自定义注解:创建自定义注解,用于实现特定功能或约定,如权限控制、日志记录等。
大致了解SpringMVC的处理流程吗?(2023 美团)
- 接收请求:用户发送请求至前端控制器DispatcherServlet。
- 查找处理器映射:DispatcherServlet收到请求后,调用HandlerMapping处理器映射器。
- 处理器映射返回处理器执行链:HandlerMapping根据请求的URL找到对应的Controller并返回一个HandlerExecutionChain对象(包含一个Handler处理器(页面控制器)对象,多个HandlerInterceptor拦截器对象)。
- 调用处理器适配器:DispatcherServlet通过HandlerAdapter进行多类型的页面控制器的适配,调用对应的Controller(处理器)。
- Controller执行业务逻辑:Controller开始执行页面控制器的处理方法,并返回一个ModelAndView对象(模型和视图)。
- 视图解析:DispatcherServlet通过视图解析器进行解析(根据逻辑视图名解析成实际视图/页面),并将ModelAndView对象中的模型数据填充到request域对象中。
- 返回视图:DispatcherServlet把返回的视图对象返回给用户。
SpringAOP主要想解决什么问题(2023 美团)
- 代码分离:在许多应用程序中,你可能会发现你需要在多个方法或对象中重复相同的代码块,比如日志记录、事务管理、权限检查等。这种情况下,代码不是真正的分离,各部分功能模块的职责并不清晰。通过使用AOP,你可以把这些代码集中在一起,然后应用到程序的其他部分,实现"横切关注点"(cross-cutting concerns)的有效管理。
- 维护性:如果你需要修改一些重复的代码(比如更改日志记录的格式),你可能需要在多个位置进行更改。使用AOP,你只需要在一个地方更改,减少了出错的可能性,提高了代码的维护性。
- 可读性:AOP可以使得代码的可读性增强。因为重复的、固定的代码被分离出来,业务代码更加清晰,易于理解。
- 可重用性:由于AOP能将横切关注点抽象成独立的模块,这些模块可以在多个应用中重用。
总的来说,Spring AOP能够让开发者更好地关注业务逻辑的开发,而将诸如日志记录、安全控制、事务处理等公共任务抽象和集中处理,从而提高代码的可维护性、可读性和可重用性。
🔥 SpringAOP的原理了解吗(2023 美团、2023 完美世界、2023 影石360、2023 快手)
序言
面向切面编程(AOP)是一种编程范式,它允许开发人员定义跨多个方法和类的关注点。AOP 的主要目的是将程序中分散的功能(例如日志、安全等)模块化,并能够在不修改核心业务逻辑代码的情况下,将这些功能插入到程序的不同部分。
核心概念和原则
- 切面(Aspect): 切面是一个模块,其中定义了一个或多个“关注点”或“交叉关注点”。简单来说,它是我们想要实现的功能或行为。例如,日志记录、事务管理和安全性都可以是切面。
- 连接点(Join Point): 连接点是程序中的某个特定位置,如方法执行、异常处理等,我们可以在这些位置插入切面的代码。在Spring AOP中,连接点主要是指方法执行。
- 通知(Advice): 通知是切面在特定的连接点执行的代码片段。Spring AOP包括以下五种类型的通知:
- 前置通知(Before advice): 在连接点之前执行。
- 后置通知(After returning advice): 在连接点成功执行后执行。
- 异常通知(After throwing advice): 如果在连接点抛出异常,则执行。
- 最终通知(After (finally) advice): 在连接点执行后,无论成功还是异常都会执行。
- 环绕通知(Around advice): 在连接点前后都可以执行。
- 切点(Pointcut): 切点是一组表达式,用于指定哪些连接点需要被通知。它告诉AOP框架在何处应用通知。
- 目标对象(Target Object): 目标对象是包含连接点的对象。Spring AOP代理的目标对象通常是一个被代理的对象。
- 代理(Proxy): AOP代理是用于实现切面的对象。在Spring中,AOP代理可以是JDK动态代理或CGLIB代理。
- 织入(Weaving): 织入是将切面插入到目标对象中以创建代理对象的过程。这可以在编译时、加载时或运行时完成。
步骤
- 定义切面: 创建一个类,并在该类中定义需要注入的关注点。
- 定义通知: 在切面类中,定义一些方法,并使用Spring AOP的注解来标注这些方法是哪种类型的通知。
- 定义切点: 使用
@Pointcut注解定义表达式,指定在哪些方法上应用通知。 - 应用切面: 使用Spring的配置(XML或Java)来启用AOP并应用切面。
总的来说,Spring AOP提供了一种强大而灵活的方式来增加关注点或行为,而无需修改原始代码。这大大简化了例如日志记录、事务管理和安全性等交叉关注点的实现。希望这个解释有助于您了解Spring AOP的基本原则!如果您有进一步的问题或需要详细的示例,请告诉我!
面试的时候可以这样回答: 🙋♂️ "Spring AOP 是一种面向切面编程的实现,它通过动态代理方式解耦了业务逻辑和系统服务。其主要组成部分包括 JoinPoint(程序执行过程中的某个特定点,如方法调用),PointCut(一组可以通过表达式或规则定义的 JoinPoint),Advice(在特定的 JoinPoint 执行的代码),和 Aspect(包含 Advice 和 PointCut 的模块)。 Spring AOP 根据目标对象是否实现接口来选择使用 JDK 动态代理还是 CGLIB 代理。如果目标对象实现了接口,Spring AOP 就会用 JDK 动态代理,否则会用 CGLIB 代理。这样,在运行时,Spring AOP 可以动态地将 Advice 应用到目标对象,实现系统服务和业务逻辑的解耦。 通过这种方式,我们可以将一些通用的系统服务(比如事务管理、日志、安全等)抽象出来,从而使业务代码更简洁、更易于维护和复用。"
拦截器有几个方法,分别在什么时候执行,对比过滤器(2023 完美世界)
拦截器和过滤器是Web开发中常用的两种处理方法。这里我假设你指的是Spring MVC拦截器和Java Servlet过滤器。 拦截器 (Interceptor) 在Spring MVC中通常有3个方法:
preHandle(HttpServletRequest request, HttpServletResponse response, Object handler): 在请求被处理之前调用。如果返回true,处理流程继续;如果返回false,处理流程结束,不会调用后续的拦截器和处理器。postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView): 在请求被处理之后,视图被渲染之前调用。可以通过它来修改数据模型和视图或进行其他处理。afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex): 在请求处理完毕后(视图渲染后)调用,通常用于进行资源清理等工作。
过滤器 (Filter) 在Java Servlet API中通常有三个方法:
- init(FilterConfig filterConfig): 在服务器启动时,创建Filter对象时调用。
- doFilter(ServletRequest request, ServletResponse response, FilterChain chain): 每次在过滤请求时调用。可以进行逻辑处理,然后使用chain.doFilter(request, response);将请求传递到链中的下一个过滤器或资源(servlet或静态内容)。
- destroy(): 在服务器关闭时,销毁Filter对象时调用。
比较:
- 相较于过滤器,拦截器更加灵活和强大。拦截器是基于Java的反射机制的,它在运行时动态地将逻辑插入到方法调用中,而不需要改变源码。此外,拦截器可以获得Spring容器中的各种bean,从而有更多的操作。
- 过滤器则主要用于请求的过滤处理,包括日志记录、请求压缩、安全检查、用户登录校验等。它的运行速度一般比拦截器快,但功能上不如拦截器强大。
导入一个 jar 包怎么让 springboot 知道哪些需要自动配置(2023 完美世界)
Spring Boot自动配置是通过@EnableAutoConfiguration注解实现的。它基本上是通过查找并加载META-INF/spring.factories配置文件来完成的。 如果你想要将你的jar包在Spring Boot项目中进行自动配置,你需要以下步骤:
- 在你的jar包中创建一个spring.factories文件,并将其放入META-INF目录下
- 在spring.factories文件中添加你的自动配置类,格式如下
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.yourpackage.YourAutoConfigurationClass
- 确保你的AutoConfiguration类使用了@Configuration,并在需要的bean上使用了@Bean注解。
这样,当Spring Boot项目启动时,它会读取META-INF/spring.factories文件,并自动配置那些bean。
请注意,你的AutoConfiguration类应该尽可能的"幂等",意味着多次运行结果应该是一致的,并且应该对已有的Bean有所尊重,如果容器中已经存在了你要创建的Bean,你应该避免再次创建。
另外,你可能需要使用@Conditional注解以避免在不需要的情况下创建bean。
Spring IOC 中的 FactoryBean和BeanFactory?(2023 京东)
BeanFactory
- 职责:
BeanFactory是 Spring 的核心接口,负责管理容器中的 Bean。它维护着 Bean 的定义以及依赖关系,还负责创建和装配 Bean。 - 生命周期:
BeanFactory负责整个 Bean 的生命周期,包括 Bean 的创建、初始化、依赖注入、销毁等。 - 配置:通常来说,我们很少直接使用
BeanFactory,更多情况下我们使用的是ApplicationContext,这是一个更高级的容器,也是BeanFactory的一个子接口。 - 使用场景:通常在小型应用或者资源受限的环境下,我们可能会直接使用
BeanFactory。
FactoryBean
- 职责:
FactoryBean是一个特殊的 Bean,用于生成其他 Bean 实例。通常当创建某个 Bean 需要复杂的初始化逻辑时,会使用FactoryBean。 - 生命周期:
FactoryBean自身也是一个 Bean,因此它也是由BeanFactory管理的。当其他 Bean 依赖于由FactoryBean创建的 Bean 时,FactoryBean.getObject()方法会被调用,用于生成那个 Bean。 - 配置:
FactoryBean通常在 Spring 配置文件中定义,就像其他普通的 Bean 一样。 - 使用场景:
FactoryBean在 Spring 框架自身和第三方库中被广泛使用,用于生成如JdbcTemplate、SessionFactory等复杂对象。
我们先看一下FactoryBean的接口:
public interface FactoryBean {
T getObject() throws Exception;
Class<?> getObjectType();
boolean isSingleton();
}
- getObject() – 返回工厂生成的对象,这是 Spring 容器将使用的对象
- getObjectType() – 返回此 FactoryBean 生成的对象的类型
- isSingleton() – 表示此 FactoryBean 生成的对象是否是单例
现在,让我们实现一个示例 FactoryBean。我们将实现一个 ToolFactory 来生成 Tool 类型的对象:
public class Tool {
private int id;
// standard constructors, getters and setters
}
工具工厂本身:
public class ToolFactory implements FactoryBean<Tool> {
private int factoryId;
private int toolId;
@Override
public Tool getObject() throws Exception {
return new Tool(toolId);
}
@Override
public Class<?> getObjectType() {
return Tool.class;
}
@Override
public boolean isSingleton() {
return false;
}
// standard setters and getters
}
我们可以看到,ToolFactory是一个FactoryBean,它可以产生Tool对象。
测试 Tool 对象是否正确注入:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = FactoryBeanAppConfig.class)
public class FactoryBeanJavaConfigTest {
@Autowired
private Tool tool;
@Resource(name = "&tool")
private ToolFactory toolFactory;
@Test
public void testConstructWorkerByJava() {
assertThat(tool.getId(), equalTo(2));
assertThat(toolFactory.getFactoryId(), equalTo(7070));
}
}
Spring 提供 AbstractFactoryBean 作为 FactoryBean 实现的简单模板超类。有了这个基类,我们现在可以更方便地实现创建单例或原型对象的工厂 bean。
让我们实现一个 SingleToolFactory 和 NonSingleToolFactory 来展示如何将 AbstractFactoryBean 用于单例和原型类型:
public class SingleToolFactory extends AbstractFactoryBean<Tool> {
private int factoryId;
private int toolId;
@Override
public Class<?> getObjectType() {
return Tool.class;
}
@Override
protected Tool createInstance() throws Exception {
return new Tool(toolId);
}
// standard setters and getters
}
现在是非单例实现:
public class NonSingleToolFactory extends AbstractFactoryBean<Tool> {
private int factoryId;
private int toolId;
public NonSingleToolFactory() {
setSingleton(false);
}
@Override
public Class<?> getObjectType() {
return Tool.class;
}
@Override
protected Tool createInstance() throws Exception {
return new Tool(toolId);
}
// standard setters and getters
}
可以测试 Worker 对象的属性是否按照我们的预期注入:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = { "classpath:factorybean-abstract-spring-ctx.xml" })
public class AbstractFactoryBeanTest {
@Resource(name = "singleTool")
private Tool tool1;
@Resource(name = "singleTool")
private Tool tool2;
@Resource(name = "nonSingleTool")
private Tool tool3;
@Resource(name = "nonSingleTool")
private Tool tool4;
@Test
public void testSingleToolFactory() {
assertThat(tool1.getId(), equalTo(1));
assertTrue(tool1 == tool2);
}
@Test
public void testNonSingleToolFactory() {
assertThat(tool3.getId(), equalTo(2));
assertThat(tool4.getId(), equalTo(2));
assertTrue(tool3 != tool4);
}
}
使用 FactoryBean 是一种很好的做法,可以封装复杂的构造逻辑或使在 Spring 中配置高度可配置的对象变得更容易。
参考:
Spring Boot启动时进行初始化的操作(2023 得物)
一种常见的方式是通过实现ApplicationRunner接口或CommandLineRunner接口来实现初始化操作。这两个接口在Spring Boot中专门用于在应用程序启动后执行初始化任务。我们可以创建一个类,并实现其中一个接口的run方法,在该方法中编写初始化逻辑。例如,可以在该方法中加载配置文件、初始化数据库连接等。这样,在应用程序启动后,Spring Boot会自动调用这些初始化方法。
ApplicationRunner接口:该接口提供了一个run方法,该方法在Spring Boot应用程序完全启动后执行。您可以创建一个实现ApplicationRunner接口的Bean,并在其中编写初始化逻辑。例如:
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.stereotype.Component;
@Component
public class MyApplicationRunner implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) throws Exception {
// 执行初始化逻辑
System.out.println("应用程序启动完成,进行初始化操作...");
}
}
CommandLineRunner接口:与ApplicationRunner类似,但它接受命令行参数作为方法参数。您可以创建一个实现CommandLineRunner接口的Bean,并在其中编写初始化逻辑。例如:
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
@Component
public class MyCommandLineRunner implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
// 执行初始化逻辑
System.out.println("应用程序启动完成,进行初始化操作...");
}
}
另一种方式是使用注解@PostConstruct来标记一个方法,在Spring容器初始化过程中,该方法会在依赖注入完成后自动执行。通过在这个方法中编写初始化逻辑,可以实现在Spring Boot启动时进行初始化操作。
🐬 MySQL
可重复读和已提交读隔离级别表现的现象是什么,区别是什么样的?(2023 美团)
- 读提交,指一个事务提交之后,它做的变更才能被其他事务看到,会有不可重复读、幻读的问题。
- 可重复读,指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别,解决了不可重复读的问题,并且以很大程度上避免幻读现象的发生。
数据库引擎知道哪些?(2023 美团)
MySQL 常见的存储引擎 InnoDB、MyISAM 和 Memory 分别支持的索引类型。
数据文件大体分成哪几种数据文件?(2023 美团)
我们每创建一个 database(数据库) 都会在 /var/lib/mysql/ 目录里面创建一个以 database 为名的目录,然后保存表结构和表数据的文件都会存放在这个目录里。
比如,我这里有一个名为 my_test 的 database,该 database 里有一张名为 t_order 数据库表。  然后,我们进入 /var/lib/mysql/my_test 目录,看看里面有什么文件?
然后,我们进入 /var/lib/mysql/my_test 目录,看看里面有什么文件?
[root ~]#ls /var/lib/mysql/my_test
db.opt
t_order.frm
t_order.ibd
可以看到,共有三个文件,这三个文件分别代表着:
- db.opt,用来存储当前数据库的默认字符集和字符校验规则。
- t_order.frm ,t_order 的表结构会保存在这个文件。在 MySQL 中建立一张表都会生成一个.frm 文件,该文件是用来保存每个表的元数据信息的,主要包含表结构定义。
- t_order.ibd,t_order 的表数据会保存在这个文件。表数据既可以存在共享表空间文件(文件名:ibdata1)里,也可以存放在独占表空间文件(文件名:表名字.ibd)。这个行为是由参数 innodb_file_per_table 控制的,若设置了参数 innodb_file_per_table 为 1,则会将存储的数据、索引等信息单独存储在一个独占表空间,从 MySQL 5.6.6 版本开始,它的默认值就是 1 了,因此从这个版本之后, MySQL 中每一张表的数据都存放在一个独立的 .ibd 文件。
对一个慢sql怎么去排查?(2023 美团)
可通过开启mysql的慢日志查询,设置好时间阈值,进行捕获
索引字段是不是建的越多越好(2023 美团)
索引越多,在写入频繁的场景下,对于B+树的维护所付出的性能消耗也会越大
什么是覆盖索引?(2023 快手)
这个其实在2022年的大厂面试中出现过,但是是以聚簇索引形式提问出现
覆盖索引是一种数据库查询优化机制。在覆盖索引中,索引本身包含了查询所需要的所有数据,因此在执行查询时,数据库系统可以只访问索引,而不需要再访问数据行。这样可以显著提高查询速度,因为访问索引通常比访问数据行要快。(在索引 B+Tree 的叶子节点上都能找得到的那些索引,从二级索引中查询得到记录,而不需要通过聚簇索引查询获得,可以避免回表的操作)
覆盖索引与聚簇索引和非聚簇索引的主要区别在于数据的存储和访问方式:
- 覆盖索引:它被称为“覆盖”,因为只需使用索引即可满足查询,而无需访问表数据本身。这可以使查询更快,因为它避免了访问表数据的需要,而是使用通常更小、更紧凑的索引数据
- 聚簇索引:在聚簇索引中,数据行实际上被存储在索引中,因此每个表只能有一个聚簇索引。索引的顺序与磁盘上行的物理顺序相同。聚簇索引可以快速查找指定的数据行,但如果你需要在同一表上执行许多不同的查询,那么可能会受到限制,因为每个表只能有一个聚簇索引。
- 非聚簇索引:非聚簇索引是一个单独的结构,与数据行分开存储。非聚簇索引包含索引键值和一个指向每个数据行实际位置的指针。在非聚簇索引中查找数据需要两个步骤:首先在索引中查找,然后使用索引中的指针访问数据行。因此,非聚簇索引的查询通常比聚簇索引要慢一些。
覆盖索引可以看作是非聚簇索引的一个特例,它不仅包含索引键值和数据行的指针,还包含查询所需的其他列的数据。所以,如果查询可以被一个覆盖索引满足,那么查询速度就会比一般的非聚簇索引要快,因为数据库系统不需要再访问数据行,所有需要的数据都在索引中。使用覆盖索引的好处就是,不需要查询出包含整行记录的所有信息,也就减少了大量的 I/O 操作。
使用覆盖索引的例子:
CREATE TABLE `tbl_user` (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`age` int(11) NOT NULL,
KEY `idx_name_age` (`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
SELECT `name`, `age` FROM `tbl_user` WHERE `name` = 'John' AND `age` = 30;
这里 (name, age) 组成了一个复合索引 idx_name_age,查询只需要name和age两列,所以这个查询可以使用覆盖索引,数据库只需要扫描索引,不需要访问表数据,所以查询效率高。
具体查询为:
SELECT `name`, `age` FROM `tbl_user` WHERE `name` = 'John' AND `age` = 30;
这个查询只需要name和age两个字段,而idx_name_age索引中就包含这两个字段,所以这个查询可以使用覆盖索引。 覆盖索引的查询语句应该是:
SELECT
idx_name_age.name,
idx_name_age.age
FROM tbl_user
WHERE idx_name_age.name = 'John' AND idx_name_age.age = 30;
这里我们直接从idx_name_age索引中选取需要的字段,而不再访问表数据,所以这个查询使用了覆盖索引。 所以,一个查询要使用覆盖索引,需要满足两个条件:
- 查询所需要的字段都存在于某个索引中
- 查询语句直接从该索引中选取字段,而不再访问表数据
没使用覆盖索引的例子:
CREATE TABLE `tbl_user` (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`age` int(11) NOT NULL,
`address` varchar(100) NOT NULL,
KEY `idx_name_age` (`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
SELECT `name`, `age`, `address` FROM `tbl_user` WHERE `name` = 'John' AND `age` = 30;
这里虽然有(name, age)的索引,但是由于查询需要的address字段不在该索引中,所以这个查询无法使用覆盖索引,需要访问表数据获取address字段,查询效率较低。
图示: 在没有使用覆盖索引,数据库查询数据是这样: 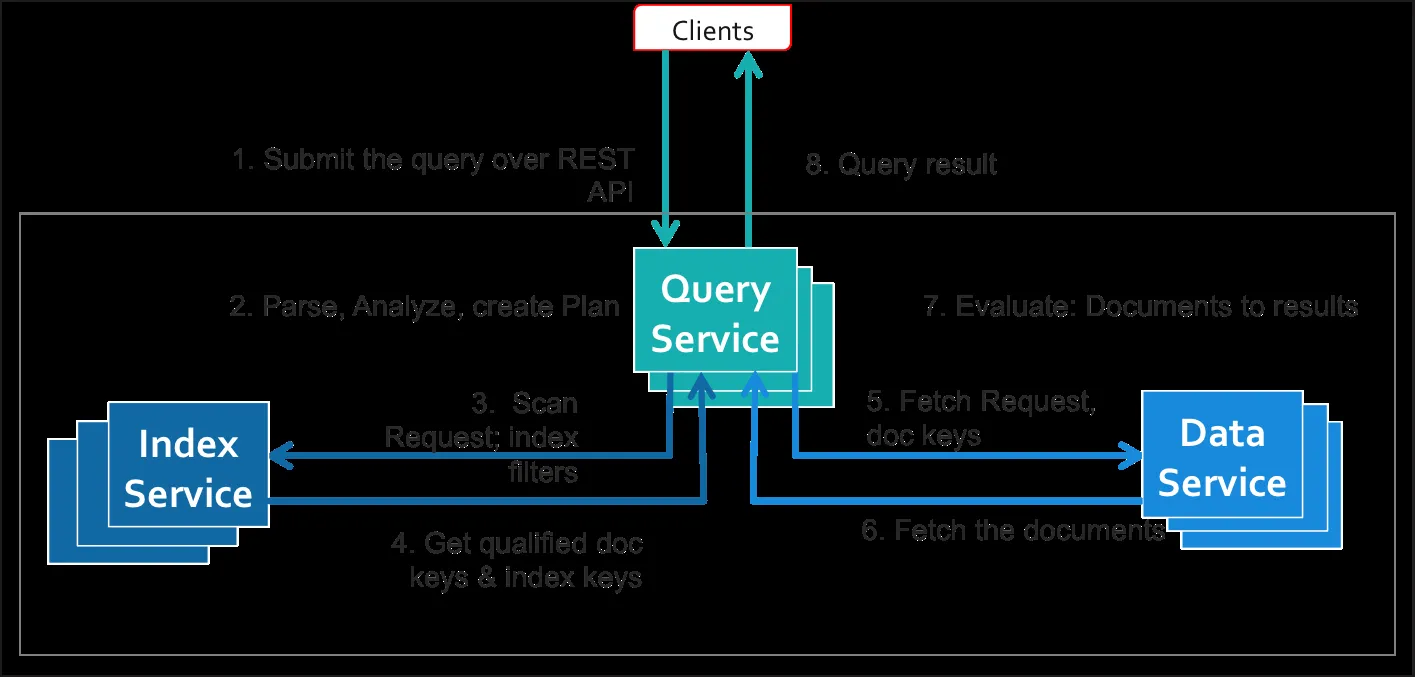
使用了覆盖索引避免了从数据服务中获取数据的额外步骤。这导致了相当大的性能改进。 
参考文献:
- https://stackoverflow.com/questions/62137/what-is-a-covered-index 什么是覆盖索引?
- https://xiaolincoding.com/mysql/index/index_interview.html#按字段个数分类 覆盖索引优化-小林coding
- https://stackoverflow.com/questions/609343/what-are-covering-indexes-and-covered-queries-in-sql-server 在SQL Server中什么是覆盖索引和覆盖查询?
- https://docs.couchbase.com/server/current/n1ql/n1ql-language-reference/covering-indexes.html Covering Indexes
- https://www.red-gate.com/simple-talk/databases/sql-server/learn/using-covering-indexes-to-improve-query-performance/ 使用覆盖索引以提高查询性能
mysql的隔离级别是什么?mysql是如何实现的?(2023 阿里)
MySQL InnoDB 引擎的默认隔离级别虽然是「可重复读」,但是它很大程度上避免幻读现象(并不是完全解决了),解决的方案有两种:
- 针对快照读(普通 select 语句),是通过 MVCC 方式解决了幻读,因为可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其他事务插入了一条数据,是查询不出来这条数据的,所以就很好了避免幻读问题。
- 针对当前读(select ... for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读,因为当执行 select ... for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围内插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入,所以就很好了避免幻读问题。
MySQL中delete 和 truncate 的区别?(2023 阿里实习)
- 命令类型:DELETE是一个DML(数据操作语言)命令,而TRUNCATE是一个DDL(数据定义语言)命令。
- 删除的数据范围:DELETE可以删除表中的一行或多行,TRUNCATE则会删除表中的所有行。
- 是否可以撤销:DELETE命令执行后,你可以使用ROLLBACK命令撤销更改,而TRUNCATE执行后无法撤销。
- 日志记录:DELETE命令在删除行时会记录行的日志,而TRUNCATE命令在删除数据时不记录任何日志。
- 性能:TRUNCATE命令比DELETE命令快,因为它不记录任何日志。
- 触发器行为:如果你在表上设置了触发器,那么DELETE命令会触发它,而TRUNCATE命令不会。
- 参照完整性约束:TRUNCATE是不能在参照完整性约束存在的情况下使用的,即,如果存在外键约束,不能使用TRUNCATE。
什么是联合索引,为什么要建联合索引?(2023 阿里实习)
联合索引是数据库中一种特殊类型的索引,它基于两个或多个列的值进行创建。简单来说,如果你经常在WHERE子句中同时使用多个列进行查询,那么可能需要使用联合索引。
联合索引的主要优势在于它可以极大地提高查询速度。如果你的查询通常会涉及到多个列,那么使用联合索引可能会比使用多个单列索引更高效。同时,因为索引本身会占用存储空间,联合索引比多个单列索引需要更少的存储空间。
例如:假设你有一个人员表,它有两个字段:名字(FirstName)和姓氏(LastName)。你经常运行如下查询来查找特定的全名:
SELECT * FROM People WHERE FirstName = 'John' AND LastName = 'Doe';
在这种情况下,如果你分别为 FirstName 和 LastName 创建索引,MySQL 需要首先在 FirstName 索引中找到所有名为 'John' 的人,然后在 LastName 索引中找到所有姓为 'Doe' 的人,最后对这两个结果集进行交集操作。这可能需要大量的时间和计算资源,特别是在表非常大的时候。
但是,如果你为这两列创建一个联合索引,那么 MySQL 可以直接使用这个索引来找到所有名为 'John' 并且姓为 'Doe' 的人,无需额外的交集操作。这样查询的效率就会大大提高。
创建联合索引的SQL命令可能如下:
CREATE INDEX idx_firstname_lastname ON People (FirstName, LastName);
然后,你的查询可以直接利用这个联合索引,大大提高查询效率。
SQL explain 会输出哪些信息?(2023 阿里实习)
- ID:表示查询执行计划中每个操作的唯一标识符。
- Select Type:表示查询中的子查询或者表的类型,如 SIMPLE(无子查询或者 UNION)、PRIMARY(最外层查询)、SUBQUERY、DERIVED 等。
- Table:表示正在访问的表的名称。
- Type:表示连接类型,如 ALL(全表扫描)、index(全索引扫描)、range(范围扫描)、ref(使用非唯一索引键或者唯一索引键的一部分进行查找等)。
- Possible Keys:表示查询可能使用的索引。
- Key:表示实际使用的索引。
- Key Length:表示使用的索引的长度。
- Ref:表示哪些列或者常量被用于查找索引列上的值。
- Rows:估计要检查的行数。
- Filtered:表示返回的行数占扫描行数的百分比(基于条件过滤)。
- Extra:包含有关查询执行计划的其他信息,如 Using filesort、Using temporary、Using index 等。
参考:
sql 怎么手动加锁(2023 阿里实习)
在 SQL 中手动加锁通常是通过使用显式锁定语句来实现的。在 MySQL 中,你可以使用 LOCK TABLES 和 UNLOCK TABLES 语句来手动加锁和解锁。以下是一些示例:
- 读锁(Read Lock):给一个表加读锁,可以防止其他事务对该表进行写操作,但允许其他事务进行读操作。要给一个表加读锁,可以使用以下语句:
LOCK TABLES table_name READ;
其中,table_name 是你要加锁的表的名称。
- 写锁(Write Lock):给一个表加写锁,可以防止其他事务对该表进行读、写操作。要给一个表加写锁,可以使用以下语句:
LOCK TABLES table_name WRITE;
在使用 LOCK TABLES 对表进行显式锁定后,你需要使用 UNLOCK TABLES 语句来释放锁。示例如下:
UNLOCK TABLES;
请注意,这种手动加锁方式主要适用于 MyISAM 存储引擎,因为 MyISAM 不支持事务。对于支持事务的存储引擎(如 InnoDB),你通常应该使用事务来实现并发控制和锁定。
在 InnoDB 存储引擎中,你可以使用 SELECT ... FOR UPDATE 或 SELECT ... LOCK IN SHARE MODE 语句来锁定行。例如:
- 行锁 - FOR UPDATE:给一个或多个行加排他锁,防止其他事务对这些行进行读、写操作。
START TRANSACTION;
SELECT * FROM table_name WHERE condition FOR UPDATE;
-- 进行其他操作
COMMIT;
- 行锁 - LOCK IN SHARE MODE:给一个或多个行加共享锁,允许其他事务对这些行进行读操作,但阻止其他事务进行写操作。
START TRANSACTION;
SELECT * FROM table_name WHERE condition LOCK IN SHARE MODE;
-- 进行其他操作
COMMIT;
在使用行锁时,请确保你的操作在事务中进行,并在完成操作后提交事务。这将释放锁并保持数据一致性。
介绍一些 mysql 底层结构?(2023 蚂蚁金服)
- 存储引擎(Storage Engines):MySQL 支持多种存储引擎,每种引擎都有其特定的特性和用途。例如,InnoDB 是支持事务和行级锁定的存储引擎,而 MyISAM 则是一个简单、高性能的引擎,适用于只读或读写比较低的场景。选择合适的存储引擎对于数据库性能和可靠性至关重要。
- 服务器层(Server Layer):服务器层负责处理客户端连接、查询缓存、查询分析、查询优化和执行等任务。它提供了许多功能,如存储过程、触发器、视图等,以帮助用户更高效地管理和使用数据库。
- 缓冲池(Buffer Pool):缓冲池是 InnoDB 存储引擎用于缓存数据和索引的内存区域。缓冲池的大小和管理对于数据库性能至关重要,因为它可以减少磁盘 I/O,从而提高查询速度。
- 日志(Logs):MySQL 使用多种日志来记录数据库活动和辅助恢复。例如,二进制日志(Binary Log)记录了数据库更改的历史,可以用于数据复制和恢复。而 InnoDB 的重做日志(Redo Log)则记录了对数据的修改操作,用于确保事务的持久性和数据库在崩溃后的恢复。
- 索引(Indexes):索引是数据库中用于加速查询的数据结构。MySQL 支持多种索引类型,如 B-Tree、哈希索引、全文索引等。合理地使用索引可以大幅提高查询性能,但过多的索引可能会导致更新操作变慢。
- 锁定(Locking):为了保证数据一致性和并发控制,MySQL 使用各种锁定机制,如表锁、行锁、元数据锁等。锁定策略的选择和实现对于数据库性能和并发处理能力至关重要。
- 事务(Transactions):事务是一组原子性的数据库操作,它们要么全部成功执行,要么完全不执行。事务可以帮助确保数据一致性和并发控制。InnoDB 存储引擎提供了对事务的支持,包括提交、回滚、隔离级别等功能。
参考:
mysql中,主键索引和唯一索引的区别是什么?(2023 百度提前批)
在MySQL中,**主键索引(Primary Key)和唯一索引(Unique Key)**都是两种非常重要的索引类型,它们之间的主要区别可以从以下几个方面来理解:
- 唯一性:主键索引和唯一索引都保证了索引列的唯一性。换句话说,主键索引和唯一索引都要求索引列的值唯一,不能有重复的值。
- 非空性:主键索引要求索引列的值必须是非空的,而唯一索引则允许索引列的值为NULL。也就是说,如果你在一列上定义了主键索引,那么你不能在这列上插入NULL值;而如果你在一列上定义了唯一索引,那么你可以在这列上插入NULL值。
- 数量:在一个表中,主键索引只能有一个,而唯一索引可以有多个。
- 自动增长:主键可以自动增长,但是唯一索引不能。
- 集群索引:在InnoDB存储引擎中,主键索引是集群索引(Clustered Index),也就是说,数据记录是按照主键的顺序来存储的。如果一个表没有明确定义主键,InnoDB会选择一个唯一索引作为主键,如果没有唯一索引,InnoDB会自动生成一个6字节的ROWID作为主键。
这些区别让主键索引和唯一索引在数据库设计和优化中发挥不同的作用。
一个联合索引(a, b, c),查询(a, c),能用到索引吗?(2023 百度提前批)
在MySQL中,使用联合索引(比如索引(a, b, c))查询时,需要按照索引的顺序使用列。这是由MySQL的索引策略决定的,称为最左前缀原则或最左前缀匹配原则。
对于查询(a, c),只有在查询条件中包含“a”字段,并且"b"字段也在查询条件中时,"c"才能用到索引。这是因为在联合索引(a, b, c)中,“c"是第三个字段,如果查询条件中不包含"b”,那么索引在"b"之后的部分都不能使用。
因此,如果你的查询条件是(a, c),那么MySQL只能使用到"a"的部分索引,不能利用到"c"的部分索引,即便"c"在索引中。
为了使查询更有效地使用索引,你可以考虑调整索引或查询的设计。例如,你可以创建一个新的联合索引(a, c),或者在查询条件中包含"b"字段。
事务原子性是怎么实现的?(2023 美团)
MySQL的事务原子性主要通过Undo Log(撤销日志)来实现的。
当进行一次事务操作时,MySQL会首先在Undo Log中记录下事务操作前的数据状态。如果事务成功执行并提交,Undo Log中的记录就可以被删除。但如果在事务执行过程中出现错误,或者用户执行了ROLLBACK操作,MySQL就会利用Undo Log中的信息将数据恢复到事务开始前的状态,从而实现事务的原子性。
这就意味着,事务要么全部执行成功,要么如果部分执行失败,那么已经执行的部分也会被撤销,保证数据的一致性。
事务的隔离性怎么实现的?(2023 美团)
MySQL的事务隔离性主要通过锁机制和多版本并发控制(MVCC)来实现。
- 锁机制:包括行锁和表锁。行锁可以精确到数据库表中的某一行,而表锁则会锁定整个数据表。当一个事务在操作某个数据项时,会对其加锁,阻止其他事务对同一数据项的并发操作,从而实现隔离性。
- 多版本并发控制(MVCC):这是InnoDB存储引擎特有的一种机制,它可以在不加锁的情况下创建数据在某一时间点的快照。在读取数据时,MVCC会返回该时间点的数据版本,即使该数据后来被其他事务修改。这样,每个事务都有自己的数据视图,彼此之间不会互相影响,实现了隔离性。
此外,MySQL还提供了四种隔离级别(读未提交、读已提交、可重复读、串行化),可以根据需要选择不同的隔离级别,以在并发性和数据一致性之间取得平衡。
事务一致性怎么实现的?(2023 美团)
MySQL实现事务一致性主要依赖于其InnoDB存储引擎的ACID属性,其中C代表一致性(Consistency)。具体来说,以下是MySQL如何实现事务一致性的一些方式:
- 使用锁机制:InnoDB存储引擎支持行级锁和表级锁,通过锁机制来控制并发事务的访问冲突,确保每个事务都在一致性的状态下执行。
- 使用MVCC:InnoDB存储引擎通过MVCC来实现读已提交和可重复读两个隔离级别,保证了事务的一致性视图,即在事务开始时生成一个快照,事务在执行过程中看到的数据都是这个快照中的数据。
- 使用Undo日志:InnoDB存储引擎在修改数据前,会先将原始数据保存在Undo日志中,如果事务失败或者需要回滚,就可以利用Undo日志将数据恢复到原始状态,从而保证了数据的一致性。
- 使用Redo日志:Redo日志用于保证事务的持久性,但也间接保证了一致性。因为在系统崩溃恢复时,可以通过Redo日志来重做已提交的事务,保证这些事务的修改能够持久保存。
事务的持久性怎么实现的?(通过2023 美团面试题思考补充)
MySQL实现事务持久性主要依赖于其使用的存储引擎,比如InnoDB。以下是InnoDB如何实现事务持久性的一些方式:
- 重做日志(Redo Logs):InnoDB引擎有一组重做日志文件,事务提交前,会先将更改写入到重做日志中,并保证这些日志被写入到磁盘。这种机制就是所谓的预写式日志(Write-Ahead Logging,WAL)。每个重做日志都包含了事务的相关信息,以及这个事务所做的修改。
- 刷新缓冲池(Flush Buffer Pool):当事务提交时,InnoDB引擎只是将更改写入了重做日志,并没有立即写入到磁盘的数据文件中。实际的写入过程是在后台以一定的频率进行的,这就是所谓的刷新缓冲池。
- 崩溃恢复(Crash Recovery):如果数据库在事务执行过程中崩溃,InnoDB可以使用重做日志来恢复数据到一个一致的状态。在重启过程中,InnoDB会检查重做日志,并将所有未完成的事务所做的修改应用到数据文件中,同时取消所有未提交的事务。
这些机制共同确保了MySQL事务的持久性,即使在系统崩溃后,已提交的事务所做的修改也能被正确地恢复。
具体如何刷盘可以看:https://javaguide.cn/database/mysql/mysql-logs.html#刷盘时机
事务的这四个特性是怎么实现的?(2023 阿里)
- 持久性是通过 redo log (重做日志)来保证的;
- 原子性是通过 undo log(回滚日志) 来保证的;
- 隔离性是通过 MVCC(多版本并发控制) 或锁机制来保证的;
- 一致性则是通过持久性+原子性+隔离性来保证;
MySQL死锁的案例(2023 阿里)
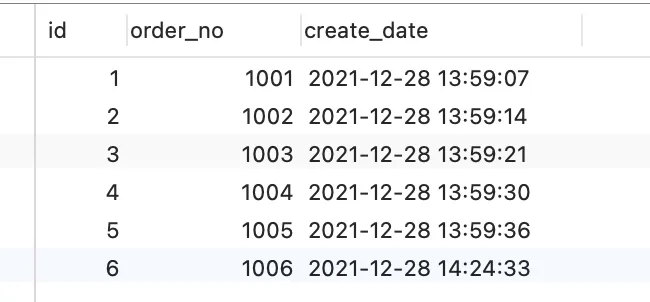
t_order 表里现在已经有了 6 条记录,其中 id 字段为主键索引,order_no 字段普通索引,也就是非唯一索引:
有两事务,一个事务要插入订单 1007 ,另外一个事务要插入订单 1008,因为需要对订单做幂等性校验,所以两个事务先要查询该订单是否存在,不存在才插入记录,过程如下:
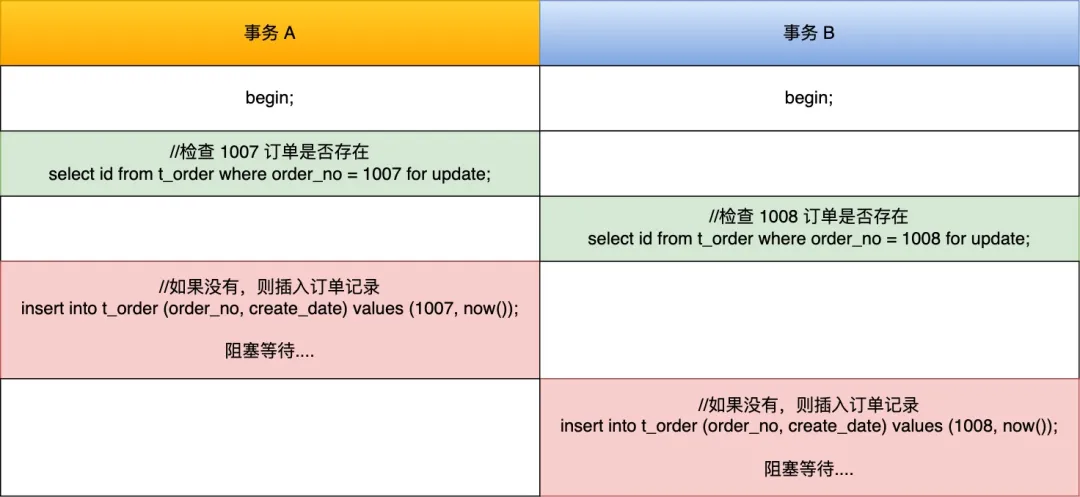
可以看到,两个事务都陷入了等待状态,原因:
- T1: 事务 a 在执行 select id from t_order where order_no = 1007 for update,会在二级索引(INDEX_NAME : index_order)上加的是 X 型的 next-key 锁,锁范围是
(1006, +∞]。 - T2: 事务 b 在执行 select id from t_order where order_no = 1008 for update,会在二级索引(INDEX_NAME : index_order)上加的是 X 型的 next-key 锁,锁范围是
(1006, +∞]。 - T3:事务 a 往事务 A next-key 锁的范围 (1006, +∞] 里插入 id = 1007 的记录就会被锁住:因为当我们执行以下插入语句时,会在插入间隙上获取插入意向锁,而插入意向锁与间隙锁是冲突的,所以当其它事务持有该间隙的间隙锁时,需要等待其它事务释放间隙锁之后,才能获取到插入意向锁
- T4:事务 b 往事务 a next-key 锁的范围 (1006, +∞] 里插入 id = 1008 的记录就会被锁住,原因也是一样,申请插入意向锁的时候阻塞了。
案例中的事务 A 和事务 B 在执行完后 select ... for update 语句后,都持有范围为(1006,+∞]的next-key 锁,而接下来的插入操作为了获取到插入意向锁,都在等待对方事务的间隙锁释放,于是就造成了循环等待,导致死锁。
MySQL分库分表之后怎么确保每个表的id都是唯一的?(2023 阿里)
可以使用雪花算法算法来生成分布式 id,它会生成一个 64 bit 的整数,可以保证不同进程主键的不重复性,以及相同进程主键的有序性。

在同一个进程中,它首先是通过时间位保证不重复,如果时间相同则是通过序列位保证。同时由于时间位是单调递增的,且各个服务器如果大体做了时间同步,那么生成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插入的高效性。
但是雪花算法有缺点,雪花算法是强依赖于时间的,而如果机器时间发生回拨,有可能会生成重复的 ID。可以用美团提供的分布式 ID 解决方案 Leaf,他是不依赖时间戳的
MVCC的隔离机制介绍一下?(2023 美团)
- Read View 中四个字段作用;
- 聚簇索引记录中两个跟事务有关的隐藏列;
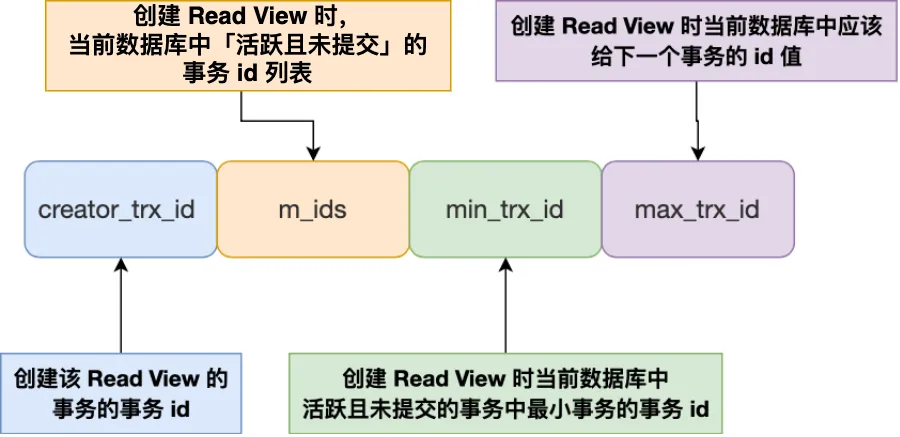
那 Read View 到底是个什么东西?
Read View 有四个重要的字段:
- m_ids :指的是在创建 Read View 时,当前数据库中「活跃事务」的事务 id 列表,注意是一个列表,“活跃事务”指的就是,启动了但还没提交的事务。
- min_trx_id :指的是在创建 Read View 时,当前数据库中「活跃事务」中事务 id 最小的事务,也就是 m_ids 的最小值。
- max_trx_id :这个并不是 m_ids 的最大值,而是创建 Read View 时当前数据库中应该给下一个事务的 id 值,也就是全局事务中最大的事务 id 值 + 1;
- creator_trx_id :指的是创建该 Read View 的事务的事务 id。
知道了 Read View 的字段,我们还需要了解聚簇索引记录中的两个隐藏列。
假设在账户余额表插入一条小林余额为 100 万的记录,然后我把这两个隐藏列也画出来,该记录的整个示意图如下:
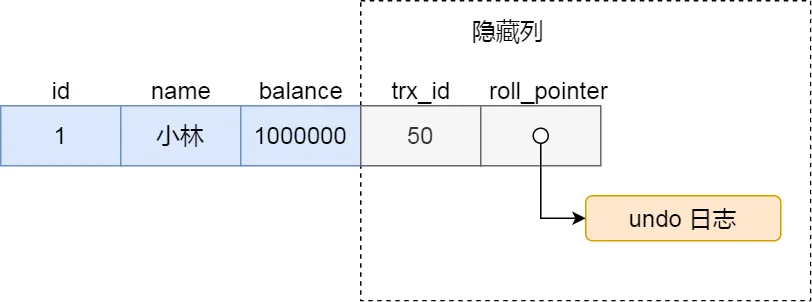
对于使用 InnoDB 存储引擎的数据库表,它的聚簇索引记录中都包含下面两个隐藏列:
- trx_id,当一个事务对某条聚簇索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;
- roll_pointer,每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
在创建 Read View 后,我们可以将记录中的 trx_id 划分这三种情况:
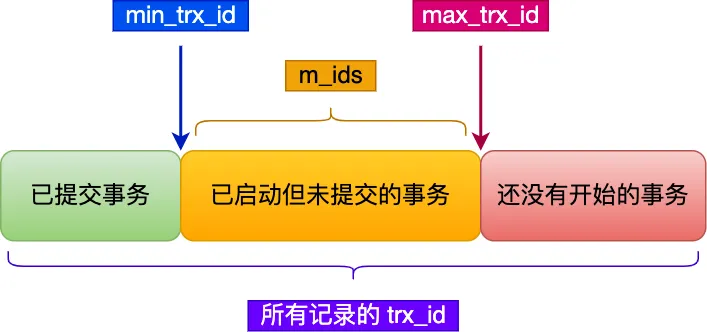
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
如果记录的 trx_id 值小于 Read View 中的
min_trx_id值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。如果记录的 trx_id 值大于等于 Read View 中的
max_trx_id值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。如果记录的 trx_id 值在 Read View 的 min_trx_id和max_trx_id之间,需要判断 trx_id 是否在 m_ids 列表中:
- 如果记录的 trx_id 在
m_ids列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。 - 如果记录的 trx_id 不在
m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
- 如果记录的 trx_id 在
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
数据库的三大范式,可以反范式吗?(2023 美团)
数据库的三大范式是数据库设计的基本原则,主要包括:
- 第一范式(1NF) :数据表中的每一列都是不可分割的最小单元,也就是属性值是原子性的。
- 第二范式(2NF):在第一范式的基础上,要求数据表中的每一列都与主键相关,也就是说非主键列必须完全依赖于主键,不能只依赖主键的一部分(针对联合主键)。
- 第三范式(3NF):在第二范式的基础上,要求一个数据表中不包含已在其他表中已包含的非主键信息,也就是说,非主键列必须直接依赖于主键,不能存在传递依赖。
传递依赖进步一解释:在一个数据库表中,如果存在一个非主键列B,它不直接依赖于该表的主键列A,而是依赖于另一个非主键列C,而这个非主键列C又依赖于主键列A,那么就可以说,非主键列B对主键列A存在传递依赖。
例如,假设我们有一个包含学生ID(主键)、学生姓名、班级名称和班主任姓名的表。在这个表中,学生姓名直接依赖于学生ID,班级名称也直接依赖于学生ID,但是班主任姓名并不直接依赖于学生ID,而是依赖于班级名称(因为一个班级对应一个班主任)。在这种情况下,我们就可以说,班主任姓名对学生ID存在传递依赖。
为了满足第三范式(3NF),我们需要消除这种传递依赖。具体来说,我们可以将原表拆分为两个表,一个表包含学生ID、学生姓名和班级名称,另一个表包含班级名称和班主任姓名。这样,每个表中的非主键列都直接依赖于主键,不存在传递依赖,从而满足第三范式。
关于反范式,是的,数据库设计可以反范式。反范式设计是为了优化数据库性能,通过增加冗余数据或者组合数据,减少复杂的数据查询,提高数据读取性能。
反范式:是数据库设计中的一种策略,通过引入数据冗余或合并表来优化读取性能,但可能会增加数据管理的复杂性和数据一致性的风险。
在理想的范式设计中,为了减少数据冗余和避免数据异常(如插入异常、更新异常和删除异常),一般会将数据分解到多个相关的表中。然而,这种设计可能会导致查询性能降低,因为需要执行多表连接操作以获取所需的数据。
反范式设计通过以下方式优化读取性能:
- 数据冗余:在多个表中存储相同的数据,以减少多表连接操作。这可能会导致数据更新更复杂,因为需要在多个位置更新相同的数据。
- 数据预计算:将经常需要计算的数据预先计算并存储起来,如总数、平均数等。
- 表合并:将多个表合并为一个表,以减少多表连接操作。这可能会导致数据冗余,但可以提高查询性能。
虽然反范式设计可以优化读取性能,但也会带来数据管理的复杂性和数据一致性的风险。因此,是否使用反范式设计需要根据具体的应用场景和性能需求进行权衡。
MySQL中,什么样的数据不推荐加索引?(2023 影石360)
- 低基数列:如果列的值大多数都是相同的,例如性别列(只有男、女两种值),那么对这种列添加索引可能并不高效。
- 频繁变化的列:如果某个列的数据频繁变动,那么每次数据变动时索引都需要重建,这会导致性能下降。
- 大文本列:对于非常长的文本,建立索引可能会非常耗费资源。如果需要,可以考虑使用全文索引或者其他搜索引擎解决方案。
- 冗余索引:如果已经有了一个多列索引,例如
(A, B, C),那么对于A列的单独索引可能就是冗余的,因为(A, B, C)已经包含了A的索引。 - 存储开销:每个索引都需要占用额外的磁盘空间。如果有太多的索引,不仅会浪费存储空间,还可能导致额外的I/O开销。
- 插入、删除、更新操作:索引虽然可以加速查询,但也会减慢插入、删除和更新操作的速度,因为每次这些操作发生时,索引也需要更新。
当然,是否为某列添加索引还需要根据实际的查询需求、数据分布和业务场景来决定。在决定加索引之前,最好进行性能测试和分析,确保索引能带来预期的效果。
数据库自增id,当id值大于MAXINT时,数据库如何做 ?(2023 快手)
- 做分库分表之类的优化了
- 调整数据类型,修改为BIGINT数据类型,但是要注意数据太多,DDL执行时长问题
了解过前缀索引吗?(2023 快手)
使用前缀索引是为了减小索引字段大小,可以增加一个索引页中存储的索引值,有效提高索引的查询速度。在一些大字符串的字段作为索引时,使用前缀索引可以帮助我们减小索引项的大小。
假设有一个包含用户名的MySQL表users,表结构如下:
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(255)
);
对username字段创建完整索引可能会占用较多空间。如果知道大多数查询只会使用用户名的前几个字符,可以创建前缀索引。例如,为username字段的前4个字符创建索引:
ALTER TABLE users ADD INDEX idx_username_prefix(username(4));
之后,以下查询将使用前缀索引,从而更快地返回结果:
SELECT * FROM users WHERE username LIKE 'John%';
但是,像这样的查询将无法使用前缀索引:
SELECT * FROM users WHERE username LIKE '%John';
前缀索引减少了索引的大小,但也有局限性:
- order by 就无法使用前缀索引;
- 无法把前缀索引用作覆盖索引;
介绍一下联合索引?最左匹配原则是什么?(2023 快手)
通过将多个字段组合成一个索引,该索引就被称为联合索引。
比如,将商品表中的 product_no 和 name 字段组合成联合索引(product_no, name),创建联合索引的方式如下:
CREATE INDEX index_product_no_name ON product(product_no, name);
联合索引(product_no, name) 的 B+Tree 示意图如下(图中叶子节点之间我画了单向链表,但是实际上是双向链表,原图我找不到了,修改不了,偷个懒我不重画了,大家脑补成双向链表就行)。
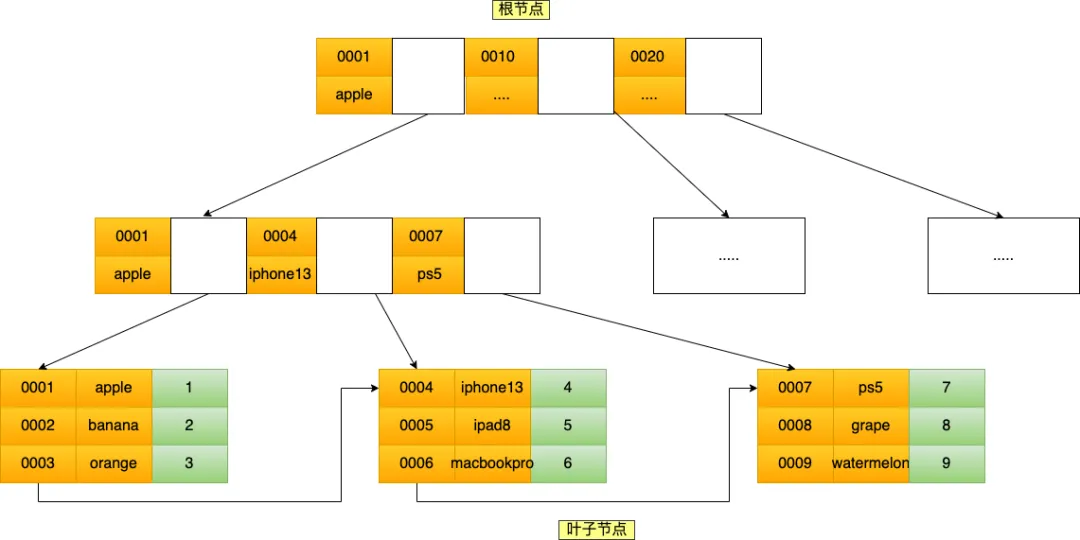
可以看到,联合索引的非叶子节点用两个字段的值作为 B+Tree 的 key 值。当在联合索引查询数据时,先按 product_no 字段比较,在 product_no 相同的情况下再按 name 字段比较。
也就是说,联合索引查询的 B+Tree 是先按 product_no 进行排序,然后再 product_no 相同的情况再按 name 字段排序。
因此,使用联合索引时,存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。在使用联合索引进行查询的时候,如果不遵循「最左匹配原则」,联合索引会失效,这样就无法利用到索引快速查询的特性了。
比如,如果创建了一个 (a, b, c) 联合索引,如果查询条件是以下这几种,就可以匹配上联合索引:
- where a=1;
- where a=1 and b=2 and c=3;
- where a=1 and b=2;
需要注意的是,因为有查询优化器,所以 a 字段在 where 子句的顺序并不重要。
但是,如果查询条件是以下这几种,因为不符合最左匹配原则,所以就无法匹配上联合索引,联合索引就会失效:
- where b=2;
- where c=3;
- where b=2 and c=3;
上面这些查询条件之所以会失效,是因为(a, b, c) 联合索引,是先按 a 排序,在 a 相同的情况再按 b 排序,在 b 相同的情况再按 c 排序。所以,b 和 c 是全局无序,局部相对有序的,这样在没有遵循最左匹配原则的情况下,是无法利用到索引的。
我这里举联合索引(a,b)的例子,该联合索引的 B+ Tree 如下(图中叶子节点之间我画了单向链表,但是实际上是双向链表,原图我找不到了,修改不了,偷个懒我不重画了,大家脑补成双向链表就行)。

可以看到,a 是全局有序的(1, 2, 2, 3, 4, 5, 6, 7 ,8),而 b 是全局是无序的(12,7,8,2,3,8,10,5,2)。因此,直接执行where b = 2这种查询条件没有办法利用联合索引的,利用索引的前提是索引里的 key 是有序的。
只有在 a 相同的情况才,b 才是有序的,比如 a 等于 2 的时候,b 的值为(7,8),这时就是有序的,这个有序状态是局部的,因此,执行where a = 2 and b = 7是 a 和 b 字段能用到联合索引的,也就是联合索引生效了。
联合索引有一些特殊情况,并不是查询过程使用了联合索引查询,就代表联合索引中的所有字段都用到了联合索引进行索引查询,也就是可能存在部分字段用到联合索引的 B+Tree,部分字段没有用到联合索引的 B+Tree 的情况。
这种特殊情况就发生在范围查询。联合索引的最左匹配原则会一直向右匹配直到遇到「范围查询」就会停止匹配。也就是范围查询的字段可以用到联合索引,但是在范围查询字段的后面的字段无法用到联合索引。
MySQL的索引为什么是b+树(2023 得物)
因为 B+ 树具有以下几个优点:
- 查询效率稳定: B+ 树的高度较矮,因此查询时需要的磁盘 I/O 操作次数较少。这有助于实现更高的查询速度和更稳定的性能。
- 范围查询方便: B+ 树的所有叶子节点都位于同一层,并且通过指针连接,这使得范围查询更加高效。
- 更适合磁盘: 数据库存储通常依赖于磁盘,而磁盘的 I/O 操作通常具有高成本。B+ 树允许更有效地读取数据块,减少了 I/O 操作。
- 高扇出率: 由于 B+ 树节点可以存储大量子节点的引用,树的高度相对较低,这进一步减少了查询需要的磁盘 I/O 操作次数。
- 适应性强: B+ 树可以容易地插入、删除和查找操作,而且能自动平衡,这是数据库系统中非常需要的特性。
- 数据局部性: B+ 树有助于实现数据的局部性原理,即经常一起使用的数据也应该一起存储。这有助于提高缓存和磁盘 I/O 效率。
- 易于维护: B+ 树易于分裂和合并,这样在数据插入和删除时能保持良好的平衡性。
- 多路复用: 在多用户或并发环境下,B+ 树能更好地支持多路复用。
一个sql语句,判断是否用了索引,是否回表(2023 得物)
EXPLAIN
mysql的死锁问题(2023 得物)
MySQL在以下情况下可能会出现死锁问题:
- 并发读写冲突:当多个事务同时读取和写入同一行数据时,可能会导致死锁问题。例如,事务A先获取了锁并读取了某一行数据,同时事务B也需要读取该行数据,但事务A还未释放锁,导致事务B无法继续执行,从而可能导致死锁。
- 加锁顺序不一致:当事务在执行过程中获取锁的顺序不一致时,也可能会导致死锁。例如,事务A先锁住了表A的某一行,然后想要锁住表B的某一行;而事务B先锁住了表B的某一行,然后想要锁住表A的某一行。这种情况下,两个事务可能会因为互相等待对方释放锁而发生死锁。
- 高并发场景:当有大量并发的事务同时请求锁资源时,可能增加了发生死锁的概率。特别是在数据库设计不合理或应用程序并发控制不当的情况下,死锁的发生可能更为频繁。
- 锁超时设置不合理:如果在事务中设置了过长的锁超时时间,那么在并发量较大的情况下,可能会导致事务持有锁的时间过长,从而增加了死锁发生的可能性。
解决MySQL死锁问题的方法有很多,以下是一些常见的方法:
- 死锁检测和处理: MySQL的InnoDB存储引擎可以自动检测死锁,并回滚其中一个事务,释放资源,使其他事务能够继续执行。应用程序可以通过监控错误日志来获取有关死锁的信息,并采取适当的措施来处理。
- 优化事务和锁策略: 在设计数据库架构时,应该合理设置事务的隔离级别、锁的粒度和加锁顺序。例如,尽量使用较低的隔离级别,减少锁的持有时间,以及确保所有事务加锁的顺序一致。
- 提高并发能力: 通过增加硬件资源(例如内存、磁盘)或者优化查询语句的性能,可以提高数据库的并发能力,从而减少发生死锁的可能性。
- 减少事务时间: 尽量在事务内完成尽可能少的工作,减少事务的持有时间,以便其他事务能够更快地获得所需的锁资源。
- 设置超时时间:MySQL的InnoDB存储引擎通过参数innodb_lock_wait_timeout来设置锁等待的时间,超过这个时间后会报错并释放锁资源。默认的超时时间是50秒。通过适当调整这个超时时间,可以在一定程度上减少死锁发生的可能性。
手写个sql死锁,如果字段非索引会发生死锁吗(2023 快手)
SQL死锁通常发生在两个或更多个事务相互等待对方释放锁时。下面是一个简单的MySQL示例,演示了如何产生一个死锁。假设我们有一个名为students的表,该表有id和name两个字段。
CREATE TABLE students (
id INT PRIMARY KEY,
name VARCHAR(50)
);
INSERT INTO students (id, name) VALUES (1, 'Alice');
INSERT INTO students (id, name) VALUES (2, 'Bob');
现在假设我们有两个并发的事务:
事务1:
START TRANSACTION;
UPDATE students SET name='Charlie' WHERE id=1;
-- 事务1在这里暂停,等待事务2
UPDATE students SET name='David' WHERE id=2;
COMMIT;
事务2:
START TRANSACTION;
UPDATE students SET name='Emily' WHERE id=2;
-- 事务2在这里暂停,等待事务1
UPDATE students SET name='Frank' WHERE id=1;
COMMIT;
这两个事务会造成死锁,因为事务1锁定了id=1的记录,而事务2锁定了id=2的记录。然后,它们都等待对方释放锁。
如果字段非索引会发生死锁吗?
实际上非索引字段可能会增加发生死锁的机会。这是因为在非索引字段上执行更新或者锁定操作通常需要全表扫描,这将锁定更多的行。这样,与其他事务的锁竞争可能性就更高了,从而更容易导致死锁。
然而,要注意的是,是否会发生死锁还取决于很多其他因素,包括数据库管理系统的内部机制、事务的隔离级别等等。所以,即使是非索引字段也不一定总是会导致死锁。但是,使用索引通常可以减少全表扫描和锁竞争,从而降低死锁的风险。
♨️ Redis
Redis string底层的结构?(2023 美团)
Redis 的字符串是一个动态字符串实现,它能够容纳任意长度的二进制安全的字符串。这意味着在 Redis 中,你不仅可以保存例如 "Hello, World!" 这样的字符串,还可以保存 JPEG 图像或者任何其他二进制数据。
在底层,Redis 的字符串是由以下结构表示的:
struct sdshdr {
// 保存字符串长度的字节大小
int len;
// 保存未使用的字节大小,这样当字符串需要扩展时可以避免不必要的重新分配
int free;
// 实际的字符串数据,这是一个字符数组
char buf[];
};
这里的 buf 字段是一个柔性数组(flexible array member)。实际的数据长度比 buf 的大小更大,这取决于 len 字段的值。free 字段表示 buf 后面有多少未使用的字节,这使得字符串追加变得更加高效。
这种动态字符串结构意味着:
- 字符串可以在不重新分配内存的情况下增长,只要
free字段所示的未使用空间允许。 - 字符串可以包含二进制数据,因为它们是二进制安全的。
- 字符串可以知道其长度,因为
len字段提供了这一信息,这意味着取长度是 O(1) 操作。
注意:这里给出的 sdshdr 结构是一个简化版本。在不同的 Redis 版本中,为了支持大字符串或优化存储,可能会有不同的实现或细微的差别。
Redis 分布式锁的实现?过期时间怎样设置的?(2023 美团)
Redis 分布式锁通常使用 SETNX(Set if Not eXists)或者 SET 命令配合某些参数来实现。这种锁可以保证在分布式系统中的多个节点之间的互斥性。
以下是使用 Redis 实现分布式锁的基本步骤:
- 加锁:
- 使用
SETNX lock:key value尝试设置一个锁。如果返回1,表示获取锁成功。如果返回0,表示其他客户端已经持有这个锁。 - 为了避免死锁(例如,持有锁的客户端崩溃导致其他客户端永远无法获取锁),你需要给锁设置一个过期时间。这可以通过
EXPIRE命令实现,但更安全的方法是使用SET命令的PX或EX选项。例如:SET lock:key value NX PX 30000会尝试设置一个锁,它在 30 秒后过期。
- 使用
- 执行业务操作:
- 如果成功获得锁,执行需要保护的业务操作。
- 解锁:
- 使用
DEL lock:key来释放锁。 - 为了确保只有锁的持有者可以释放锁(避免误解锁),释放锁的操作应该是原子的。这通常使用 Redis 的 Lua 脚本实现。脚本会检查锁的值是否与期望相匹配,只有在匹配的情况下才删除它。
- 使用
设置锁的过期时间是一个权衡:
- 太短:业务操作可能没有完成就已经过期,这可能会导致其他客户端在当前操作还在进行时获得锁。
- 太长:如果持有锁的客户端崩溃,其他客户端可能需要等待很长时间才能获取锁。
因此,设置的过期时间应该比预期的业务操作时间稍微长一些,但也不宜过长。
注意:Redis 的 Redlock 算法是一个更复杂、更健壮的分布式锁实现。如果需要在多个 Redis 实例或集群之间实现真正的分布式锁,可以考虑使用这个算法。
redis怎么实现分布式锁 set nx命令有什么问题 如何解决?(2023小红书)
Redis实现分布式锁的基本思路是使用SET命令的NX(Not eXists)选项。NX选项表示只有当键不存在时,才会设置键值对。这样可以确保在分布式环境中,只有一个客户端能够成功地获取锁。以下是一个简单的示例:
SET lock_key some_value NX PX 30000
这个命令尝试设置一个名为lock_key的键,值为some_value,并且使用NX选项。PX选项表示设置一个过期时间,单位为毫秒,在这个例子中是30000毫秒(30秒)。 然而,使用SET NX命令实现分布式锁存在一些问题:
- 非原子操作:在某些情况下,客户端可能在设置锁和设置过期时间之间崩溃,导致锁永远不会被释放。这可以通过使用SET命令的PX选项来解决,它可以在设置锁的同时设置过期时间,确保操作是原子的。
- 无法解决锁超时问题:如果持有锁的客户端在锁过期之前没有完成任务,其他客户端可能会获取到锁,导致并发问题。为了解决这个问题,可以在获取锁时设置一个唯一的值(例如UUID),并在释放锁时检查该值。这样可以确保只有锁的持有者才能释放锁。
- 无法解决锁释放问题:如果持有锁的客户端在释放锁之前崩溃,锁可能永远不会被释放。为了解决这个问题,可以使用一个后台线程定期检查并释放过期的锁。
- 无法实现公平锁:SET NX命令无法保证公平性,即等待时间最长的客户端不一定能够优先获取锁。要实现公平锁,可以使用Redis的LIST数据结构,将等待锁的客户端按照先进先出(FIFO)的顺序排队。 综上所述,虽然SET NX命令可以实现基本的分布式锁功能,但在实际应用中可能需要考虑更多的问题。为了解决这些问题,可以使用成熟的Redis分布式锁库,如Redlock。Redlock提供了一个更加健壮和可靠的分布式锁实现,可以解决上述问题
什么情况使用 redis 反而降低性能(2023 完美世界)
- 数据集过大:Redis 将数据存储在内存中,如果数据集过大,超出了服务器可用内存的限制,就会导致 Redis 使用交换空间(swap space)或者频繁地从磁盘加载数据,从而严重影响性能。
- 内存碎片化:当 Redis 频繁地进行写入、更新和删除操作时,可能会导致内存碎片化。这会导致 Redis 需要更多的内存来存储相同的数据,最终导致性能下降。
- 大量的键过期操作:当 Redis 中有大量的键需要过期处理时,Redis 会执行定期清理操作来删除过期的键。如果这个清理操作耗时较长,会导致 Redis 在执行其他操作时的性能下降。
- 高并发写入操作:当有大量的并发写入操作时,Redis 可能会因为竞争条件而降低性能。这种情况下,可以考虑使用 Redis 的事务功能来减少竞争并发。
- 复杂的数据结构操作:Redis 提供了多种复杂的数据结构,如列表、集合和有序集合等。当对这些数据结构进行复杂的操作时,例如对大型列表进行频繁的插入和删除操作,可能会导致性能下降。
需要注意的是,这些情况并不意味着 Redis 总是会降低性能,而是在特定的场景下可能会出现性能下降的情况。为了优化 Redis 的性能,可以根据具体的情况进行调整和优化,例如增加内存、合理设置过期时间、使用合适的数据结构等。
参考资料:
Redis大key如何解决(2023 滴滴)
Redis大key通常指的是存储在Redis中的数据结构(例如字符串、列表、集合、哈希表和有序集合)的数据量特别大的key。例如,一个列表中的元素数量巨大,或者一个哈希表的字段数量很多。这些大key可能会导致在执行某些操作时消耗过多的CPU和内存资源,进而影响Redis的性能。 例如:字符串(String):一个字符串value的长度非常大,例如超过10KB。
SET bigkey "a very large string....." # string长度非常大
列表(List):列表中的元素数量非常多,例如超过10000个。
LPUSH bigkey item1 item2 item3 ... item10001 # 列表元素数量非常多
哈希(Hash):哈希中的字段数量非常多,例如超过10000个。
HMSET bigkey field1 value1 field2 value2 ... field10001 value10001 # 哈希字段数量非常多
以上的数值(例如10KB,10000个等)仅作为参考,具体定义大key的阈值需要根据实际业务和Redis的配置来决定。如果这些key对Redis的性能产生了影响,就应当考虑对其进行优化。
什么是大key总结
- String 类型的值大于 10 KB;
- Hash、List、Set、ZSet 类型的元素的个数超过 5000个;
大 key 会造成什么问题?
大 key 会带来以下四种影响:
- 客户端超时阻塞。由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
- 引发网络阻塞。每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
- 阻塞工作线程。如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
- 内存分布不均。集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大。
如何找到大 key ?
- redis-cli --bigkeys 查找大key
可以通过 redis-cli --bigkeys 命令查找大 key:
redis-cli -h 127.0.0.1 -p6379 -a "password" -- bigkeys
使用的时候注意事项:
- 最好选择在从节点上执行该命令。因为主节点上执行时,会阻塞主节点;
- 如果没有从节点,那么可以选择在 Redis 实例业务压力的低峰阶段进行扫描查询,以免影响到实例的正常运行;或者可以使用 -i 参数控制扫描间隔,避免长时间扫描降低 Redis 实例的性能。 该方式的不足之处:
- 这个方法只能返回每种类型中最大的那个 bigkey,无法得到大小排在前 N 位的 bigkey;
- 对于集合类型来说,这个方法只统计集合元素个数的多少,而不是实际占用的内存量。但是,一个集合中的元素个数多,并不一定占用的内存就多。因为,有可能每个元素占用的内存很小,这样的话,即使元素个数有很多,总内存开销也不大;
- 使用 SCAN 命令查找大 key 使用 SCAN 命令对数据库扫描,然后用 TYPE 命令获取返回的每一个 key 的类型。 对于 String 类型,可以直接使用 STRLEN 命令获取字符串的长度,也就是占用的内存空间字节数。 对于集合类型来说,有两种方法可以获得它占用的内存大小:
- 如果能够预先从业务层知道集合元素的平均大小,那么,可以使用下面的命令获取集合元素的个数,然后乘以集合元素的平均大小,这样就能获得集合占用的内存大小了。List 类型:LLEN 命令;Hash 类型:HLEN 命令;Set 类型:SCARD 命令;Sorted Set 类型:ZCARD 命令;
- 如果不能提前知道写入集合的元素大小,可以使用 MEMORY USAGE 命令(需要 Redis 4.0 及以上版本),查询一个键值对占用的内存空间。
- 使用 RdbTools 工具查找大 key 使用 RdbTools 第三方开源工具,可以用来解析 Redis 快照(RDB)文件,找到其中的大 key。 比如,下面这条命令,将大于 10 kb 的 key 输出到一个表格文件。
rdb dump.rdb -c memory --bytes 10240 -f redis.csv
如何删除大 key
删除操作的本质是要释放键值对占用的内存空间,不要小瞧内存的释放过程。
释放内存只是第一步,为了更加高效地管理内存空间,在应用程序释放内存时,操作系统需要把释放掉的内存块插入一个空闲内存块的链表,以便后续进行管理和再分配。这个过程本身需要一定时间,而且会阻塞当前释放内存的应用程序。
所以,如果一下子释放了大量内存,空闲内存块链表操作时间就会增加,相应地就会造成 Redis 主线程的阻塞,如果主线程发生了阻塞,其他所有请求可能都会超时,超时越来越多,会造成 Redis 连接耗尽,产生各种异常。
因此,删除大 key 这一个动作,我们要小心。具体要怎么做呢?这里给出两种方法:
- 分批次删除
- 异步删除(Redis 4.0版本以上)
- 分批次删除
对于删除大 Hash,使用 hscan 命令,每次获取 100 个字段,再用 hdel 命令,每次删除 1 个字段。
Python代码:
def del_large_hash():
r = redis.StrictRedis(host='redis-host1', port=6379)
large_hash_key ="xxx" #要删除的大hash键名
cursor = '0'
while cursor != 0:
# 使用 hscan 命令,每次获取 100 个字段
cursor, data = r.hscan(large_hash_key, cursor=cursor, count=100)
for item in data.items():
# 再用 hdel 命令,每次删除1个字段
r.hdel(large_hash_key, item[0])
对于删除大 List,通过 ltrim 命令,每次删除少量元素。
Python代码:
def del_large_list():
r = redis.StrictRedis(host='redis-host1', port=6379)
large_list_key = 'xxx' #要删除的大list的键名
while r.llen(large_list_key)>0:
#每次只删除最右100个元素
r.ltrim(large_list_key, 0, -101)
对于删除大 Set,使用 sscan 命令,每次扫描集合中 100 个元素,再用 srem 命令每次删除一个键。
Python代码:
def del_large_set():
r = redis.StrictRedis(host='redis-host1', port=6379)
large_set_key = 'xxx' # 要删除的大set的键名
cursor = '0'
while cursor != 0:
# 使用 sscan 命令,每次扫描集合中 100 个元素
cursor, data = r.sscan(large_set_key, cursor=cursor, count=100)
for item in data:
# 再用 srem 命令每次删除一个键
r.srem(large_size_key, item)
对于删除大 ZSet,使用 zremrangebyrank 命令,每次删除 top 100个元素。
Python代码:
def del_large_sortedset():
r = redis.StrictRedis(host='large_sortedset_key', port=6379)
large_sortedset_key='xxx'
while r.zcard(large_sortedset_key)>0:
# 使用 zremrangebyrank 命令,每次删除 top 100个元素
r.zremrangebyrank(large_sortedset_key,0,99)
- 异步删除 从 Redis 4.0 版本开始,可以采用异步删除法,用 unlink 命令代替 del 来删除。 这样 Redis 会将这个 key 放入到一个异步线程中进行删除,这样不会阻塞主线程。 除了主动调用 unlink 命令实现异步删除之外,我们还可以通过配置参数,达到某些条件的时候自动进行异步删除。 主要有 4 种场景,默认都是关闭的:
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del
noslave-lazy-flush no
它们代表的含义如下:
- lazyfree-lazy-eviction:表示当 Redis 运行内存超过 maxmeory 时,是否开启 lazy free 机制删除;
- lazyfree-lazy-expire:表示设置了过期时间的键值,当过期之后是否开启 lazy free 机制删除;
- lazyfree-lazy-server-del:有些指令在处理已存在的键时,会带有一个隐式的 del 键的操作,比如 rename 命令,当目标键已存在,Redis 会先删除目标键,如果这些目标键是一个 big key,就会造成阻塞删除的问题,此配置表示在这种场景中是否开启 lazy free 机制删除;
- slave-lazy-flush:针对 slave (从节点) 进行全量数据同步,slave 在加载 master 的 RDB 文件前,会运行 flushall 来清理自己的数据,它表示此时是否开启 lazy free 机制删除。
建议开启其中的 lazyfree-lazy-eviction、lazyfree-lazy-expire、lazyfree-lazy-server-del 等配置,这样就可以有效的提高主线程的执行效率。
解决
- 对大Key进行拆分:将一个Big Key拆分为多个key-value这样的小Key,并确保每个key的成员数量或者大小在合理范围内,然后再进行存储,通过get不同的key或者使用mget批量获取。
- 对大Key进行清理:对Redis中的大Key进行清理,从Redis中删除此类数据。Redis自4.0起提供了UNLINK命令,该命令能够以非阻塞的方式缓慢逐步的清理传入的Key,通过UNLINK,你可以安全的删除大Key甚至特大Key。
- 监控Redis的内存、网络带宽、超时等指标:通过监控系统并设置合理的Redis内存报警阈值来提醒我们此时可能有大Key正在产生,如:Redis内存使用率超过70%,Redis内存1小时内增长率超过20%等。
- 定期清理失效数据:如果某个Key有业务不断以增量方式写入大量的数据,并且忽略了其时效性,这样会导致大量的失效数据堆积。可以通过定时任务的方式,对失效数据进行清理。
- 压缩value:使用序列化、压缩算法将key的大小控制在合理范围内,但是需要注意序列化、反序列化都会带来一定的消耗。如果压缩后,value还是很大,那么可以进一步对key进行拆分。
参考:
什么是热key?如何解决热key问题(2023 滴滴,2023 小红书)
小红书的问法是:Redis中,如果单key过热怎么处理?
热key是指在Redis中被频繁访问的key。当大量的请求都集中在一小部分key上时,就会形成热key。这可能导致Redis服务器负载不均,甚至可能导致部分业务瘫痪。
如何发现热key?
- 凭借业务经验,预估热 Key 出现:根据业务系统上线的一些活动和功能,我们是可以在某些场景下提前预估热
Key的出现的,比如业务需要进行一场商品秒杀活动,秒杀商品信息和数量一般都会缓存到Redis中,这种场景极有可能出现热Key问题的。 - 客户端进行收集:一般我们在连接
Redis服务器时都要使用专门的 SDK(比如:Java的客户端工具Jedis、Redisson),我们可以对客户端工具进行封装,在发送请求前进行收集采集,同时定时把收集到的数据上报到统一的服务进行聚合计算。 - 在代理层进行收集:如果所有的
Redis请求都经过Proxy(代理)的话,可以考虑改动Proxy代码进行收集,思路与客户端基本类似。 - hotkeys 参数:
Redis在4.0.3版本中添加了 hotkeys 查找特性,可以直接利用redis-cli --hotkeys获取当前keyspace的热点key,实现上是通过scan + object freq完成的。 - monitor 命令:
monitor命令可以实时抓取出Redis服务器接收到的命令,通过redis-cli monitor抓取数据,同时结合一些现成的分析工具,比如 redis-faina,统计出热 Key。 - Redis 节点抓包分析:
Redis客户端使用TCP协议与服务端进行交互,通信协议采用的是RESP协议。自己写程序监听端口,按照RESP协议规则解析数据,进行分析。或者我们可以使用一些抓包工具,比如tcpdump工具,抓取一段时间内的流量进行解析。
如何解决热key?
常用方案:
【强力推荐】分片:这是一种常见的解决方式,将数据分散到多个 Redis 实例中去,这样可以分散访问压力,避免单个 Redis 实例被过度访问。之所以出现热
Key,是因为有大量的对同一个Key的请求落到同一个Redis实例上,如果我们可以有办法将这些请求打散到不同的实例上,防止出现流量倾斜的情况,那么热Key问题也就不存在了。那么如何将对某个热
Key的请求打散到不同实例上呢?我们就可以通过热Key备份的方式,基本的思路就是,我们可以给热Key加上前缀或者后缀,把一个热Key的数量变成Redis实例个数N的倍数M,从而由访问一个RedisKey变成访问N * M个RedisKey。N * M个RedisKey经过分片分布到不同的实例上,将访问量均摊到所有实例。二级缓存(本地缓存):当出现热
Key以后,把热Key加载到系统的JVM中。后续针对这些热Key的请求,会直接从JVM中获取,而不会走到Redis层。这些本地缓存的工具很多,比如Ehcache,或者Google Guava中Cache工具,或者直接使用HashMap作为本地缓存工具都是可以的。
其他解决方案:
- MemCached / Redission + Redis主从复制:这个方案也可以说是分片的具体实现了[2]。复制热点数据到多个节点,这样可以分摊读取压力。Redis 具有内建的主从复制功能,可以使用它来实现热点数据的复制。Memcached 不直接支持复制,但你可以在上层实现。同样,Redission 自身并不直接解决热点键(HotKeys)问题,但支持多种集群模式,包括分片,可以将数据更均匀地分布在多个节点上,从而降低热点键对单个节点的影响。
- 代理+读写分离+SLB(服务器负载均衡(Server Load Balancing)):
- 负载均衡在SLB层实现
- 在代理层实现读写分离和自动路由
- 写请求由主节点处理
- 读请求由从节点处理
- HA(High Availability,互联网黑话)在从节点和主节点上实现
参考:
- https://dzone.com/articles/redis-hotspot-key-discovery-and-common-solutions
- https://dongzl.github.io/2021/01/14/03-Redis-Hot-Key/index.html
- https://abhivendrasingh.medium.com/understanding-and-solving-hotkey-and-bigkey-and-issues-in-redis-1198f98b17a5
- https://developerknow.com/what-is-the-hot-key-problem-in-redis-how-to-solve-the-hot-key-problem/
- https://www.programmersought.com/article/54911114988/
讲下Redis的ZSet(2023 滴滴)
Redis的ZSet(有序集合)是一种数据结构,它与普通的集合相比,在存储每个元素时关联了一个分数(score)。这个分数用于对集合中的元素进行排序,并且每个元素都是唯一的。当多个字符串具有相同分数时,这些字符串按字典顺序排列。一些有序集合的用途包括:
- 排行榜。例如,您可以使用有序集合轻松地维护大型在线游戏中得分最高的有序列表。
- 速率限制器。特别是,您可以使用有序集合构建滑动窗口速率限制器,以防止过多的API请求。
ZSet中的每个元素都有一个分数,根据分数的大小对元素进行排序。不同的元素可以有相同的分数,但每个元素在集合中必须是唯一的。 Redis内部使用了跳跃表(skip list)和压缩列表(ziplist)两种数据结构来实现ZSet。跳跃表用于提供有序性,而散列表用于快速查找元素。 Redis的ZSet提供了高效的操作,包括插入、删除和查找操作。这些操作的时间复杂度通常为O(log N),其中N是ZSet中元素的数量。
参考:
ZSet的范围查询的时间复杂度是多少(2023 滴滴)
Redis的ZSet范围查询的时间复杂度是O(log N + M),其中N是ZSet中的元素数量,M是范围内的元素数量。
具体来说,范围查询是通过指定最小和最大分数值来检索元素。Redis内部使用跳跃表(skip list)这种有序数据结构来存储ZSet,并且通过跳跃表可以高效地进行范围查询。
在进行范围查询时,Redis首先会通过二分查找在跳跃表中找到最小分数大于等于指定最小分数的节点,然后从这个节点开始,按照指定的最大分数遍历跳跃表,直到找到最后一个分数小于等于指定最大分数的节点。这个过程的时间复杂度是O(log N)。
然后,Redis会从找到的节点开始向后遍历,并收集在范围内的元素,直到遍历完所有符合条件的元素或达到范围内的元素数量上限。这个过程的时间复杂度是O(M),其中M是范围内的元素数量。
综上所述,Redis的ZSet范围查询的时间复杂度是O(log N + M),其中N是ZSet中的元素数量,M是范围内的元素数量。请注意,这是一种平均情况下的时间复杂度,具体的性能还受到硬件环境和实际数据分布的影响。
redis 批处理?(2023 阿里实习)
Redis 批处理通常指的是通过使用 Redis 的管道 (pipeline) 功能来一次性执行多个命令。这样做可以提高效率,因为它减少了客户端与服务器之间的通信开销。在 Redis 的管道中,客户端会一次性发送多个命令,然后 Redis 服务器依次执行这些命令并返回结果。
使用 Redis 批处理时,请注意以下几点:
- 批处理并不保证原子性,这意味着如果管道中的某个命令失败,其他命令仍可能执行成功。如果你需要原子性,可以考虑使用 Redis 的事务功能。
- 由于管道中的命令是按顺序执行的,因此命令之间可能存在依赖关系。在这种情况下,可以通过在添加命令时检查前一个命令的结果来处理这些依赖关系。
- 在添加大量命令到管道时,要注意内存使用情况。如果可能的话,可以分批执行管道,以避免一次性执行过多的命令。
在 Java 中,可以使用 Jedis 库来进行 Redis 批处理操作。Jedis 是一个用于操作 Redis 的 Java 客户端库。请先确保已将 Jedis 添加到项目的依赖中。如果使用 Maven,可以在 pom.xml 文件中添加以下依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
示例
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
import redis.clients.jedis.Response;
public class RedisBatchExample {
public static void main(String[] args) {
// 连接到 Redis 服务器
Jedis jedis = new Jedis("localhost", 6379);
// 创建一个管道
Pipeline pipeline = jedis.pipelined();
// 向管道中添加命令
pipeline.set("key1", "value1");
pipeline.set("key2", "value2");
pipeline.set("key3", "value3");
// 执行管道中的命令
pipeline.sync();
// 获取执行结果
String value1 = jedis.get("key1");
String value2 = jedis.get("key2");
String value3 = jedis.get("key3");
// 输出结果
System.out.println("key1: " + value1);
System.out.println("key2: " + value2);
System.out.println("key3: " + value3);
// 关闭连接
jedis.close();
}
}
RDB fork子进程去写日志的时候,如果宕机了是不是有数据就丢失了(2023 小红书)
是的,当Redis使用RDB持久化策略时,如果Redis服务在RDB进程fork出子进程写RDB文件的时候宕机,那么此时还没有写到RDB文件的数据将会丢失。
Redis RDB的工作原理是:
- Redis主进程fork出一个子进程
- 子进程负责将数据库快照写入到硬盘上的RDB文件中
- 如果在此期间Redis主进程被kill,那么正在被子进程写入RDB文件的那部分数据将丢失
- RDB文件写入完成后,子进程退出,Redis主进程继续服务客户端请求
所以,RDB持久化最大的问题就是可能导致数据丢失,虽然概率很小,但数据依然存在一定风险。
redis服务器挂了后,redis缓存问题考虑过吗?(2023 快手)
以下是一些需要考虑的关键点:
- 数据丢失:如果你没有为Redis设置持久化策略(如RDB或AOF),那么在Redis宕机后重启时,可能会丢失数据。
- 高可用性:可以使用Redis Sentinel或者Redis Cluster来提高Redis的高可用性,这样即使某个Redis实例宕机,系统仍然可以正常运行。
- 应用程序处理:应用程序需要能够处理Redis宕机的情况。这可能包括重新连接尝试、回退到其他缓存机制或直接从数据库查询数据。
- 监控与报警:通过监控工具实时了解Redis的运行状态,并在出现问题时迅速发出报警,以便及时处理。
- 备份与恢复:定期备份Redis数据,并确保在出现问题时可以快速恢复。
Redis切片集群中,数据量多了,加实例还是加内存,为什么?加实例要注意什么问题?(2023 得物)
加实例(水平扩展)
- 优点:
- 更好的分布负载:更多的实例意味着每个实例处理的请求更少。
- 更高的可用性:一个实例出问题不会影响其他实例。
- 更易于管理大数据量:通过增加实例数,你可以在多个硬件上分布数据和负载。
- 缺点:
- 复杂性增加:你需要管理更多的实例和可能更复杂的数据路由。
- 成本:需要更多的硬件和维护。
加内存(垂直扩展)
- 优点:
- 简单:你不需要改变代码或者重新配置你的应用。
- 低延迟:单个实例通常比多实例场景有更低的网络延迟。
- 缺点:
- 成本高:内存通常比其他硬件更贵。
- 可用性下降:如果这个实例出现问题,可能会影响更多的数据和服务。
- 扩展性限制:单个实例总会有内存和计算能力的上限。
综合考虑
- 如果你关心高可用性、分布式负载均衡,并且需要大规模扩展,那么增加实例通常是更好的选择。
- 如果你的应用是内存密集型而不是计算密集型,并且你想要最小化延迟,那么加内存可能是更合适的。
- 在选择之前,一定要做性能和成本的评估,以便找到最适合你需求的方案。
- 注意也可以两者结合,既增加实例也增加每个实例的内存,具体取决于你的需求和预算。
加实例需要注意问题:
- 数据迁移与重平衡
- 迁移计划: 在添加新实例后,现有的数据需要被重新平衡到新的实例上。这一过程应该事先规划好,以最小化对业务的影响。
- 数据一致性: 在数据迁移过程中要确保数据的一致性,防止数据丢失或者重复。
- 资源和性能
- 硬件规格: 新加入的实例应具有与现有实例相似的硬件规格(CPU、内存等),以确保性能的一致性。
- 网络延迟: 新实例应部署在与现有实例网络延迟较低的位置,以避免成为性能瓶颈。
- 可用性与容错
- 主从配置: 如果使用主从配置,确保新实例也有相应的从实例,以提供高可用性。
- 数据备份: 在添加新实例之前和之后都应执行数据备份操作。
- 集群配置和元数据
- 更新配置: 集群的配置信息(例如,哪些实例负责哪些键的范围等)需要更新。
- 客户端更新: 如果客户端代码中硬编码了集群信息,那么添加新实例后,客户端可能需要更新。
- 监控与告警
- 性能监控: 在新实例添加之后,应增加相应的监控,以追踪其性能和健康状况。
- 告警设置: 应该为新实例设置相应的告警条件和阈值。
- 测试与验证
- 功能测试: 在正式投入使用前,要在测试环境中验证新实例的功能和性能。
- 回滚计划: 如果新实例出现问题,应准备好相应的回滚方案。
Redis的主库崩溃了会怎么样(2023 得物)
- 数据可用性:主库崩溃会导致数据不可用,直到主库恢复或者手动切换到一个备库(Slave)。
- 数据一致性:如果主库在崩溃前有尚未同步到备库的写操作,这些数据可能会丢失。
- 性能:备库通常用于读操作以减轻主库的压力。主库崩溃可能导致读操作性能下降,尤其是在高读取负载的系统中。
解决:
- 主从切换(Failover):手动或自动将一个备库提升为新的主库。
- 哨兵模式(Sentinel):Redis Sentinel 可以自动检测主库崩溃,并自动选举新的主库。
- 集群模式(Cluster):在Redis集群模式中,数据分布在多个主库中。一个主库的崩溃可能只影响到该主库负责的数据分片。
- 持久化:通过合适的持久化策略(如 RDB 快照或 AOF 日志文件)来最小化数据丢失。
- 监控和报警:使用工具如 Prometheus、Grafana 或其他监控工具来及时发现问题。
- 应用层重试和熔断机制:应用代码可以设计成在主库崩溃时尝试重新连接或者路由到备库。
- 负载均衡器:在多主或主-多从架构中,负载均衡器可以帮助重新路由流量。
- 备份和恢复:定期备份 Redis 数据,并在必要时进行恢复。
Redis数据更新成功,MySQL更新失败怎么办?(2023 用友)
事务:如果你使用的是支持事务的MySQL版本(例如InnoDB),可以尝试先在MySQL中开始一个事务,进行数据更新,然后更新Redis。如果Redis更新失败,可以回滚MySQL的事务,确保两者保持一致。
补偿策略:如果Redis更新成功,而MySQL更新失败,可以考虑再次尝试更新MySQL。如果多次尝试后MySQL仍然失败,则可以记录这个失败事件,以便稍后进行人工干预或通过其他自动化工具进行修复。
双写一致性策略:你可以使用一个队列或日志系统,例如Kafka,来记录需要在两个系统中进行的更改。然后,可以有一个消费者或工作进程从队列中读取更改,并确保它们在两个系统中都被应用。
缓存失效策略:当Redis数据更新成功而MySQL更新失败时,可以设置Redis的过期时间较短,使得在数据过期后从数据库中读取最新的值并回填到缓存中。这样,在MySQL更新失败的情况下,后续的读请求仍可以从数据库获取最新值。
Redis保存数据有什么安全性问题?(2023 用友)
存储问题:
- 明文传输:默认情况下,Redis 数据在网络中的传输是不加密的。
- 无身份验证:默认设置下,任何人都可以连接到 Redis 服务器并执行所有命令。
- 持久化问题:Redis 支持多种持久化机制,但如果配置不当,可能导致敏感数据泄漏。
- 代码注入:虽然风险较低,但由于 Redis 支持复杂的数据结构,不当的使用还是有注入攻击的风险。
- 配置风险:不当的配置(比如绑定所有IP地址或没有设置密码)可能会导致安全问题。
保存方式问题:
- RDB快照:RDB是一种定时保存策略,它会在指定的时间间隔内创建数据库的快照。这种方式可能会导致数据丢失的风险。如果在快照创建过程中发生系统崩溃或硬件故障,那么Redis将无法恢复到发生故障之前的那个状态,因为在快照创建后到故障发生的这段时间内的所有写操作都没有被记录下来。为了解决这个问题,你可以设置多个RDB快照,并在不同的时间间隔下执行。这样可以在一定程度上减少数据丢失的风险。
- AOF日志:AOF日志是Redis将每次写操作都记录到一个文件中,当需要恢复数据时,只需读取该文件并将内容重新执行一遍即可。然而,AOF日志可能会变得非常大,这可能导致磁盘空间不足的问题。此外,如果AOF日志文件损坏或者丢失,那么Redis将无法恢复数据。为了解决这些问题,你应该定期对AOF日志进行压缩,以减小其大小;同时,确保在多个地方存储备份AOF日志文件,以防万一。
在分布式锁中,Redis中A申请锁1min,30s B能获取这个锁吗?(2023 得物)
在分布式锁中,如果A已经成功申请了一个锁并设置了1分钟(60秒)的过期时间,那么在这60秒内,B是不能获取到这个锁的,除非A主动释放了这个锁或者锁因某种原因提前过期了。
如果A持有的锁在1分钟内没有被释放或者过期,那么B必须等到这1分钟过后才有可能获取到这个锁。
redisson底层是怎么实现的(2023 快手)
Redisson底层的实现原理包括以下几个方面:
- 连接管理:Redisson通过连接池管理与Redis服务器的连接,使用NIO(非阻塞I/O)技术进行网络通信,提高通信效率和吞吐量。
- 序列化:Redisson通过序列化技术将Java对象转换为字节流进行存储和传输。常用的序列化技术包括Java内置的序列化(Serializable)和常用的第三方序列化库,如FastJson、Kryo等。
- 命令封装:Redisson封装了Redis服务器的各种命令,比如字符串操作、哈希表操作、列表操作等,以便开发者可以直接调用相应的方法进行操作。
- 分布式锁:Redisson实现了分布式锁的功能,通过Lua脚本在Redis服务器上执行加锁和解锁的操作,确保分布式环境下的数据一致性和并发控制。
- 分布式对象:Redisson提供了分布式对象的支持,如分布式集合、分布式列表、分布式映射等。它们通过将数据存储在Redis服务器上,实现了数据的分布式共享和协同操作。
♻️ JVM
堆是如何管理内存的(2023 快手)
- 堆的划分:在JVM中,堆被划分为年轻代(Young Generation)和老年代(Old Generation)。年轻代又被划分为Eden区和两个Survivor区(S0和S1)。新创建的对象首先在Eden区创建,当Eden区满时,会触发Minor GC进行垃圾回收。存活的对象会被移动到Survivor区,当Survivor区也满时,对象会被移动到老年代。当老年代满了,会触发Major GC或者Full GC。
- 垃圾回收:JVM通过垃圾回收机制自动回收不再使用的对象以释放内存。JVM的垃圾回收算法包括标记-清除、复制、标记-整理、分代收集等。
- 内存分配:当创建新对象时,JVM会在堆中为其分配内存。JVM有一个指针叫做TLAB(Thread Local Allocation Buffer),用于在特定的线程中分配对象,这样可以避免线程之间的竞争。如果对象很大,可能直接在老年代分配。
- 堆大小调整:JVM的堆大小可以动态调整,以适应程序的需求。可以通过启动参数设置最小堆大小(-Xms)和最大堆大小(-Xmx)。如果程序需要更多内存,堆可以扩展到最大堆大小;如果程序需要的内存减少,堆可以收缩到最小堆大小。
跨代引用问题怎么解决(2023 快手)
跨代引用问题是指在JVM内存模型中,年轻代的对象引用老年代的对象,或者老年代的对象引用年轻代的对象。这在垃圾回收时可能会导致一些问题,因为垃圾回收通常会针对年轻代和老年代分别进行。
为了解决这个问题,JVM引入了一个叫做 "卡表"(Card Table) 的数据结构。卡表的主要作用是快速找到老年代中被年轻代对象引用的对象,从而在进行Minor GC时,减少全堆扫描的开销。
卡表概览:卡表是Java虚拟机(JVM)中加速查找引用的一种辅助数据结构。表中每个条目对应于Java堆的一小部分,这里我称为小块。当老年代中的一个对象写入/更新对年轻代中的一个对象的引用时,这个操作会通过一种叫做写屏障的东西。当JVM看到这些写屏障时,它会更新卡片表中的相应条目。
- 写屏障:垃圾收集器用来跟踪对象引用更改的一种机制。它是一段代码(JVM实现的),每当对象引用更新时就会运行。写屏障确保垃圾收集器可以跟踪堆中的所有引用,并确定哪些对象仍在使用,哪些没有。
- 当写入屏障发现语句
some_obj.field = other_obj;将年轻指针存储在旧对象中时,它会这样做:card_table[(&old_obj - start_of_heap) >> K] = 1;- 其中
&old_obj是现在有一个年轻代指针的对象的地址(它已经在寄存器中,因为它刚刚被确定引用旧对象)。 在次要GC期间,垃圾收集器查看卡表以确定要扫描哪些堆区域以查找年轻指针。
- for i from 0 to (heap_size >> K):
- if card_table[i]: scan heap[i << K .. (i + 1) << K] for young pointers
卡表将老年代的内存分为多个小块(通常为512字节),每个小块对应卡表中的一项,当老年代中的某个小块内存被修改时(例如年轻代的对象引用了该小块中的某个对象),对应的卡表项就被标记为 "脏(dirty)" 。
在进行Minor GC(清理年轻代)时,JVM只需要检查标记为"脏"的卡表项对应的内存块,找出被年轻代对象引用的老年代对象,而无需扫描整个老年代。这样就大大提高了垃圾回收的效率。
至于老年代的对象引用年轻代的对象,这在JVM的分代回收策略中是不推荐的,因为会增加垃圾回收的复杂性。如果确实存在这种情况,一般需要在进行垃圾回收时,遍历老年代找到所有引用年轻代的对象,确保不会误删。
参考文献如下:
- https://stackoverflow.com/questions/19154607/how-actually-card-table-and-writer-barrier-work 卡表和写屏障是如何工作的?
- https://tschatzl.github.io/2022/02/15/card-table-card-size.html Card Table Card Size Shenanigans
- https://www.mo4tech.com/jvm-card-table.html JVM Card Table
- https://www.cnblogs.com/hongdada/p/12016020.html JVM-卡表(Card Table)
- http://blog.ragozin.info/2011/06/understanding-gc-pauses-in-jvm-hotspots.html Alexey Ragozin
元空间还会存放什么东西?(2023 影石360)
- 类的元数据:这包括类的名字、方法、字段等信息。
- 常量池:包含了类的字面量(如文本字符串)和代码中的符号引用。
- 类加载器的数据:Java中的每个类加载器也都有相关的元数据存储在元空间中。
- 即时编译器的优化数据:即时编译器可能会在元空间中存储一些数据以提高运行时的性能。
- 运行时常量池:这是方法区的一部分,包含了编译期生成的各种字面量和符号引用。
对于static变量的理解?static变量分配内存的时候发生在哪个环节?(2023 影石360)
在Java中,static关键字用于修饰类的成员变量和方法。对于静态变量(static variable)和静态方法(static method),它们不依赖于任何实例,可以直接通过类名进行访问。
以下是关于静态变量的一些关键特性:
- 静态变量是类的所有实例共享的,即一个类的所有对象共享同一个静态变量。如果一个对象修改了一个静态变量,那么这个改变对其他所有对象都是可见的。
- 静态变量存在于方法区(Java 8之前)或元空间(Java 8及以后),而不是堆内存中。
- 静态变量在内存中只有一份存储空间。
- 静态变量在类加载的时候进行初始化,只会被初始化一次。
对于静态变量分配内存以及初始化的时间,它们发生在类加载的“初始化”阶段。类加载的过程主要包括加载、验证、准备、解析和初始化五个阶段:
- 加载:查找并加载类的二进制数据。
- 验证:确保被加载的类符合Java虚拟机规范,没有安全问题。
- 准备:为类的静态变量分配内存,并将其初始化为默认值。例如,对于类型为int的静态变量,它会被初始化为0。
- 解析:把类中的符号引用转换为直接引用。
- 初始化:为类的静态变量赋予正确的初始值。这是静态变量的初始值被赋值的地方。
因此,静态变量分配内存发生在“准备”阶段,而静态变量的初始化则发生在“初始化”阶段。
每次回收都要从GC ROOT开始吗?哪些对象可以作为GC root?类加载器可以作为GC root吗?(2023 快手)
是的,每次垃圾回收都会从GC Roots开始。GC Roots是垃圾回收算法开始工作的一组必要的"根"对象。
Java中可以作为GC Roots的对象包括:
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象。
- 方法区中类静态属性引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中JNI(即一般说的Native方法)引用的对象。
垃圾回收器在对堆进行回收前,会先从GC Roots开始对堆中的对象进行可达性分析。只有当对象在GC Roots到该对象之间没有任何引用链可达时(换句话说,GC Roots到该对象不可达),这个对象才会被判定为可回收的垃圾对象。
这种通过GC Roots进行可达性分析的方式,保证了只有真正不再使用的对象会被回收,从而避免了错误地回收仍在使用的对象。
类加载器(ClassLoader)可以作为垃圾回收(Garbage Collection,GC)的根(Roots)。在Java中,GC Roots 是垃圾收集器用来确定对象是否可以被安全回收的起始点。通常情况下,如果一个对象不能从GC Roots直接或者间接地被访问到,那么这个对象就是可以被回收的。
类加载器是一个很重要的GC Root。这是因为Class对象通常存储在永久代(Java 8之前)或者元空间(Java 8之后),并且Class对象包含对其类加载器的引用,同时还会引用它加载的其他类。这意味着,如果一个类加载器实例可以被直接或者间接访问到,则该类加载器加载的所有类以及这些类实例化的对象都不能被垃圾回收。
这也是为什么需要注意类加载器内存泄漏问题,特别是在一些使用了多个类加载器的环境中,例如各种Java EE容器,OSGi等,否则可能会导致OutOfMemoryError错误。
垃圾回收过程如何判断每个阶段已经完成,可以进入下一个阶段(2023 快手)
像是垃圾回收器如CMS(并发标记清除)和G1(Garbage-First)在进行垃圾回收时,会通过一系列的阶段来判断何时可以进入下一步。
CMS垃圾回收器: CMS垃圾回收器主要包含以下四个阶段:
- 初始标记(Initial Mark):标记GC Roots能直接关联的对象,此阶段需要暂停所有的其他线程,但是时间通常较短。
- 并发标记(Concurrent Mark):进行GC Roots Tracing的过程,也就是从GC Roots开始对堆中的对象进行可达性分析,此阶段可以与用户线程并发执行。
- 重新标记(Remark):修正并发标记期间因用户程序继续运行而导致标记产生变动的那一部分标记记录,防止数据不一致,此阶段需要暂停所有的其他线程。
- 并发清除(Concurrent Sweep):清除不再使用的对象,此阶段可以与用户线程并发执行。 CMS在每个阶段完成后会判断是否可以进入下一阶段。例如,在并发标记阶段,当所有从GC Roots开始可达的对象都被标记后,就可以进入重新标记阶段。
G1垃圾回收器: G1垃圾回收器将堆内存划分为多个小块(Region),每个小块可能属于Eden区、Survivor区或者Old区。G1的垃圾回收过程包括以下几个阶段:
- 初始标记(Initial Mark):标记所有的GC Roots能直接关联的对象,此阶段需要暂停所有的其他线程。
- 并发标记(Concurrent Mark):进行GC Roots Tracing的过程,此阶段可以与用户线程并发执行。
- 最终标记(Final Mark):修正并发标记期间因用户程序继续运行而导致标记产生变动的那一部分标记记录,此阶段需要暂停所有的其他线程。
- 筛选回收(Cleanup):首先统计各个Region的存活对象,并对Region进行排序,然后回收垃圾对象最多的Region。 类似地,G1在每个阶段完成后会判断是否可以进入下一阶段。例如,在并发标记阶段,当所有从GC Roots开始可达的对象都被标记后,就可以进入最终标记阶段。
总的来说,垃圾回收器在每个阶段的结束条件主要取决于当前阶段的任务是否完成,例如是否所有的对象都已经被标记,或者是否所有的垃圾都已经被清除。
什么时候会发生FULL GC?(2023 小红书)
每当堆满时,就会触发Full GC。在这种情况下,首先收集年轻代,然后收集老年代。如果老年代太满而无法接受年轻代的内容,则省略年轻代GC,并使用旧代GC以并行或串行方式收集完整堆。
另外:
- Young Generation 已满,而 Old Generation 中又没有足够的空间存活对象时,会触发 full gc。
- 已使用的内存超过最大堆内存(通过 -Xmx 设置)时,也会触发 full gc 以回收内存。
- 调用 System.gc() 方法时,如果 JVM 检测到 Old Generation 中有足够的垃圾需要清理,也会触发 full gc。
- Minor GC 完成后,如果 JVM 检测到 Old Generation 中有足够的垃圾需要清理,也会触发 full gc。
参考:
可以在代码中捕获oom异常吗?(2023 小红书)
可以通过代码捕获 OOM(OutOfMemory)异常。例如:
try {
// 可能触发 OOM 的代码
} catch (OutOfMemoryError e) {
System.out.println("Out of Memory");
}
当 JVM 的可用内存不足以满足应用的内存需求时,会抛出 OOM 异常。捕获这个异常可以让应用优雅地处理 OOM 错误,而不是直接崩溃。
能不能说一下堆区具体怎么划分,为什么这样划分(2023百度)
Java虚拟机(JVM)的堆区(Heap)是JVM所管理的最大的一块内存空间,也是Java内存管理中最关键的部分。它主要用于存放各种对象实例,包括Java类的实例和数组。
堆区的具体划分可能会随着不同的JVM实现(例如HotSpot、JRockit、IBM J9等)和版本有所不同,但一般来说,可以划分为以下几个部分:
- 新生代(Young Generation):新生代是堆内存中的一部分,主要存放新创建的对象。新生代又可以分为三部分:
- Eden区:这是新生代的主要部分,大部分新创建的对象首先在Eden区分配内存。
- Survivor区:Survivor区包括两个,通常称为From Survivor和To Survivor,用于存放从Eden区经过一次Minor GC后仍然存活的对象。
- 老年代(Old Generation):当对象在新生代Survivor区中经历了一定次数的GC后,或者Eden区没有足够空间进行分配时,对象会被晋升到老年代。老年代的空间通常比新生代大,用于存放长时间存活的对象。
- 永久代(Permanent Generation)/元空间(Metaspace):这部分内存用于存放JVM加载的类信息、常量、静态变量等数据。在Java 8之后,永久代被移除,改为使用元空间。
堆的这种划分方式主要基于一个观察到的现象,即大部分对象的生命周期都非常短,即“弱代假说”。基于此,JVM采用了分代回收的垃圾收集策略。
新生代中的对象生命周期较短,所以可以通过Minor GC更频繁地收集新生代区域。当Eden区满时,会触发Minor GC,清理掉那些已经死亡的对象,把仍然存活的对象移动到Survivor区,如果Survivor区也满了,就会将对象移动到老年代。
老年代中的对象一般存活时间较长,或者是Survivor空间无法容纳的大对象。因此,相比于新生代,老年代的GC(Major GC或Full GC)会相对少些,但每次GC时间会比Minor GC要长,因为需要对整个老年代进行整理。
永久代/元空间存放的数据类型(如类信息、常量)的生命周期与一般的Java对象有所不同,其内存管理也有特殊之处,比如类的卸载等情况。
这种内存划分和管理方式能够提高垃圾收集的效率,同时也减轻了Full GC的压力,提高了系统的性能和稳定性。
怎么释放一个用完的大对象的内存空间?(2023 阿里实习)
- 消除对象引用:首先,你需要确保没有任何活动的引用指向这个对象。这可能涉及将任何变量指向该对象的引用设置为null。
BigObject bigObject = new BigObject();
// Use bigObject
bigObject = null; // Helps to make bigObject eligible for GC
- 请求系统进行垃圾收集:虽然JVM会自动进行垃圾收集,但是在处理大对象时,你可能希望尽早地释放内存。为此,你可以使用System.gc()方法来请求JVM进行垃圾收集。但是,这只是一个建议,JVM可能不会立即响应。
System.gc(); // Suggests JVM to run the garbage collector
对于大对象,特别注意的是,频繁创建和销毁大对象可能导致内存碎片,这会影响垃圾收集的效率和程序的性能。如果可能,你可以尽量复用这些大对象,或者使用池化等技术来管理这些资源。
写查询语句的时候应该从哪些方面考虑来注意性能?(2023 阿里实习)
- 使用索引:索引可以极大地提升查询速度。理解你的查询是如何使用索引的,并且尽可能地使你的查询能够使用索引。
- 避免全表扫描:尽可能地避免全表扫描。这通常意味着你需要为经常用于查询的列创建索引。
- 减少返回的数据量:只查询你真正需要的数据。例如,使用 SELECT * 会返回所有列,这可能会浪费大量的I/O资源。尽可能只返回你需要的列。
- 过滤结果:在数据库层面过滤结果,而不是在应用层面过滤。例如,使用 WHERE 子句而不是在应用代码中过滤数据。
- 优化联接:如果需要联接多个表,确保你正确地创建了索引,并尽可能地减少联接的数量。
- 使用 LIMIT:如果可能,使用 LIMIT 语句来限制返回的数据量,特别是在只需要一部分结果的情况下。
- 避免复杂的子查询:尽可能避免复杂的子查询,因为它们可能导致性能问题。有时候,可以使用 JOIN 来代替子查询。
- 分析查询:使用 EXPLAIN 语句分析你的查询,看看它是如何在数据库中运行的。这可以帮助你找到可能的性能瓶颈。
以上只是一些基本的指南,每个具体的情况可能会有不同的优化策略。
怎么手动让 JAVA 虚拟机 OOM(2023 阿里实习)
为了手动让Java虚拟机(JVM)内存溢出(OutOfMemoryError),可以尝试在代码中创建一个很大的对象数组,以尽快耗尽JVM的可用内存。下面是一个简单的例子:
import java.util.ArrayList;
import java.util.List;
public class OOMExample {
public static void main(String[] args) {
List<byte[]> list = new ArrayList<>();
while (true) {
// 每次分配1MB的内存
byte[] memoryChunk = new byte[1024 * 1024];
list.add(memoryChunk);
System.out.println("Memory allocated: " + (list.size() * memoryChunk.length / (1024 * 1024)) + " MB");
}
}
}
程序会不断分配1MB的内存块直到JVM耗尽内存。不过请注意,这种方法并不是高效地触发OOM,因为JVM的垃圾回收器可能会在某个时刻释放部分内存。但这个例子通常足以触发一个内存溢出错误。
在运行这个程序时,可能需要根据您的机器限制JVM的内存。例如,若要将最大内存限制为256MB,可以使用以下命令:
java -Xmx256m OOMExample
如果频繁出现Full GC该怎么排查(2023 小红书)
频繁出现Full GC的原因有以下几个:
- 内存溢出:应用程序申请的内存超过了JVM的最大可用内存,导致GC线程频繁执行Full GC来回收内存。可以通过检查JVM启动参数中-Xmx的值来确认是否内存溢出,如果是的话可以适当增加该值。
- 老年代空间不足:应用中大量对象存活时间较长,使得老年代空间占满,触发Full GC。可以通过-Xms和-Xmx参数调大年老代大小(-XX:PermSize和-XX:MaxPermSize)。
- 年轻代和老年代空间不平衡:如果年轻代空间过小,存活对象过早晋升到老年代,导致老年代空间饱和,触发Full GC。可以适当增加年轻代大小(-Xmn)和减小老年代空间(-XX:PermSize)。
- 垃圾循环引用:应用中存在对象之间相互引用,形成闭环,使得GC无法回收它们。需要排查代码,发现并打破循环引用。
- 代码缺陷:应用代码中存在资源未关闭、 memcache连接泄露等资源泄露问题,应检查代码并修复这些问题。
Full GC会收集的是哪些对象(2023 小红书)
- 年轻代中的对象:年轻代中晋升不到老年代的对象和刚创建的新对象。
- 老年代中的对象:存活时间长的对象。
- 永久代(JDK8以下)或元空间(JDK8及以上)中的对象:类信息、常量、方法等。
- 虚拟机栈中的对象:虚拟机栈中引用的对象。
- 本地方法栈中的对象:本地方法栈中引用的对象。
解决Full GC,我们可以减少对象的频繁创建,那么有一个我们接请求需求创建对象的场景,可以怎么优化?(2023 小红书)
- 对象池技术:重复利用对象,避免过度创建。比如字符串常量池,线程池等。
- 适当增加年轻代空间:-Xmn参数调大,让更多对象在Minor GC中就被回收,减少进入老年代的对象。
- 避免短期object churn:避免对象的频繁创建和消亡,尽量重复使用对象,这可以减少GC累积的工作。
- 避免finalize()方法:finalize()方法会增加GC的工作量,可以在代码中避免重写finalize()方法。
- 适当增加老年代空间:-Xms和-Xmx参数调大,增加老年代的空间,减少Full GC的触发频率。
- JDK8中使用Metaspace代替永久代:-XX:MetaspaceSize和-XX:MaxMetaspaceSize参数控制,避免永久代溢出。
- 分代收集器:-XX:+UseParallelGC和-XX:+UseParallelOldGC等参数选择分代收集器,Minor GC和Major GC可以并行进行,提高效率。
- 替换Full GC收集器:-XX:+UseG1GC等参数选择G1等收集器,避免出现Stop The World的Full GC。
- 减少垃圾循环引用: reviewing your code to reduce circular references can decrease the number of live objects and therefore Full GCs。
- 避免代码缺陷:如关闭数据库连接、文件流等,避免资源泄露导致Full GC。
这些优化措施可以从JVM参数调优、代码层面上防止对象过度创建和减少GC工作量,有效减少Full GC的频率。
Java线程之间通知怎么处理?(2023 得物)
使用
synchronized关键字,你可以保证一个时刻只有一个线程能访问同步代码块。这通常用于资源共享或者确保数据一致性。public synchronized void myMethod() { // Do something }在
synchronized代码块或者方法中,你可以使用wait(),notify()和notifyAll()方法来控制线程的执行。这些方法属于Java的Object类。wait(): 当前线程进入等待状态,释放锁。notify(): 唤醒一个在该对象监视器上等待的线程。notifyAll(): 唤醒所有在该对象监视器上等待的线程。
synchronized(sharedObject) { while(conditionNotMet) { sharedObject.wait(); } // Do something sharedObject.notify(); // 或者 sharedObject.notifyAll(); }Java标准库中的
java.util.concurrent包提供了一些高级同步工具,比如Semaphore、CountDownLatch、CyclicBarrier等。- Semaphore: 控制同时访问特定资源的线程数量。
- CountDownLatch: 允许一个或多个线程等待直到一组操作完成。
- CyclicBarrier: 允许一组线程互相等待直到所有线程都准备完毕。
Semaphore semaphore = new Semaphore(1); // 允许一个线程访问 semaphore.acquire(); // 获取一个许可 // critical section semaphore.release(); // 释放一个许可阻塞队列也是一种常用的线程通信手段。它可以用于生产者-消费者模型。
BlockingQueue<String> queue = new LinkedBlockingQueue<>(10); // 生产者 queue.put("item"); // 消费者 String item = queue.take();
比如说有一个队列当中,有批量线程去处理的任务,然后一个任务处理失败之后要终止其他任务,这个怎么处理?(2023 得物)
- 共享状态标志: 使用一个共享的状态标志(比如一个布尔变量),一旦一个线程失败,就设置这个标志。其他线程需要不断检查这个标志,如果发现标志被设置为失败,就自行终止。
- 线程池和Future: 如果使用线程池,通常每个任务的执行状态会被封装在一个
Future对象中。你可以通过检查这个Future对象来决定是否取消其他任务。 - 异常处理: 设计任务代码以抛出特定类型的异常表示失败。捕获这些异常并在捕获到异常后终止其他任务。
- 消息队列: 使用一个消息队列来发送停止信号给其他线程。
- 中断: 在Java这样支持线程中断的语言里,可以调用线程的
interrupt()方法来尝试终止它。但注意,线程需要正确处理中断才会实际停止。
新生代频繁Minor GC原因,解决办法?(2023 得物)
- 新生代空间设置过小
- 对象生命周期短,快速进入新生代并变得不可达
- 大量临时对象的创建
- 高并发或者高吞吐量的应用
解决办法:
- 增加新生代大小:通过调整JVM参数(例如,
-Xmn)来增大新生代空间。 - 对象池化:重用对象,而不是不断创建新对象。
- 代码优化:减少临时对象的创建,优化数据结构和算法。
- 调优GC参数:使用不同的垃圾收集器或者调整垃圾收集器的参数。
- 监控与诊断:使用工具(如JVisualVM, MAT等)来监控内存使用情况和对象的生命周期。
- 减少线程数或请求并发量:如果应用不能承受高并发,适当降低并发量。
- 使用适当的数据结构和缓存策略:以减少不必要的对象创建。
- 合理分配老年代和新生代的比例:可以使用
-XX:NewRatio进行调整。
频繁Full GC(老年代GC)的原因?解决办法?(2023 得物)
- 老年代空间不足:当老年代空间不足以容纳新晋升的对象时,会触发Full GC。
- 内存泄漏:长时间运行后,无法回收的对象会不断累积。
- 大对象或长生命周期的对象:这些对象直接进入老年代,增加了GC的频率。
- 系统调用或外部因素:比如使用
System.gc()手动触发。 - 不合适的GC策略或参数设置:比如不合适的堆大小或其他JVM参数。
解决办法:
- 增加老年代空间:使用JVM参数(例如,
-Xmx)增加堆内存大小。 - 内存泄漏排查:使用内存分析工具(如MAT、VisualVM等)定位和修复内存泄漏。
- 避免大对象和长生命周期对象:优化代码以减少这类对象或延长新生代大小。
- 调优GC策略和参数:根据应用需求选择合适的GC算法(如G1、CMS等)并进行参数调优。
- 避免手动触发GC:不要使用
System.gc()。 - 应用层面的优化:比如使用缓存来减少数据库查询,从而减少对象创建。
- 监控和日志分析:持续监控GC日志和系统性能,根据实际情况作出调整。
G1回收器 hop参数(2023 快手)
G1回收器如何回收老年代对象(2023 快手)
根据我的搜索结果,关于Java G1回收器如何回收老年代对象,有几个方面需要注意。
首先,在G1回收器中,老年代对象的回收是通过并发标记和并发清除来实现的。G1回收器将整个Java堆划分为多个大小相等的独立区域(Region),每个区域可以属于新生代或老年代。在垃圾回收过程中,G1会根据垃圾的分布情况,选择最有价值的区域进行回收,这也包括了老年代的区域。
其次,G1回收器采用了分代收集的策略,可以同时处理新生代和老年代的垃圾回收。在回收老年代对象时,G1回收器执行的操作包括标记、混合和清除。首先,G1回收器会对Java堆进行并发标记,标记出被引用的对象和不可达的对象。然后,G1会进行混合收集(Mixed Collection),即同时回收新生代和部分老年代的对象,并留下一部分老年代的区域未被回收。最后,G1回收器会在需要进行全局垃圾回收时,对剩余的老年代区域进行并发清除。
另外,G1回收器还实现了一些优化技术来提高老年代对象的回收效率。例如,“Humongous Objects”技术可以高效回收占据大量空间的对象;“String Deduplication”技术可以并发地回收重复的字符串对象。
总结一下,Java G1回收器通过并发标记、混合收集和并发清除等步骤,实现了对老年代对象的回收。它采用分代收集的策略,并结合了一些优化技术,以达到低延迟、高效率的垃圾回收目标。
📭 中间件
请求很多,消息堆积处理不过来了如何应对(2023滴滴)
如果发现消息中间件中的消息正在堆积,这可能意味着生产者生产的消息速度大于消费者的消费速度。有几种可能的策略可以缓解这个问题:
- 扩展消息中间件集群:考虑对消息中间件进行水平扩展,提高整体的处理能力。例如,在RabbitMQ中,可以增加节点来实现集群扩展。
- 降级:在降级策略中,当发现消息处理速度不足以应对积压的情况时,可以决定对某些类型或优先级较低的消息进行降级处理。降级处理的方式可能包括减慢处理这些消息的速度、暂时忽略这些消息,或者将这些消息转移到一个低优先级的队列等待处理。这样,系统可以把更多的资源用于处理高优先级的消息。
- 熔断:熔断是一种防止系统过载并快速失败的机制,类似于电路中的熔断器。当发现消息处理系统的压力过大时,可以启动熔断机制。这可能意味着暂时拒绝接收更多的消息,或者对新到的消息进行快速失败处理(例如立即返回错误,而不是将其放入队列)。一旦启动了熔断机制,就需要有一个机制去检测何时可以“闭合”熔断器,也就是何时可以恢复正常处理消息。这通常涉及到对系统的负载和性能进行监控,并设置合适的阈值。
消息堆积时,用户以为卡了,多次请求怎么处理(2023滴滴)
当消息积累时,用户认为它卡住了,应该如何处理多个请求?以下是可能的处理方式:
- 限流策略:可以通过限制每个用户在特定时间段内的请求次数来控制消息的积累。例如,可以使用令牌桶或漏桶算法来实现。
- 异步处理:如果服务器无法及时响应所有请求,可以考虑将请求放入队列中,并通过后台进程异步处理。这样用户不必等待请求完成,可以降低卡顿的感觉。
- 加载均衡:通过使用多台服务器来分担负载,可以有效地分散请求,减轻单个服务器的压力。
- 反馈机制:可以向用户提供反馈,告知他们请求正在处理中或在队列中排队。这样,即使有消息积累,用户也会明白情况并等待。
- 优化处理逻辑:如果问题出在处理请求的逻辑上,可以尝试优化代码,提高处理速度。
- 错误处理:如果有请求失败或卡住,应提供相应的错误处理机制,如重试、超时等,确保不会阻塞后续的请求。
- 缓存机制:对于一些重复的或者计算量大的请求,可以考虑使用缓存来减轻服务器的负载。
ES的索引?索引存储空间占用?ES索引和b+树索引区别?(2023 用友)
ES的索引:
Elasticsearch使用的倒排索引。基于倒排索引数据结构的数据压缩技术。在倒排索引中,每篇文档都对应一个文档编号,以及若干个单词(或词项)和它们在文档中出现的位置,将这些编号以及位置等元信息通过一定算法先进行预处理再进行压缩存储,从而大大减小了存储空间,降低了I/O读写的时间成本,提高了索引的检索效率。倒排索引采用了倒序和跳表技术,可以快速定位并遍历文档,然后进行词项匹配,减少了无效遍历,同时也缓解了内部节点可能产生的磁盘或内存I/O压力。倒排索引中词项的基数相对比较小,遍历检索时无需遍历整个索引,可以更加快速地找到文档,节约了遍历索引时的时间开销。
索引存储空间占用:
倒排索引的存储空间取决于多个因素,包括索引的大小、文档的数量和字段的类型等。倒排索引的存储空间主要包括两部分:词典和倒排表。词典存储了所有不重复的词项,并为每个词项分配一个唯一的标识符。词典的大小取决于索引中的不重复词项数量。倒排表存储了每个词项在文档中的出现位置信息。倒排表的大小与文档数量、文档长度和词项的频率等有关。在倒排表中,每个词项都对应一个包含该词项的文档列表,这些文档列表记录了词项在相应文档中出现的位置。综合来看,倒排索引的存储空间占用主要受以下几个因素影响:
- 文档数量:文档数量越多,倒排索引占用的存储空间就越大。
- 字段类型:不同类型的字段在倒排索引中所占用的存储空间可能会有所差异。例如,文本类型的字段可能需要更多的存储空间来存储词项信息。
- 词项重复性:如果一个词项在多个文档中频繁出现,倒排索引会占用更多的存储空间来记录这些文档列表。
ES索引和b+树索引区别:
- 数据结构:倒排索引是一种基于词项的数据结构,它将文档中的每个词项与其所在的文档进行关联。而B+Tree索引则是一种树状结构,根据索引键值构建有序的索引树。
- 存储方式:倒排索引以文档为单位存储词项信息,每个词项指向包含它的文档列表。而B+Tree索引是将索引键值与对应的数据记录进行关联。
- 适用范围:倒排索引适合处理文本类数据,尤其在全文搜索和关键字匹配方面具有出色的性能。而B+Tree索引适用于更一般的数据结构,常见于关系型数据库的索引实现。
- 检索效率:由于倒排索引的存储结构和搜索算法的优化,它在处理大规模文本数据时通常具有更高的检索效率。B+Tree索引则在处理更多样化的数据和范围查询时更具优势。
参考:
kafka是基于磁盘存储,为什么高性能(2023 得物)
- 批处理和缓冲: Kafka 将数据分批存储和发送,这样能够减少网络调用的次数和成本。
- 分布式架构: Kafka 集群由多个 brokers 组成,数据可以平行地存储和处理,这大大提高了系统的吞吐量。
- 分区和副本: 每个 Kafka 主题(Topic)可以被划分为多个分区(Partition),每个分区可以有一个或多个副本。这样能提供数据冗余,也使得并行读写成为可能。
- 高效的存储格式: Kafka 使用了高效的数据结构和存储格式(例如 snappy 或 lz4 压缩)来减少磁盘 I/O。
- 顺序读写: 磁盘顺序读写通常比随机读写要快得多。由于 Kafka 的日志结构存储,数据通常以顺序的方式写入和读取。
- 生产者和消费者解耦: Kafka 的发布-订阅模型允许生产者和消费者解耦,使系统具有更好的可扩展性和容错性。
- 低延迟: Kafka 设计用于保证低延迟,通过在 broker 和客户端之间有效地移动数据,并且能够处理数十万条消息/秒。
- 持久性: Kafka 可以配置为多种数据持久性选项,从不保留数据到永久存储,根据需要可灵活配置。
- 客户端多样性: Kafka 提供了多种语言的客户端库,易于集成到现有的架构和应用中。
- 监控和管理: Kafka 有丰富的监控和管理工具,方便对集群进行维护和优化。
kafka ack机制(2023 得物)
Kafka的ack机制是指生产者发送消息后,需要接收到分区的leader发送的确认收到的回复。在Kafka的配置参数中,有三个可选值:0、1和-1(或者all)。默认情况下,ack的值为1,表示生产者发送后需要接收到分区的leader发送的确认收到的回复4。
具体来说,不同的ack参数取值有以下含义:
- ack=0:生产者发送一次消息后就不再进行任何确认。这意味着无论消息是否发送成功,生产者都不会知道,因此可能会发生消息丢失的情况。
- ack=1:生产者发送消息后需要接收到分区的leader发送的确认收到的回复。只有当leader副本成功写入消息时,生产者才会认为消息发送成功。这种模式可以提供较高的可靠性,但可能会牺牲部分吞吐量。
- ack=-1(或者all):生产者发送消息后需要等待leader将消息同步给所有的follower。只有当所有follower都成功复制了消息后,生产者才会认为消息发送成功。这种模式可以提供最高的可靠性,但可能会降低吞吐量。
🔗 微服务、分布式
RPC如何进行序列化?(2023 阿里)
RPC的序列化是将数据结构或对象转换成可以通过网络传输的格式的过程。序列化后的数据可以通过网络传输,并在另一端反序列化,以重建原始数据结构或对象。 有很多方法可以序列化RPC数据,包括使用二进制格式,如Protocol Buffers1、JSON、XML等。
dubbo 的请求处理流程(2023 完美世界)
Dubbo 的请求处理流程如下:
- 服务消费方(客户端)调用远程服务的代理对象(Proxy)发起 RPC 调用。
- Proxy 接收到调用后,将调用信息转换成 Request 对象,然后发送到 Dubbo 的核心线程池 Executor 中。
- Executor 在线程池中选取一个线程,把 Request 发给 Dubbo 的 NIO 服务器 NettyServer。
- NettyServer 收到 Request 后,通过数据库查询找到服务提供方地址,然后将 Request 编码成 Netty 的 Buffer 对象。
- NettyServer 通过Netty Client 连接远程服务提供方,并将编码后的 Buffer 对象发送过去。
- 服务提供方 NettyServer 收到 Buffer 后,解码成 Request 对象。然后查找本地的服务实现并调用服务方法。
- 服务方法执行完成后,将返回结果封装成 Response 对象,并编码成 Buffer。
- 服务提供方 NettyServer 将 Buffer 通过 Netty Client 连接发送给服务消费方 NettyServer。
- 服务消费方 NettyServer 收到Buffer后,解码成 Response。然后发送给 Executor 线程池。
- Executor 将 Response 返回给最初的 Proxy 调用处。Proxy 得到响应结果后,返回给客户端。
- 整个 Dubbo RPC 调用过程完成。
所以 Dubbo 的请求处理主要分为四部分:
- 客户端 Proxy 发送请求
- 服务消费方收到请求,经过线程池转发给 Netty 服务器
- 服务器之间的网络通信,将请求转发给服务提供方
- 服务提供方执行服务并返回响应,将响应返回给服务消费方和客户端。
- 整个过程中,Netty 负责服务器网络通信,Executor 负责线程池和请求调度,Proxy 负责与客户端交互。
参考:
分布式系统的一致性怎么保证的?(2023 蚂蚁金服)
- Paxos:Paxos 是一个分布式系统中的一致性算法,它解决了在一个不可靠的网络中达成共识的问题。Paxos 核心思想是通过选举一个提案的领导者(proposer)并在提案的大多数接受者(accepter)之间达成共识。
- Raft:Raft 算法是一种更易于理解和实现的一致性算法,用于管理分布式系统中的复制日志。Raft 通过选举领导者并确保日志数据在集群中的节点达成一致来实现一致性。Raft 通常用于实现分布式数据库、文件系统等。
- 两阶段提交(2PC):两阶段提交是一种事务管理协议,用于保证分布式系统中的事务一致性。在第一阶段,事务协调者请求所有参与者预备提交;在第二阶段,事务协调者根据所有参与者的反馈提交或回滚事务。此协议存在阻塞问题,因为如果协调者宕机,参与者可能会一直等待。
- 三阶段提交(3PC):三阶段提交是两阶段提交的改进版本,通过添加一个“预提交”阶段来减少阻塞问题。然而,这种协议在网络分区的情况下仍可能会遇到问题。
- 分布式快照算法:分布式快照算法用于捕捉分布式系统中的全局状态,以评估一致性或检测死锁等问题。Chandy-Lamport 分布式快照算法是一个常用的实现。
- 向量时钟和版本向量:向量时钟和版本向量是用于跟踪分布式系统中事件之间的因果关系的数据结构。它们可以帮助检测冲突和保持一致性。
- Read Repair 和 Hinted Handoff:这些技术用于最终一致性系统(如 Apache Cassandra),在节点故障后进行数据修复以保持一致性。
实际应用中,通常会根据系统的需求和场景选择合适的一致性协议和算法。在选择时,需要权衡一致性、可用性和分区容错性之间的关系(CAP 理论)
gRPC,diRPC(滴滴自研)、Thrift和Dubbo各有什么优缺点,如何选型(2023 小红书)
优缺点:略,看看博客随便答吧
高性能、低延迟,可以选择 gRPC 或 diRPC。 服务治理功能,推荐 Dubbo。 简单、易用,可以选择 Thrift 或 Dubbo。 跨语言,可以选择 gRPC 或 Thrift。
设计一个RPC框架需要注意什么?(2023 美团)
随便说说吧,下面是比较全面的一些总结
- 通信协议:
- 传输协议:可以选择基于TCP、HTTP/2、UDP等的协议。比如gRPC基于HTTP/2。
- 数据编码/解码:选择一个高效且跨语言的序列化/反序列化机制,如Protocol Buffers、Avro、Thrift、JSON等。
- 服务发现和注册:
- 服务注册:允许服务提供者将其可用服务注册到服务目录中。
- 服务发现:允许服务消费者查询和查找服务目录以找到服务提供者。
- 负载均衡:提供服务间的负载均衡机制,可以是客户端负载均衡或服务端负载均衡。
- 超时与重试策略:为调用设置合适的超时时间,并根据需要制定重试策略。
- 错误处理:如何处理网络失败、服务不可用、数据不一致等情况。
- 安全性:
- 认证和授权:确定谁可以调用服务,以及他们可以做什么。
- 加密:在传输数据时,确保数据的机密性。
- 跟踪和监控:
- 为服务调用提供日志、监控和跟踪功能。
- 收集关于服务的性能、错误率、延迟等的统计信息。
- 版本控制:允许多版本的服务并行运行,确保新旧版本之间的兼容性。
- 容错和备份:确保系统在部分失败的情况下仍然可以运行。
- 并发和线程模型:如何处理多个并发的服务调用,可能涉及到线程池管理、事件驱动模型等。
- 流量控制和背压:避免因大量请求而导致的服务或网络拥塞。
- 客户端和服务端的开发经验:简化客户端和服务端的开发,可能涉及到代码生成、开发工具等。
- 跨语言支持:确保框架支持多种编程语言,以便于不同的服务和客户端之间的互操作性。
- 文档和社区支持:为开发者提供详细的文档和强大的社区支持,帮助他们更容易地使用和扩展框架。
- 可扩展性:考虑到框架的模块化,使得未来可以容易地增加新功能或替换现有组件。
为什么项目中一个使用了zookeeper一个使用了nacos,有什么区别(2023 美团)
主要是说区别,一个是AP/CP都行-nacos,一个是CP-zookeeper,还有可能是项目很老,以前我参与的项目就有Spring Cloud Netflix混着Alibaba用
它们之间的一些区别:
- 出生背景:
- ZooKeeper:ZooKeeper 是 Apache 的一个子项目,最初由雅虎创建。它主要被设计为一个分布式协调服务,为大数据应用如 Hadoop 和 HBase 提供服务。
- Nacos:Nacos 是阿里巴巴开源的一个更现代的项目,主要用于云原生环境。它除了提供服务发现和配置管理外,还支持动态服务管理。
- 主要功能:
- ZooKeeper:虽然 ZooKeeper 被广泛用于服务发现和配置管理,但它本质上是一个分布式的协调服务,提供的原子性操作可以帮助开发者实现分布式锁、集群选举等功能。
- Nacos:Nacos 的核心功能是服务发现、配置管理和动态服务管理。
- 易用性:
- ZooKeeper:需要一定的学习曲线,尤其是对于ZooKeeper的znode、watcher等概念的理解。
- Nacos:相比之下,Nacos 设计得更加友好,界面直观,使用起来更简单。
- 性能:
- ZooKeeper:为了保证强一致性,ZooKeeper 使用了 Paxos 协议变种的 ZAB 协议,可能会在某些场景下产生性能瓶颈。
- Nacos:更注重可用性和性能,因此在某些场景下可能优于 ZooKeeper。
- 生态:
- ZooKeeper:由于历史原因,ZooKeeper 在很多大数据技术中得到了广泛应用,如 Hadoop、Kafka、HBase 等。
- Nacos:更倾向于云原生应用和微服务架构,和 Spring Cloud、Dubbo 等技术集成得很好。
- 持久化:
- ZooKeeper:使用文件系统进行持久化。
- Nacos:可以使用MySQL数据库进行持久化。
为什么项目中一个使用了 ZooKeeper,一个使用了 Nacos,可能是基于以下几种考虑:
- 项目历史:旧的项目可能在 ZooKeeper 盛行时期开始,而新的项目可能更偏向于选择 Nacos 这样的现代解决方案。
- 功能需求:如果项目更多地需要协调服务,例如分布式锁,那么 ZooKeeper 可能是更好的选择。而对于服务发现和动态配置管理,Nacos 可能更合适。
- 团队经验:团队对某一技术的熟悉程度和历史经验也可能影响技术选择。
NGINX中正向代理和反向代理的区别?(2023 美团)
正向代理:
- 客户端知晓:在正向代理中,客户端明确知道有一个代理在中间。
- 请求流向:客户端发送请求到代理服务器,代理服务器再发送请求到目标服务器。
- 目的:常用于访问受限资源(例如,绕过地域限制或防火墙)。
- 安全性与隐私:可提供匿名访问,隐藏客户端 IP。
- 缓存与过滤:可以进行内容过滤或者数据缓存。
示例应用:
- 内网访问外网
- 访问受限制的网站
- 数据缓存和网页过滤(例如,在教育机构或企业内)
反向代理:
- 客户端不一定知晓:通常情况下,客户端并不知道请求被代理。
- 请求流向:客户端发送请求到“服务器”,实际上是反向代理接收了这些请求,然后代理决定将请求路由到哪个后端服务器。
- 目的:常用于负载均衡、缓存静态资源、SSL 终结等。
- 安全性与加速:可以提供应用层防火墙,减轻后端服务器的压力。
- 透明性:通常对客户端是透明的,客户端通常认为自己直接和后端服务器通信。
示例应用:
- 负载均衡
- CDN(内容分发网络)
- Web 应用防火墙
- SSL 终结
- HTTP 缓存
了解哪些分布式事务?(2023 快手)
- 两阶段提交(Two-Phase Commit,2PC):2PC是一种经典的分布式事务协议,它通过协调者和参与者的两个阶段来确保事务的一致性。在第一阶段,协调者向所有参与者发送事务准备请求,参与者将准备好的事务状态反馈给协调者。在第二阶段,协调者根据参与者的反馈决定是否提交或中止事务。2PC的主要缺点是阻塞问题和单点故障。
- 三阶段提交(Three-Phase Commit,3PC):3PC是对2PC的改进,主要解决了2PC的阻塞问题。与2PC不同,3PC引入了预提交阶段,使得参与者在准备完成之后可以继续处理其他事务。3PC在保证一致性的同时,也增加了一定的复杂性。
- 补偿事务(Compensating Transaction):补偿事务是一种基于补偿机制的分布式事务处理方法。在补偿事务中,每个参与者执行事务时记录一些可以用于回滚操作的补偿操作,并在需要回滚时依次执行这些补偿操作,将系统恢复到原始状态。补偿事务在容错和扩展性方面有一定优势,但可能需要额外的开发工作。
- Saga模式:Saga模式是一种事件驱动的分布式事务模式,将复杂的分布式事务分解为多个局部事务,每个局部事务负责处理自己的业务逻辑和状态变更,并通过发布和订阅事件的方式进行协调。Saga模式具有较好的可扩展性和灵活性,但需要开发人员对业务逻辑进行分解和编排。
负载均衡算法有哪些?(2023 得物)
负载均衡算法是用来分配服务器负载的算法。根据搜索结果,负载均衡算法可以分为静态负载均衡算法和动态负载均衡算法。
静态负载均衡算法包括:
- 轮询算法(Round Robin):按顺序将请求分配给后端服务器,实现均衡分配。
- 随机算法(Random):根据随机算法选择一个后端服务器。
- 加权轮询算法(Weighted Round Robin):根据服务器配置的权重分配请求,权重高的服务器处理更多的请求。
- 加权最少连接算法(Weighted Least Connections):根据服务器的权重和当前连接数选择一个合适的服务器进行分配。
- 源地址哈希算法(IP Hash):根据客户端的源IP地址计算哈希值,选择一个固定的服务器来处理该请求。
动态负载均衡算法包括:
- 最少连接数算法(Least Connections):将请求分配给当前连接数最少的服务器,以保证负载均衡。
- 最快响应速度算法(Fastest Response):根据服务器的响应时间选择最快的服务器来处理请求。
- 观察方法(Observation Method):根据系统运行状态观察后端服务器的负载情况,选择合适的服务器进行负载均衡。
- 预测法(Prediction Method):根据预测算法预测后端服务器的负载情况,选择合适的服务器进行负载均衡。
🌐 计算机网络
服务端出现大量 close_wait 状态,可能的情况?(2023 美团)
CLOSE_WAIT状态通常意味着你的程序在关闭连接时有一些问题,或者说,它没有正确地关闭套接字连接。这通常发生在程序接收到了服务端的完成(FIN)信号,但是程序自身没有正确地关闭套接字,或者没有在适当的时间内关闭。当这种情况发生时,你会看到大量的连接处于CLOSE_WAIT状态。
导致大量CLOSE_WAIT状态的可能情况有很多,以下是一些可能的情况:
- 应用程序故障:应用程序可能没有正确地关闭连接。例如,应用程序可能在完成数据交换后忘记关闭连接,或者应用程序可能由于错误而无法关闭连接。这是最常见的原因。
- 网络问题:如果网络环境不稳定,可能导致部分TCP连接无法正常关闭,从而导致'close_wait'状态。网络故障**:网络连接问题可能会导致套接字无法正确关闭,从而导致大量的CLOSE_WAIT状态。例如,网络延迟可能导致FIN包被延迟发送,或者网络丢包可能导致FIN包丢失,这都可能导致连接无法正确关闭。
- 系统资源不足:系统资源不足可能会导致应用程序无法创建新的套接字,或者无法为新的连接分配足够的内存,这都可能导致大量的
CLOSE_WAIT状态。 - 服务端负载过高:服务器负载过高可能会导致应用程序无法及时处理所有的连接,特别是在需要关闭的连接上,从而导致这些连接长时间处于
CLOSE_WAIT状态。 - 服务端代码中有一个bug: 服务器代码中的错误可能导致它意外关闭连接。 这也可能导致新请求处于等待状态。
- 服务端有硬件问题: 硬件问题(如内存泄漏或CPU瓶颈)也可能导致服务器关闭连接。 这可能导致新请求处于等待状态。
- 客户端频繁断开连接:如果客户端频繁地建立和断开连接,而服务端处理这些连接的速度不够快,也可能导致大量的'close_wait'连接。另外,如果客户端频繁地建立和断开连接,那么即使服务端可以及时处理所有的连接,也可能会因为网络延迟等问题,导致大量的
CLOSE_WAIT状态。 - TCP连接没有正确地被结束:当一个TCP连接要结束时,通常需要双方都发送一个“FIN”数据包来表示他们不再发送数据,并等待对方的确认。关闭系统调用是应用程序向操作系统发出的指令,要求关闭套接字并释放资源。客户端的“FIN”数据包,但没有调用关闭系统调用,那么服务器就会一直保持在“close_wait”状态,直到应用程序关闭套接字
解决这种问题通常需要找出导致大量CLOSE_WAIT状态的原因,并进行相应的修复。例如,如果是应用程序没有正确关闭连接,那么可能需要修改应用程序的代码,确保它在完成数据交换后正确关闭连接。如果是网络问题,可能需要检查和修复网络连接。如果是系统资源不足,可能需要增加系统资源或优化应用程序以减少资源使用。如果是服务器负载过高,可能需要增加服务器资源或优化服务器配置来降低负载。
参考:
- https://stackoverflow.com/questions/21033104/close-wait-state-in-server 服务器中的CLOSE_WAIT状态
- https://superuser.com/questions/173535/what-are-close-wait-and-time-wait-states 什么是CLOSE_WAITTIME_WAIT状态?
- https://learn.microsoft.com/en-us/answers/questions/337518/tcp-connections-locked-in-close-wait-status-with-i
- https://www.cnblogs.com/grey-wolf/p/10936657.html
- https://juejin.cn/post/6844903734300901390#heading-6
- https://www.thegeekdiary.com/high-number-of-connections-is-close_wait-state-in-netstat-command-output/ 为什么"netstat"输出显示许多连接处于CLOSE_WAIT状态?
http协议的报文的格式有了解吗?
 HTTP 的请求报文分为三个部分:
HTTP 的请求报文分为三个部分:
请求行、首部行、实体主体。
http2了解吗?(2023小红书)
HTTP/2是对万维网使用的HTTP网络协议的重大修订。它源自较早的实验性SPDY协议,最初由Google开发。HTTP/2不是对协议的彻底重写;HTTP方法、状态码和语义学与HTTP/1. x相同(可能有一些小的补充)来表示协议。新的二进制成帧机制的引入改变了客户端和服务器之间数据交换的方式。要描述这个过程,可以熟悉HTTP/2术语 -- Stream:已建立连接内的双向字节流,它可能携带一条或多条消息。
您还可以提到HTTP/2旨在提高网站性能并减少延迟。它通过引入几个新功能来做到这一点,例如服务器推送、标头压缩和多路复用。
参考:
建立 TCP 连接后,客户端下线了会发生什么(2023 百度)
TCP(传输控制协议)连接建立后,如果客户端下线或断开,那么这个TCP连接就会被中断。
在TCP协议中,任何一方(客户端或服务器)都可以主动断开连接。在正常情况下,断开连接会通过一个四步握手过程(四次挥手)来完成。这个过程保证了双方都能清楚地了解连接已经被关闭,而不会造成数据丢失。
然而,如果客户端突然下线(比如因为网络中断、电源切断等原因),服务器可能并不会立刻知道这个情况。这是因为TCP协议的设计使得它能够在短暂的网络中断后恢复连接。所以,如果服务器尝试向客户端发送数据,这些数据可能会被阻塞,直到达到一定的重试次数或者超时,服务器才会认为连接已经断开。
在客户端重新上线后,如果它尝试再次建立与服务器的连接,那么需要完全重新进行TCP的三次握手过程来建立新的连接。
需要注意的是,TCP协议提供的是一种“可靠”的传输服务。即使在网络环境不稳定、丢包率高的情况下,TCP也能确保数据的完整性和有序性。但是,这种可靠性是通过复杂的错误检测和修复机制、以及重传机制来实现的,这也使得TCP在处理断开连接和重连的情况时相对复杂。
讲讲 ARP,ICMP? 什么时候不用查 ARP 表? ICMP 是哪个路由器回复的,什么地方用了 icmp,traceroute 怎么做的? (2023 阿里实习)
ARP(地址解析协议) 和ICMP(公网控制消息协议) 都是计算机网络中使用的协议,ARP用于将网络地址(如IP地址)映射到物理地址(如MAC地址),而ICMP用于错误报告和诊断目的,ping命令也使用ICMP来测试两个设备之间的网络连通性。
地址解析协议(英语:Address Resolution Protocol,缩写:ARP)是一个通过解析网络层地址来找寻数据链路层地址的网络传输协议,它在IPv4中极其重要。ARP最初在1982年的RFC 826(征求意见稿)中提出并纳入互联网标准STD 37。ARP也可能指是在多数操作系统中管理其相关地址的一个进程。
互联网控制消息协议(英语:Internet Control Message Protocol,缩写:ICMP)是互联网协议族的核心协议之一。它用于网际协议(IP)中发送控制消息,提供可能发生在通信环境中的各种问题反馈。通过这些信息,使管理者可以对所发生的问题作出诊断,然后采取适当的措施解决。
在计算机网络中,通常在以下几种情况下不需要查ARP(地址解析协议)表:
- 跨网段通信:当通信双方位于不同的网络子网中时,ARP表不起作用。此时,数据包需要经过路由器进行转发,通信双方只需查找默认网关的MAC地址,而不需要查找对方的IP地址和MAC地址的映射关系。
- 非以太网链路层协议:ARP主要用于解析IPv4地址和以太网MAC地址之间的映射关系。对于其他链路层协议(如帧中继、ATM等)或其他网络层协议(如IPv6),ARP表可能无法使用或使用不同的机制。例如,IPv6使用邻居发现协议(NDP)而非ARP。
- 已知目标MAC地址:在某些特殊情况下,发送方可能已知目标设备的MAC地址,此时无需查找ARP表。例如,某些特定的网络管理或监控应用可能直接处理MAC地址。
- 广播与多播:对于广播(例如IPv4的全局广播地址255.255.255.255)或多播(例如IPv6的多播地址),数据包将发送给一组设备而非单个目标。这种情况下,发送方无需查找ARP表,而是将数据包发送到一个特定的广播或多播MAC地址上。
总结:在跨网络子网通信、使用非以太网链路层协议、已知目标MAC地址、或进行广播和多播通信的情况下,通常不需要查找ARP表。
当数据包在传输过程中遇到问题,如无法到达目的地或超时等,通常是路由器或目标主机回复ICMP报文。例如,当数据包无法到达目标地址时,路由器可能会发送ICMP“目标不可达”(Destination Unreachable)报文;当数据包在网络中传输时间过长时,路由器可能会发送ICMP“超时”(Time Exceeded)报文。
traceroute(Windows系统中的tracert)是一个网络诊断工具,用于显示数据包从源主机到目标主机所经过的路由器。traceroute的工作原理如下:
- 发送方生成一个特殊的数据包(通常是UDP或ICMP ECHO请求报文),并将其生存时间(TTL,Time to Live)设置为1。
- 当第一个路由器收到该数据包时,它会将TTL减1。由于TTL变为0,路由器会丢弃该数据包,并向发送方发送一个ICMP“超时”(Time Exceeded)报文。
- 发送方收到ICMP“超时”报文后,记录报文中的路由器地址,然后再生成一个相同的数据包,但将TTL设置为2。
- 重复上述过程,逐步增加TTL值,直到发送方收到目标主机的ICMP“端口不可达”(Port Unreachable)报文(对于UDP数据包)或ICMP ECHO响应(对于ICMP ECHO请求报文)。
- 通过分析收到的ICMP报文,traceroute可以显示数据包从源主机到目标主机所经过的所有路由器的地址,以及数据包在每个路由器上的往返时间(RTT,Round-Trip Time)。
参考:
- https://www.linux.com/news/ping-icmp-vs-arp/
- https://nmap.org/book/host-discovery-techniques.html
- https://zh.wikipedia.org/wiki/互联网控制消息协议
- https://zh.wikipedia.org/wiki/地址解析协议
- https://www.fortinet.com/resources/cyberglossary/what-is-arp
- https://www.tutorialspoint.com/arp-table
- https://superuser.com/questions/894557/is-there-a-way-to-get-arp-to-list-devices-on-all-subnets-of-a-network
- https://obkio.com/blog/traceroutes-what-are-they-and-how-do-they-work/
- https://www.howtogeek.com/134132/how-to-use-traceroute-to-identify-network-problems/
- https://www.fortinet.com/resources/cyberglossary/traceroutes
如果同时有大量客户并发建立连接,服务器端有什么机制进行处理?(2023 字节提前批)
服务器端处理大量并发连接的机制主要有以下几种:
- 多进程和多线程:每当接收到新的客户端连接时,服务器都会分配一个新的进程或线程去处理这个连接。这可以确保服务器能够同时处理多个客户端连接。但是,如果连接数太多,过多的线程或进程可能会导致系统资源的过度使用,影响服务器的性能。
- 事件驱动(Event-driven)或异步I/O(Async I/O):在这种模型中,服务器一次接收多个连接请求,然后通过事件循环(Event Loop)异步地处理这些连接。这样可以避免为每个连接创建新的线程或进程,从而提高性能。
- 负载均衡(Load Balancing):如果服务器无法处理所有的并发连接,可以使用负载均衡器将连接请求分配到多个服务器上。这可以分散服务器的负载,提高整体的处理能力。
这里要区分出现了大量TIME_WAIT或者CLOSE_WAIT
大量的
TIME_WAIT或CLOSE_WAIT,它们是 TCP 连接关闭过程中的状态。TIME_WAIT表示连接已被本地关闭,正在等待足够的时间以确保远程TCP接收到连接终止的通知。CLOSE_WAIT则表示远程TCP连接关闭或接收到了连接终止的通知。
🔥 HTTP1.1, 2.0区别(2023 热门问题之一:2023 百度提前批,2023 字节客户端,影石360)
HTTP/1.1 和 HTTP/2 是两个不同的协议版本,用于在客户端和服务器之间进行通信。以下是它们之间的一些主要区别:
- 传输方式:HTTP/1.1 使用序列化的文本数据来传输请求和响应,而 HTTP/2 使用二进制格式的数据帧来传输请求和响应。这种二进制格式能够更高效地传输数据,减少了数据传输的大小和延迟。
- 多路复用:HTTP/1.1 在一个连接上只能处理一个请求和响应,而 HTTP/2 支持在同一个连接上同时处理多个请求和响应。这种多路复用的特性可以减少连接建立和关闭的开销,提高了性能和效率。
- 头部压缩:HTTP/2 引入了头部压缩机制,使用 HPACK 算法对请求和响应的头部进行压缩。这种压缩机制可以减少数据传输的大小,提高网络传输效率。
- 服务器推送:HTTP/2 支持服务器主动推送资源给客户端,以提高页面加载性能。服务器可以在发送请求的同时,将一些可能需要的资源主动推送给客户端,减少了客户端发送额外请求的需要。
- 流控制:HTTP/2 引入了流控制机制,允许客户端和服务器控制数据流的速率,以避免数据传输过程中的拥塞和溢出。 总体而言,HTTP/2 相对于 HTTP/1.1 来说,在性能和效率上有了很大的提升。它的多路复用、头部压缩、服务器推送等特性使得网络传输更加高效,能够更快地加载网页和提供更好的用户体验。
- 流量控制:HTTP/1.1 使用 TCP 层的流量控制机制,而 HTTP/2 在应用层实现了自己的流量控制机制。这使得 HTTP/2 可以更好地控制数据的传输速率,避免缓冲区溢出的问题。
总的来说,HTTP1.1和HTTP2.0是用于在web服务器和客户端之间传输数据的协议。HTTP2.0比HTTP1.1更快、更可靠,因为它使用二进制编码、多路复用和并发。HTTP1.1为每个TCP连接加载一个请求,这可能会导致网络延迟和页面加载速度减慢。HTTP2.0可以并行处理多个请求和响应,这可以提高web性能和用户体验。HTTP2.0与HTTP1.1语义(如方法和头)兼容,因此web应用程序仍然可以使用新协议正常运行。
参考:
- https://www.cloudflare.com/zh-cn/learning/performance/http2-vs-http1.1/ HTTP/2 与 HTTP/1.1:它们如何影响 Web 性能?
- https://www.baeldung.com/cs/http-versions HTTP: 1.0 vs. 1.1 vs 2.0 vs. 3.0
- https://www.digitalocean.com/community/tutorials/http-1-1-vs-http-2-what-s-the-difference 【推荐阅读】HTTP/1.1与HTTP/2:有什么区别?
tcp 是怎么实现可靠传输的?(2023 字节、2023 影石360)
- 序列号与确认应答:TCP将每个发送的数据包进行编号(序列号),接收方通过发送确认应答(ACK)来告知发送方已成功接收到数据。如果发送方在一定时间内未收到确认应答,会进行超时重传。
- 数据校验:TCP使用校验和来验证数据的完整性。接收方会计算接收到的数据的校验和,并与发送方发送的校验和进行比较,以检测数据是否在传输过程中发生了错误。
- 窗口控制:TCP使用滑动窗口机制来控制发送方和接收方之间的数据流量。发送方根据接收方的处理能力和网络状况来调整发送的数据量,接收方则通过窗口大小来告知发送方可以接收的数据量。
- 重传机制:如果发送方未收到确认应答或接收方检测到数据错误,TCP会进行重传。发送方会根据超时时间或接收方的冗余确认来触发重传,以确保数据的可靠传输。
- 拥塞控制:TCP使用拥塞控制算法来避免网络拥塞。通过动态调整发送速率和窗口大小,TCP可以根据网络的拥塞程度来进行适当的调整,以提高网络的利用率和稳定性。
IP数据报的报头有哪些字段?(2023 字节)
IP 报文的TTL是什么意思?(2023 字节)
指定数据报在网络中可以经过的最大路由器跳数。每当数据报经过一个路由器时,该字段的值会减少1。当TTL的值为0时,路由器将丢弃该数据报并发送ICMP的时间超过消息给源主机。
TTL的主要目的是防止数据报在网络中无限循环,避免由于路由环路或其他问题导致的数据报无法正常到达目的地。通过限制数据报的最大跳数,TTL可以确保数据报在有限的时间内能够到达目标主机或被丢弃,以避免网络资源的浪费和延迟。
如何实现一个可靠UDP?(2023 美团)
- 分包与组包: 由于UDP有数据包大小的限制,所以可能需要将大数据切分成多个小数据包进行发送,接收方则需要将这些小数据包重新组装。
- 序列号: 对每一个UDP数据包分配一个唯一的序列号,这样接收方就可以知道是否有数据包丢失或是数据包到达的顺序是否正确。
- 确认与重传:
- 确认(ACK): 当接收方收到数据包时,它应该发送一个确认包(ACK)给发送方。
- 超时与重传: 发送方需要为每个已发送的数据包设置一个超时计时器。如果在超时时间内没有收到对应的确认包,发送方应重传数据包。
- 滑动窗口: 为了控制数据包的流量和避免网络拥塞,可以实现一个滑动窗口机制。这意味着发送方在任何时候只能有固定数量的未被确认的数据包在网络中。
- 顺序控制: 由于网络的原因,数据包可能会乱序到达接收方。接收方应该使用数据包的序列号对其进行重新排序,并确保上层应用按正确的顺序接收数据。
- 错误检测: 可以使用诸如CRC(循环冗余检查)这样的技术来检查数据包在传输过程中是否被损坏。
- 流量控制与拥塞控制: 根据网络的状态和接收方的处理能力,动态地调整发送速率,避免造成网络拥塞或接收方的资源不足。
ping命令是什么协议?(2023 美团)
icmp 协议
同个子网下的主机 A 和 主机 B,主机 A 执行ping 主机 B 后,我们来看看其间发送了什么?
ping 命令执行的时候,源主机首先会构建一个 ICMP 回送请求消息数据包。
ICMP 数据包内包含多个字段,最重要的是两个:
- 第一个是类型,对于回送请求消息而言该字段为
8; - 另外一个是序号,主要用于区分连续 ping 的时候发出的多个数据包。
每发出一个请求数据包,序号会自动加 1。为了能够计算往返时间 RTT,它会在报文的数据部分插入发送时间。

然后,由 ICMP 协议将这个数据包连同地址 192.168.1.2 一起交给 IP 层。IP 层将以 192.168.1.2 作为目的地址,本机 IP 地址作为源地址,协议字段设置为 1 表示是 ICMP协议,再加上一些其他控制信息,构建一个 IP 数据包。

接下来,需要加入 MAC 头。如果在本地 ARP 映射表中查找出 IP 地址 192.168.1.2 所对应的 MAC 地址,则可以直接使用;如果没有,则需要发送 ARP 协议查询 MAC 地址,获得 MAC 地址后,由数据链路层构建一个数据帧,目的地址是 IP 层传过来的 MAC 地址,源地址则是本机的 MAC 地址;还要附加上一些控制信息,依据以太网的介质访问规则,将它们传送出去。

主机 B 收到这个数据帧后,先检查它的目的 MAC 地址,并和本机的 MAC 地址对比,如符合,则接收,否则就丢弃。
接收后检查该数据帧,将 IP 数据包从帧中提取出来,交给本机的 IP 层。同样,IP 层检查后,将有用的信息提取后交给 ICMP 协议。
主机 B 会构建一个 ICMP 回送响应消息数据包,回送响应数据包的类型字段为 0,序号为接收到的请求数据包中的序号,然后再发送出去给主机 A。

在规定的时候间内,源主机如果没有接到 ICMP 的应答包,则说明目标主机不可达;如果接收到了 ICMP 回送响应消息,则说明目标主机可达。
此时,源主机会检查,用当前时刻减去该数据包最初从源主机上发出的时刻,就是 ICMP 数据包的时间延迟。
针对上面发送的事情,总结成了如下图:
当然这只是最简单的,同一个局域网里面的情况。如果跨网段的话,还会涉及网关的转发、路由器的转发等等。
但是对于 ICMP 的头来讲,是没什么影响的。会影响的是根据目标 IP 地址,选择路由的下一跳,还有每经过一个路由器到达一个新的局域网,需要换 MAC 头里面的 MAC 地址。
说了这么多,可以看出 ping 这个程序是使用了 ICMP 里面的 ECHO REQUEST(类型为 8 ) 和 ECHO REPLY (类型为 0)。
了解哪些网络错误码吗?(2023 美团)
以下是其中一些常见的错误码及其含义:
- 400 Bad Request:请求无效或不完整。
- 401 Unauthorized:未经授权,需要身份验证。
- 403 Forbidden:服务器拒绝请求,没有访问权限。
- 404 Not Found:请求的资源不存在。
- 500 Internal Server Error:服务器内部错误。
- 502 Bad Gateway:网关错误,作为代理或网关的服务器从上游服务器接收到无效的响应。
- 503 Service Unavailable:服务不可用,服务器暂时过载或维护中。
- 504 Gateway Timeout:网关超时,作为代理或网关的服务器在等待上游服务器响应时超时。
- 505 HTTP Version Not Supported:不支持的HTTP协议版本。
cookie和session区别?(2023 快手)
- 存储位置:Cookie存储在客户端(浏览器)中,而Session存储在服务器端。
- 安全性:由于Cookie存储在客户端,因此容易受到安全攻击,如跨站脚本攻击(XSS)和跨站请求伪造(CSRF)。而Session存储在服务器端,对客户端不可见,相对来说更安全。
- 存储容量:Cookie的存储容量有限,通常为4KB左右,而Session的存储容量较大,受限于服务器的配置。
TCP的粘包与拆包(2023 得物)
TCP的粘包与拆包是在TCP协议中可能出现的一种现象。TCP是一种面向字节流的协议,没有固定的消息边界,因此在数据传输过程中,发送方发送的多个数据包可能会被粘成一包传输(粘包),或者一个数据包可能被拆分成多个小包传输(拆包)。
造成TCP粘包的原因是,发送方在发送数据时,会通过缓冲区进行优化。如果一次请求发送的数据量小于缓冲区大小,则TCP会将多个请求合并为同一个请求进行发送,从而导致粘包问题。而当一次请求发送的数据量超过缓冲区大小时,TCP会将其拆分为多次发送,就会发生拆包现象。
粘包和拆包问题在数据链路层、网络层以及传输层都有可能发生。但由于UDP协议具有消息保护边界,不会发生粘包和拆包问题,因此粘包和拆包问题主要发生在TCP协议中。
关于TCP粘包和拆包问题的解决方案,有一些常用的方法。比如可以使用定长包和定界符包,即在数据包中加入包长度或使用特定字符来标识包的边界。此外,也可以利用消息头中的长度字段进行处理,或者使用基于时间的策略进行包的分割和重组。
在实际应用中,为了解决TCP粘包和拆包问题,开发者可以根据具体场景选择合适的解决方案,并进行相应的调试和优化。
所以,TCP的粘包与拆包是指在TCP协议中可能出现的数据包传输现象,其中粘包是指多个数据包被粘合在一起传输,拆包是指一个数据包被拆分成多个小包传输。解决TCP粘包与拆包问题可以采用定长包、定界符包、长度字段等方法。
HTTP 2 流式连接是怎么实现的?(2023 快手)
我们都知道 HTTP/1.1 的实现是基于请求-响应模型的。同一个连接中,HTTP 完成一个事务(请求与响应),才能处理下一个事务,也就是说在发出请求等待响应的过程中,是没办法做其他事情的,如果响应迟迟不来,那么后续的请求是无法发送的,也造成了队头阻塞的问题。
而 HTTP/2 就很牛逼了,通过 Stream 这个设计,多个 Stream 复用一条 TCP 连接,达到并发的效果,解决了 HTTP/1.1 队头阻塞的问题,提高了 HTTP 传输的吞吐量。
为了理解 HTTP/2 的并发是怎样实现的,我们先来理解 HTTP/2 中的 Stream、Message、Frame 这 3 个概念。
你可以从上图中看到:
- 1 个 TCP 连接包含一个或者多个 Stream,Stream 是 HTTP/2 并发的关键技术;
- Stream 里可以包含 1 个或多个 Message,Message 对应 HTTP/1 中的请求或响应,由 HTTP 头部和包体构成;
- Message 里包含一条或者多个 Frame,Frame 是 HTTP/2 最小单位,以二进制压缩格式存放 HTTP/1 中的内容(头部和包体);
因此,我们可以得出个结论:多个 Stream 跑在一条 TCP 连接,同一个 HTTP 请求与响应是跑在同一个 Stream 中,HTTP 消息可以由多个 Frame 构成, 一个 Frame 可以由多个 TCP 报文构成。
在 HTTP/2 连接上,不同 Stream 的帧是可以乱序发送的(因此可以并发不同的 Stream ),因为每个帧的头部会携带 Stream ID 信息,所以接收端可以通过 Stream ID 有序组装成 HTTP 消息,而同一 Stream 内部的帧必须是严格有序的。
比如下图,服务端并行交错地发送了两个响应: Stream 1 和 Stream 3,这两个 Stream 都是跑在一个 TCP 连接上,客户端收到后,会根据相同的 Stream ID 有序组装成 HTTP 消息。
客户端和服务器双方都可以建立 Stream,因为服务端可以主动推送资源给客户端, 客户端建立的 Stream 必须是奇数号,而服务器建立的 Stream 必须是偶数号。
比如下图,Stream 1 是客户端向服务端请求的资源,属于客户端建立的 Stream,所以该 Stream 的 ID 是奇数(数字 1);Stream 2 和 4 都是服务端主动向客户端推送的资源,属于服务端建立的 Stream,所以这两个 Stream 的 ID 是偶数(数字 2 和 4)。
同一个连接中的 Stream ID 是不能复用的,只能顺序递增,所以当 Stream ID 耗尽时,需要发一个控制帧 GOAWAY,用来关闭 TCP 连接。
在 Nginx 中,可以通过 http2_max_concurrent_Streams 配置来设置 Stream 的上限,默认是 128 个。
HTTP/2 通过 Stream 实现的并发,比 HTTP/1.1 通过 TCP 连接实现并发要牛逼的多,因为当 HTTP/2 实现 100 个并发 Stream 时,只需要建立一次 TCP 连接,而 HTTP/1.1 需要建立 100 个 TCP 连接,每个 TCP 连接都要经过 TCP 握手、慢启动以及 TLS 握手过程,这些都是很耗时的。
HTTP/2 还可以对每个 Stream 设置不同优先级,帧头中的「标志位」可以设置优先级,比如客户端访问 HTML/CSS 和图片资源时,希望服务器先传递 HTML/CSS,再传图片,那么就可以通过设置 Stream 的优先级来实现,以此提高用户体验。
什么是dns中间人攻击?(2023 快手)
DNS中间人攻击(DNS Man-in-the-Middle Attack)是一种网络安全威胁。攻击者使用各种技术手段,拦截DNS(Domain Name System)查询流量并篡改其内容,从而使用户被导向恶意网站或受到其他攻击。这种攻击会破坏正常的DNS解析过程,导致用户无法访问正确的网站,或者向错误的服务器发送敏感信息。
中间人攻击是一种“间接”的入侵攻击,通过将攻击者控制的计算机放置在受害者和目标之间,实现恶意操作。在DNS中间人攻击中,攻击者通常会拦截用户的DNS查询请求,然后伪造响应,返回错误的IP地址或重定向用户到恶意站点。这样一来,用户在访问网站时就会被导向攻击者控制的网站,从而暴露于各种网络威胁之下。
参考:
如何解决syn泛洪攻击?(2023 快手)
SYN泛洪攻击是一种常见的拒绝服务(Denial of Service,DoS)攻击,它通过发送大量伪造的TCP连接请求(SYN包)来消耗目标服务器的资源,使其无法正常工作。解决SYN泛洪攻击,可以采取以下几种措施:
- 过滤和阻断恶意流量:使用防火墙或入侵防御系统(IDS/IPS)等安全设备,过滤和阻断来自攻击者的SYN泛洪攻击流量。这些设备可以根据网络流量的规则和行为进行检测和过滤,有效防止恶意流量进入网络。
- SYN Cookie技术:SYN Cookie是一种抵御SYN泛洪攻击的技术,它通过在服务器响应SYN包时,将部分状态信息嵌入到服务器生成的序列号中。当客户端返回ACK确认时,服务器可以通过解析序列号还原出完整的连接状态。这种方法可以减轻服务器的负担,并有效降低SYN泛洪攻击的影响。
- 加强网络设备的性能和容量:通过升级硬件设备、增加带宽和加强服务器的处理能力,可以提高网络设备的性能和容量,从而能够更好地抵御SYN泛洪攻击。增加设备的处理能力和带宽可以承受更多的连接请求,减少因攻击而导致的服务不可用情况。
参考:
🖥️ 操作系统
🔥 进程和线程的概念和区别?(2023 热门问题之一:快手、影石360)
看了一遍排在前面的答案,类似”**进程是资源分配的最小单位,线程是CPU调度的最小单位“**这样的回答感觉太抽象,都不太容易让人理解。
做个简单的比喻:进程=火车,线程=车厢
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
- 进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-"互斥锁"
- 进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
用户态和内核态的区别?(2023 影石360)
Kernel 运行在超级权限模式(Supervisor Mode)下,所以拥有很高的权限。按照权限管理的原则,多数应用程序应该运行在最小权限下。因此,很多操作系统,将内存分成了两个区域:
- 内核空间(Kernal Space),这个空间只有内核程序可以访问;
- 用户空间(User Space),这部分内存专门给应用程序使用。
用户空间中的代码被限制了只能使用一个局部的内存空间,我们说这些程序在用户态(User Mode) 执行。内核空间中的代码可以访问所有内存,我们称这些程序在内核态(Kernal Mode) 执行。
划分来说有以下区别:
- 权限:内核模式具有访问所有硬件资源的权限,而用户模式的权限则受到限制。
- 功能:内核模式用于执行关键的系统任务,如设备管理、内存管理和文件系统操作。用户模式主要用于运行应用程序。
- 安全性:当程序在用户模式下运行时,它不能直接访问硬件或其他关键资源,这为系统提供了一层保护。如果应用程序需要访问硬件或执行其他特权操作,它必须通过系统调用请求内核来执行。
- 错误处理:在用户模式下出现的错误通常不会导致整个系统崩溃,而在内核模式下出现的错误可能会导致系统崩溃。
为什么用户态和内核态之间的切换会影响到线程的执行效率,真正慢的点在哪里?(2023 影石360)
每个上下文切换都涉及保存CPU的当前状态(包括程序计数器、CPU寄存器和进程控制块),加载新进程或线程的状态,然后恢复新进程或线程的执行。这需要时间并消耗CPU资源,这会使系统变慢。
- https://blog.netdata.cloud/understanding-context-switching-and-its-impact-on-system-performance/ 了解上下文切换及其对系统性能的影响
- https://www.quora.com/Why-is-context-switching-fast-in-a-user-level-thread-and-slow-in-a-kernel-level-thread 为什么上下文切换在用户级线程中快速而在内核级线程中缓慢?- Quora
CPU和内存之间的三级缓存有了解吗?(2023 影石360)
序言
计算机上的程序和应用程序被设计为一组指令,由中央处理器解释和运行。当你运行一个程序时,指令从主存储(你的硬盘)到达中央处理器。这就是内存层次结构发挥作用的地方。
数据首先被加载到内存中,然后被发送到中央处理器。中央处理器每秒能够执行大量的指令。为了充分利用它的力量,中央处理器需要访问超高速内存,这就是中央处理器缓存的用武之地。
内存控制器从RAM中获取数据并将其发送到CPU缓存。
三级缓存
- L1缓存:是最小和最快的内存级别。通常为64KB大小,但处理器的每个核心都有自己独立的L1缓存,所以四核CPU的总共L1缓存大小为256KB。如果你在类似于CPU-Z的工具中查看内存详细信息,你会注意到L1缓存还分为两个更细的级别:L1-I(指令)和L1-D(数据)。L1指令缓存处理将要传送给处理器的信息,而数据缓存保存将写入主内存的信息。一级缓存能够以与CPU的最大操作速度一样快甚至更快地传输数据,使其非常高效。如果处理器在L1中找不到所需的数据,它将在L2和L3缓存中查找。
- L2缓存:是一种次级内存缓存,也嵌入在CPU的各个独立核心中。它通常比L1有更多的存储空间,但速度较慢,尽管仍远快于内存速度。一些高端处理器的L2缓存可能总共有32MB,但6-12MB可能是平均水平。正如前面提到的,这个缓存均分给所有核心使用,使每个核心能够独立地访问自己的缓存。
- L3缓存:作为一个共享存储池,整个处理器都可以访问。它比L1和L2缓存要慢得多,可能只有RAM速度的两倍快,但却是三个内存级别中最大的。如果CPU在缓存中找不到它需要的数据,它必须从较慢的系统内存中请求数据。这被称为缓存未命中。引入L3缓存降低了未命中的概率,因此有助于提高性能。在刚刚开发时,L3缓存通常位于主板上的一个单独芯片中。现代CPU几乎全部都将L3缓存集成到了内部以提高效率。
通过cpu-z可以看到三级缓存分布:
CPU缓存是如何工作的?
数据从RAM流向L3缓存,然后是L2,最后是L1。当处理器寻找数据进行操作时,首先尝试在L1缓存中找到它。如果CPU找到了,这种情况被称为缓存命中。然后继续在L2和L3中寻找。
如果CPU在任何内存缓存中找不到数据,它将尝试从系统内存(RAM)中访问它。当发生这种情况时,称为缓存未命中。
现在,我们知道缓存的设计是为了加快主内存和CPU之间信息的来回传输。从内存访问数据所需的时间称为“延迟”。
L1缓存具有最低的延迟,是最快且最接近核心的,而L3具有最高的延迟。当CPU必须从系统内存中检索数据时,内存缓存延迟会增加,即发生缓存未命中。
- https://www.howtogeek.com/891526/l1-vs-l2-vs-l3-cache/ L1、L2和L3缓存:有什么区别?
- https://www.makeuseof.com/tag/what-is-cpu-cache/ CPU缓存如何工作以及什么是L1、L2和L3缓存?
多核CPU下,三级缓存对于每个内核来说是共享的吗?那你知道它的数据存储以及指令存储的方式有了解过吗?(2023 影石360)
在多核CPU中,三级缓存(L3缓存)通常是为所有内核共享的,但这取决于CPU的设计。相比之下,L1和L2缓存通常是每个内核独立拥有的。
关于数据存储和指令存储:
- L1缓存:这是最靠近CPU核心的缓存,并且其访问速度也是最快的。它通常分为两部分:一部分用于存储指令(称为I-Cache),另一部分用于存储数据(称为D-Cache)。因为它位于核心最近,所以它的大小相对较小,但访问速度非常快。
- L2缓存:L2缓存是L1缓存后的第二层,它的大小通常比L1缓存大,但访问速度稍慢。在某些设计中,L2缓存也可能被分为指令和数据缓存,但在其他设计中,它可能是统一的缓存,同时存储指令和数据。
- L3缓存:这是多核CPU中为所有内核共享的缓存层。它的大小比L1和L2缓存都要大,但访问速度相对较慢。L3缓存通常是统一的缓存,用于存储指令和数据。
缓存的基本工作原理是预先加载最有可能被CPU核心访问的数据和指令,从而减少从主内存中获取数据的延迟。为了实现这一点,CPU使用了复杂的预测算法来尝试确定将来可能需要的数据和指令。
CPU指令重排序的好处?(2023 影石360)
CPU指令重排序(Instruction Reordering)是现代处理器为了提高执行效率而采用的一种优化策略。当指令之间不存在数据依赖性时,处理器可以改变指令的执行顺序。这种重排序可以在多个层次发生,例如编译器级别或微体系结构级别。
CPU指令重排序的好处如下:
- 提高流水线利用率:现代CPU使用指令流水线来并行执行多个指令。当某些指令(如访存指令)需要等待某些事件(例如缓存命中)时,而其后的指令又不依赖于它,重排序可以使后续指令继续执行,而不是空闲等待,从而提高流水线的利用率。
- 减少延迟:某些指令,特别是内存访问指令,可能需要数个时钟周期才能完成。通过重排序,处理器可以先执行其他不依赖的指令,而不是空闲等待,这样可以掩盖这些高延迟指令的影响。
- 优化缓存利用:通过指令重排序,处理器可以调整内存访问的顺序,提前预取数据,或使连续的内存访问更为集中,从而更有效地利用缓存。
- 并行执行:在多核或多执行单元的CPU中,指令重排序可以帮助确保各个执行单元都能得到足够的工作,从而实现真正的指令级并行。
- 改善能效:通过减少不必要的等待和提高指令执行的并行度,可以在较短的时间内完成更多的工作,从而提高能效。
但是,指令重排序也给多线程编程带来了复杂性,因为它可能会打破程序员预期的指令执行顺序,导致数据竞态或其他并发问题。为了正确地处理这些问题,程序员需要使用内存屏障、锁或其他同步机制
linux有几种IO模型(2023 阿里)
分配给进程的资源有哪些(2023 滴滴)
- CPU时间:每个进程都需要使用CPU来执行其指令。操作系统通过进程调度算法来决定哪个进程应该得到CPU时间。
- 内存空间:每个进程都需要内存来存储其代码、数据和运行时的状态信息。操作系统通过内存管理算法来分配和管理内存资源。
- I/O设备:包括硬盘、鼠标、键盘、打印机等。操作系统负责管理和调度进程对这些设备的访问。
- 文件:文件是一种常见的存储资源,操作系统通过文件系统来管理和控制进程对文件的访问。
- 网络:进程可能需要通过网络来进行数据传输和通信,操作系统负责管理和调度进程对网络资源的访问。
- 各种软件和库资源:例如数据库系统、图形处理库等。这些都是进程可能需要使用的资源,由操作系统进行管理和分配。
操作系统是怎么做内存管理的?(2023 小红书)
操作系统的内存管理确实是一个复杂而有趣的话题。一般来说,操作系统需要在保护、共享、虚拟化和物理内存管理四个方面进行平衡。以下是这四个方面的详细解释:
- 保护:操作系统需要保证每个进程都在其自己的内存空间中运行,以防止它们相互干扰。这通常通过硬件支持的内存保护机制来实现。
- 共享:虽然内存保护很重要,但有时候,不同的进程需要能够访问共享的内存区域。操作系统提供了一种机制,允许进程在需要的时候共享内存。
- 虚拟化:操作系统为每个进程提供了一种看似有很大的、连续的内存空间的幻象。这实际上是通过一种叫做内存虚拟化的技术实现的,这使得每个进程都认为它有自己的私有内存,尽管实际上物理内存被所有进程共享。
- 物理内存管理:操作系统需要管理物理内存,这包括哪些内存被使用,哪些内存是空闲的,以及如何分配和回收内存。
如果非要说一种管理策略,有一种叫做“jemalloc”的内存分配策略。这种策略是一种用于处理动态内存分配的技术。在这种策略中,内存被分成不同大小的块,例如16KB,32KB,64KB等。这些块是2的幂,因此可以通过位操作快速分配和释放。这种策略的好处是它可以减少内存碎片,同时还可以提高内存的分配速度。
当进程需要更多的内存时,jemalloc会尝试找到比所需内存大的第一个2的幂的内存块。如果这样的块不存在,它会尝试找到一个更大的块,然后将这个块分割成两个更小的块。如果这个更大的块仍然不足以满足需求,它就会向操作系统请求更多的内存。
这种策略允许jemalloc在需要的时候快速找到合适大小的内存块,而不需要遍历所有的空闲内存块。这使得jemalloc在面对大量小型内存分配请求时表现出色。
✨ 怎么向操作系统申请内存空间?(2023 小红书)【2023热门问题】
brk和mmap系统调用,brk申请堆内存,mmap分配文件映射区和匿名映射区
进程确实是通过系统调用,如 brk 和 mmap 向操作系统申请内存的。以下是这两个系统调用的一些详细信息:
brk:这是一个用于改变进程堆大小的系统调用。堆是用于动态内存分配的内存区域(如通过 malloc、calloc、realloc 和 free 这样的C库函数)。当进程调用 brk 来改变堆的结束地址时,操作系统可以根据需要分配更多的物理内存给进程,或者回收未使用的内存。值得注意的是,brk 只能用于改变堆的大小,而不能用于改变栈的大小。mmap:这是一种更通用的内存管理系统调用,可以用于实现内存映射。内存映射可以有多种用途,如文件映射和创建共享内存。mmap 还可以创建匿名映射,这是一种没有与文件系统关联的内存区域,可以用于进程间通信或者替代 malloc 和 free 进行内存管理。mmap 调用允许进程显式地控制内存的分页行为,包括页错误处理、预取、同步和保护等。
这两个系统调用是操作系统提供的基本内存管理工具,可以直接由进程使用,也可以被更高级的内存管理库,如 jemalloc 或C库的 malloc 和 free 函数所使用。
有没有更快的申请内存方式(内存分配优化策略)?(2023 滴滴实习)
- 内存池(Memory Pool):内存池是一种内存分配策略,预先在堆中分配一大块内存,然后由应用程序自行管理这块内存。当需要分配内存时,直接从内存池中取,而不是每次都去调用
malloc或new。同样,内存释放时,也是返回到内存池,而不是直接调用free或delete。这样可以大大减少系统调用的次数,提高内存分配和释放的效率。 - 对象池(Object Pool):对象池是内存池的一种应用,主要用于频繁创建和销毁的小对象。它会预先创建一些对象并保存在池中。当需要对象时,从池中获取而不是创建新的对象;当对象不再需要时,返回到池中而不是销毁。这样可以减少对象创建和销毁的开销。
- 使用定制的内存分配器:有些内存分配器可以针对特定的使用模式进行优化,比如Google的tcmalloc、Facebook的jemalloc等。
- 零拷贝(Zero Copy):零拷贝是一种可以减少CPU复制数据的技术。这种技术主要用于网络数据传输,但也可以用于内存分配。通过直接操作数据的地址,而不是复制数据,可以大大提高效率。
申请一块大内存和一块小内存的效率是一样的吗?(2023 滴滴实习)
申请一块大内存和一块小内存的效率并不完全相同。下面是几个可能影响效率的因素:
- 内存管理策略:操作系统和内存分配库(如glibc中的malloc)通常使用不同的策略来处理大块和小块内存的分配。例如,对于小块内存的分配,它们可能使用分段列表(segregated lists)或位图(bitmaps)等数据结构来快速查找合适的空闲块。对于大块内存的分配,它们可能使用更复杂的数据结构,如平衡树或堆,以便在可能的空闲块中找到最合适的一块。这些策略的区别可能导致大块和小块内存分配的效率不同。
- 内存碎片化:如果频繁地申请和释放小块内存,可能导致内存碎片化,即空闲内存被分割成许多小块,而无法满足大块内存的分配需求。反之,如果分配的内存大部分是大块内存,那么可能较少遇到内存碎片化的问题。因此,内存碎片化也可能影响到内存分配的效率。
- 页故障(Page Faults):当申请一块大内存并访问它时,可能会触发更多的页故障,因为需要加载更多的物理内存页到内存中。页故障是一种昂贵的操作,会增加内存分配和访问的开销。
因此,申请大块内存和小块内存的效率并不完全相同,它们取决于许多因素,包括内存管理策略、内存碎片化、页故障等。在实际的编程中,应尽可能避免不必要的内存分配和释放,以提高程序的效率和性能。
jvm分代内存管理和操作系统内存管理的区别(2023 小红书)
- 操作系统的内存管理的主要目标是提供一个抽象的、连续的地址空间给每个进程,保护进程之间的内存,确保进程不会相互干扰,并在物理内存有限的情况下尽可能有效地分配和回收内存。另一方面,JVM的内存管理的目标更关注于对象的生命周期管理。Java具有自动垃圾收集(GC)的特性,其目标是自动识别并回收不再使用的对象,从而简化程序员的工作。
- 操作系统通常使用一种称为虚拟内存的技术,将物理内存抽象为连续的虚拟地址空间,并通过页表和硬件支持实现对虚拟地址到物理地址的映射。另一方面,JVM采用了分代收集策略,将内存分为新生代(Young Generation)、老年代(Old Generation)和永久代(Permanent Generation,Java 8以后被Metaspace替代)。这种策略基于两个观察结果:大部分对象的生命周期都很短,少数生命周期长的对象可能会存活很长时间。因此,JVM通过使用不同的垃圾收集算法和策略来处理这些不同的内存区域。
在这两个层次的内存管理之间还有一层:Java运行时环境(JRE)会从操作系统申请内存,然后将这些内存分配给JVM使用。在JVM内部,内存会被进一步划分为用于不同目的的各种区域,如Java堆(用于存储对象)、方法区(用于存储类的元数据)以及各种线程栈(用于存储局部变量和方法调用的上下文)等。
fork()读时、共享写时的拷贝是怎样的?(2023 滴滴实习)
在Linux中,fork()是一个用来创建新进程的系统调用。当一个进程调用fork()时,会创建一个新的进程,这个新进程是原进程的副本,包括原进程的代码段、数据段、堆和栈等。
具体到内存的复制,Linux采用了写时复制(Copy-on-Write,COW)的策略。这是一种可以提高性能和内存利用率的技术。
**写时复制(COW)**是这样的一种策略:当进行fork()操作时,子进程并不立即复制父进程的所有内存页,而是父子进程共享同一份物理内存,同时标记这些内存页为只读。只有当进程试图写入这些内存页时,内核才会为写入操作的进程创建该页的一个拷贝,然后修改页表以将虚拟内存重新映射到新的物理内存页。这就是所谓的"写时复制"。
这样做的优点是,如果子进程并没有修改内存,那么就不需要真正的复制内存,从而节省了大量的内存。同时,由于不需要立即复制所有内存,fork()操作可以更快地完成。
需要注意的是,这种机制只适用于虚拟内存系统,并且需要操作系统的支持。在没有这种机制的系统中,fork()操作可能需要花费更长的时间,并且会消耗更多的内存。
死锁的必要条件是什么?(2023 百度提前批)
死锁的必要条件通常被归结为四个基本条件,它们都必须同时满足才能发生死锁。这四个条件也被称为死锁的四个"Coffman"条件,得名于1971年由E.G. Coffman Jr.等人在其论文中首次提出。这四个条件包括:
- 互斥:资源至少有一个是不能被共享的,即在一段时间内只能被一个进程使用。如果其他进程请求该资源,那么请求进程必须等待直到占有资源的进程已经释放。
- 占有并等待:一个进程因请求占用资源而被阻塞时,对已获得的资源保持不放。
- 非抢占:进程已获得的资源在未使用完前不能被其他进程强行剥夺,只能由拥有资源的进程主动释放。
- 循环等待:在发生死锁时,必然存在一个进程—资源的环形链,即进程集合{P0, P1, …, Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已经被P0占用的资源。
只有在满足这四个条件的情况下,才可能出现死锁。
top命令有哪些参数,说一下(2023 美团)
top命令是一个用于实时监控系统资源和进程的命令,它可以显示当前运行的进程、CPU使用情况、内存使用情况等信息。以下是一些常用的top命令参数:
- -d <秒数>:指定top命令刷新的时间间隔,默认为3秒。
- -n <次数>:指定top命令执行的次数后自动退出。
- -p <进程ID>:指定要监控的进程ID。
- -u <用户名>:只显示指定用户名的进程。
- -s <排序字段>:按指定字段对进程进行排序,常见的字段有cpu(CPU使用率)、mem(内存使用率)等。
- -H:显示进程的层次关系。
- -i:只显示运行中的进程,不显示僵尸进程。
怎么显示线程?(2023 美团)
在Linux中,可以使用以下命令来显示线程:
- top命令:在top命令的默认显示中,可以看到每个进程的线程数(Threads列)。例如,执行top命令后,按下"Shift + H"键可以切换到线程视图,显示每个进程的线程信息。
- ps命令:通过ps命令结合选项来显示线程。例如,使用"ps -eLf"命令可以显示系统中所有线程的详细信息。
虚拟地址是怎么转化到物理地址的?(2023 字节)
虚拟地址到物理地址的转换是通过操作系统中的内存管理单元(MMU,Memory Management Unit)来完成的。下面是一般的虚拟地址到物理地址转换过程:
- 程序发出内存访问请求时,使用虚拟地址进行访问。
- 虚拟地址被传递给MMU进行处理。
- MMU中的地址映射表(页表)被用来将虚拟地址转换为物理地址。页表是一种数据结构,用于存储虚拟地址和物理地址之间的映射关系。
- MMU根据页表中的映射关系,将虚拟地址转换为对应的物理地址。
- 转换后的物理地址被传递给内存系统,用于实际的内存访问操作。
页表是怎么构成的?(2023 字节)
页表是一种数据结构,用于存储虚拟地址和物理地址之间的映射关系。多级页表将页表分为多个层级,每个层级的页表项存储下一级页表的物理地址。通过多级索引,可以逐级查找,最终找到对应的物理页。
对于 64 位的系统,主要有四级目录,分别是:
- 全局页目录项 PGD
- 上层页目录项 PUD
- 中间页目录项 PMD
- 页表项 PTE
共享内存是怎么实现的?(2023 字节)
共享内存的机制,就是拿出一块虚拟地址空间来,映射到相同的物理内存中。这样这个进程写入的东西,另外一个进程马上就能看到了,都不需要拷贝来拷贝去,传来传去,大大提高了进程间通信的速度。

操作系统原子操作怎么实现的?(2023 字节)
操作系统中的原子性操作是通过硬件和软件的支持来实现的。在多核处理器上,原子性操作需要保证在多个核心之间的并发执行中的正确性和一致性。
硬件层面上,现代处理器提供了一些特殊的指令或机制来支持原子性操作,例如原子交换(atomic exchange)、原子比较并交换(atomic compare-and-swap)等。这些指令能够在执行期间禁止中断或其他核心的干扰,确保操作的原子性。
软件层面上,操作系统提供了一些原子性操作的接口或函数,例如原子操作函数(atomic operation),它们使用了硬件提供的原子性指令来实现原子性操作。这些函数通常是在内核态下执行,可以保证在多个进程或线程之间的原子性。
操作系统还可以使用锁机制来实现原子性操作。例如,互斥锁(mutex)可以用来保护共享资源的访问,只有持有锁的进程或线程可以访问共享资源,其他进程或线程需要等待锁的释放。通过锁的机制,可以保证对共享资源的原子性操作。
Docker镜像文件是怎样的?(2023 快手)
Docker 镜像的文件系统是由多个层次组成的,这些层次是叠加起来构建出最终的镜像的。当我们创建一个 Docker 容器时,Docker 会在已有的镜像层之上添加一个新的可写层,也就是容器层。
以下是 Docker 镜像文件系统的特点:
- 联合文件系统:Docker 使用联合文件系统(如 Overlay2, AUFS 等)来叠加多个层。每个层都是前一个层的增量更改。
- 不可变性:除了最上面的容器层,所有的镜像层都是只读的。
- 重用与共享:多个容器可以共享相同的底层镜像层,这使得容器启动非常快速且节省了磁盘空间。
- 增量存储:每次我们基于现有镜像创建新的 Docker 镜像或通过 Dockerfile 执行指令时,就会创建一个新的层。这种方式使得镜像的存储非常高效。
- 容器层:当容器运行时,所有的更改(例如写文件、删除文件)都会在容器层上发生。这保证了底层镜像的不可变性。
要查看 Docker 镜像的各个层,可以使用 docker history <image_name> 命令。
简而言之,Docker 镜像的文件系统是由多个叠加的层组成,这些层构建了一个统一、完整的文件系统视图,但实际上每一层都是独立存储的。
时间轮的概念(2023 得物)
时间轮是一种调度模型,用于有效地处理批量周期性任务。它将大量的定时任务绑定在一个调度器上,并通过这个调度器来进行统一管理和触发。时间轮算法利用线程资源实现批量化调度,使得延迟任务和周期性任务能够高效地进行调度和执行。
时间轮的工作原理可以简单理解为一个环形的数据结构,包含多个槽(slot),每个槽又包含一个任务链表。时间轮按照一定的时间间隔(例如1秒)不断地进行转动,当时间轮的指针指向某个槽时,就触发该槽中的所有任务。任务链表中的任务可以根据自身的定时规则进行触发,例如延迟一段时间后执行或在指定的时间点执行。
时间轮的实现方式有多种,一种常见的方式是使用哈希表和链表来实现。哈希表用于将任务按照其触发时间进行索引,而链表用于存储具体任务的执行信息。通过这种方式,时间轮能够快速地找到需要触发的任务,并按照预期的时间顺序进行执行。
时间轮算法具有较高的性能和扩展性,适用于延迟任务和周期性任务的调度。它在实际应用中有广泛的应用,例如定时器、网络框架、消息引擎等领域。
linux内存中的 reserver ,commited代表什么意思(2023 快手)
"reserved"是指在Linux系统中,一部分内存被保留起来并不被分配给应用程序使用。这部分内存是由内核保留的,一般无法通过普通的应用程序访问到。保留内存可以包括一些特殊用途的内存区域,例如专门用于虚拟化或系统服务的预留内存区域。
"committed"代表已分配的内存,即已经由进程申请并由内核分配的内存空间。这块内存已经在页表中有了记录,保证了其他进程不会被占用。在Java中,"committed"也可以表示通过mmaped PROT_NONE方式申请的虚拟地址空间,已在页表中有对应记录。
Java线程几种状态?linux进程几种状态?(2023 快手)
Java线程的状态有以下几种:
- 新建状态 (NEW): 当创建了线程对象后,即处于这种状态,例如:
Thread t = new Thread() - 就绪状态 (RUNNABLE): 当调用线程对象的
start()方法,线程即处于就绪状态。此时,它已加入到调度队列,等待获取CPU的执行权。 - 运行状态 (RUNNING): 线程获取CPU的执行权后,即处于运行状态。
- 阻塞状态 (BLOCKED): 当线程等待锁时进入阻塞状态。
- 等待状态 (WAITING): 当线程调用
Object.wait(),Thread.join()或LockSupport.park()时,它会进入等待状态。 - 超时等待状态 (TIMED_WAITING): 当线程调用有超时参数的方法如
Thread.sleep(long millis),Object.wait(long timeout), 或Thread.join(long millis)时,它会进入超时等待状态。 - 终止状态 (TERMINATED): 线程执行完毕或者因异常终止。
Linux进程的状态有以下几种:
- 运行 (Running): 进程正在运行或在运行队列中等待运行。
- 中断 (Interruptible sleep): 进程正在等待某个条件的出现。
- 不中断 (Uninterruptible sleep): 进程在等待某些特定的事件,此时不能被中断。
- 僵尸 (Zombie): 进程已终止,但是父进程还没有获取其终止状态。
- 停止 (Stopped): 进程已停止,通常是因为它接收到一个
SIGSTOP,SIGTSTP,SIGTTIN或SIGTTOU信号。 - 追踪 (Traced or Paged): 进程因调试而被停止。
🧩 数据结构
红黑树说一下,跳表说一下?(2023 美团)
红黑树(Red-Black Tree)是一种自平衡的二叉搜索树,它在插入和删除操作后能够通过旋转和重新着色来保持树的平衡。红黑树的特点如下:
- 每个节点都有一个颜色,红色或黑色。
- 根节点是黑色的。
- 每个叶子节点(NIL节点)都是黑色的。
- 如果一个节点是红色的,则它的两个子节点都是黑色的。
- 从根节点到叶子节点或空子节点的每条路径上,黑色节点的数量是相同的。
红黑树通过这些特性来保持树的平衡,确保最长路径不超过最短路径的两倍,从而保证了在最坏情况下的搜索、插入和删除操作的时间复杂度都为O(logN)。
跳表(Skip List)是一种基于链表的数据结构,它通过添加多层索引来加速搜索操作。
跳表的特点如下:
- 跳表中的数据是有序的。
- 跳表中的每个节点都包含一个指向下一层和右侧节点的指针。
跳表通过多层索引的方式来加速搜索操作。最底层是一个普通的有序链表,而上面的每一层都是前一层的子集,每个节点在上一层都有一个指针指向它在下一层的对应节点。这样,在搜索时可以通过跳过一些节点,直接进入目标区域,从而减少搜索的时间复杂度。
跳表的平均搜索、插入和删除操作的时间复杂度都为O(logN),与红黑树相比,跳表的实现更加简单,但空间复杂度稍高。跳表常用于需要高效搜索和插入操作的场景,如数据库、缓存等。
场景:
- epoll 用了红黑树来保存监听的 socket
- redis 用了跳表来实现 zset
平衡二叉树和完全二叉树的概念和区别?(2023 影石360)
平衡二叉树
平衡二叉树是一种特殊的二叉搜索树,其中每个节点的两个子树的高度差最多为一。这种平衡保证了树的高度大致保持在 log(n),其中 n 是树中节点的数量。这种平衡可以确保在二叉搜索树上的操作(如查找、插入和删除)的时间复杂度为 O(log n)。AVL树和红黑树都是平衡二叉树的例子。
完全二叉树
完全二叉树是一种二叉树,其中除了最底层外,其他所有层都被完全填充,并且所有节点都尽可能向左聚集。在实践中,完全二叉树主要用于实现优先队列和堆结构。
区别
- 平衡性:平衡二叉树要求每个节点的左右子树的高度差最多为1,而完全二叉树没有这样的要求。
- 完整性:完全二叉树要求除了最底层外,其他所有层都被完全填充,并且所有节点都尽可能向左聚集。平衡二叉树没有这样的要求。
- 用途:平衡二叉树常用于实现高效的搜索操作,因为它们的高度大致是 log(n),保证了操作的时间复杂度为 O(log n)。而完全二叉树主要用于实现优先队列和堆。
- 结构:平衡二叉树在插入和删除后,可能需要通过旋转操作来重新平衡。而完全二叉树在插入和删除后,通过上浮(upheap)或下沉(downheap)操作来保持其完整性。
有了解过哈希表吗?哈希表如何解决冲突?(2023 影石360)
哈希表
哈希表(也称为哈希映射)是一种数据结构,它实现了关联数组抽象数据类型,也就是可以将键映射到值。哈希表使用哈希函数将键(也称为哈希键)转换为数组的索引:如果两个键映射到了同一个索引,则产生了冲突。哈希表的主要优点是查找、插入和删除的平均时间复杂度都是 O(1)。
冲突解决
哈希表的冲突解决主要有以下两种技术:
- 开放寻址法:当哈希函数导致冲突时,开放寻址法会寻找其他未被使用的哈希地址。常见的开放寻址法有线性探查、二次探查和双重哈希等。这种方法的一个主要挑战是处理“聚集”问题,即冲突的哈希键聚集在哈希表的某些区域,导致查找时间的增加。
- 链地址法(拉链法):每一个哈希地址对应一条链表,所有映射到同一哈希地址的键都存储在这条链表中。当冲突发生时,只需在相应的链表中进行查找、插入或删除操作。这种方法的一个主要挑战是如果冲突太多,链表可能会变得很长,导致查找时间的增加。
nogo算法(2023 快手)
Nagao算法是一种快速统计文本中所有子串频次的算法,由东京大学的长尾真教授在1994年提出。该算法的核心思想是通过对文本中的射串进行排序来实现快速统计。
🎨 设计模式
适配器模式、装饰器模式、代理模式有什么区别?(2023 小红书)
- 适配器模式:适配器模式就像是一个电源适配器,它允许两个不兼容的接口可以一起工作。例如,一个类的接口与客户端代码需要的接口不一致时,可以通过创建一个适配器类来转换接口,使得客户端代码能够利用现有的类。
- 装饰器模式:装饰器模式可以动态地向对象添加额外的职责,而不改变其实现。装饰器封装了一个类,并提供和该类相同的接口,但在调用其方法时,可以额外执行一些操作。装饰器可以被无限地堆叠,每个装饰器都添加一些额外的行为。
- 代理模式:代理模式在不改变接口的前提下,为其他对象提供一个代理或占位符以控制对这个对象的访问。代理可以用于许多不同的目的,如安全控制、复杂性隐藏、延迟加载等。代理通常控制对其委托对象的访问,并可能选择创建或删除它。
综上所述,适配器模式用于让不兼容的接口能够一起工作,装饰器模式用于动态添加功能,代理模式用于控制对另一个对象的访问。
🖼️ 场景题
Java 程序运行了一周,发现老年代内存溢出,分析一下?(2023 美团)
老年代内存溢出表现为java.lang.OutOfMemoryError: Java heap space,通常是因为Java堆内存中长期存活的对象占用的空间过大,导致内存无法分配。下面从浅入深分析可能的原因和解决方法
- 堆内存设置不合理 首先检查Java堆内存的配置是否合适。通过-Xmx和-Xms参数设置堆内存的最大值和初始值。如果没有设置或设置过小,可能导致内存溢出。可以根据实际需求和硬件条件适当调整这两个参数的大小。
- 长期存活对象过多 检查程序中是否存在大量的长期存活对象。这些对象会导致老年代空间不足。可以通过以下方法解决:
- 优化代码,减少长期存活对象的数量。
- 使用缓存策略,如LRU算法,限制缓存对象的数量。
- 使用弱引用(WeakReference),使得在内存不足时,可以被垃圾回收器回收。
- 内存泄漏 内存泄漏是指程序中错误地持有了不再需要的对象引用,导致这些对象无法被垃圾回收器回收。需要检查代码,排查可能的内存泄漏问题。以下几种场景容易出现内存泄漏:
- 静态集合类(如HashMap、ArrayList等)中的对象没有被移除。
- 监听器或回调没有被正确注销。
- 线程池或数据库连接池没有正确关闭。
- 使用内存分析工具 使用内存分析工具(如VisualVM、MAT等)对程序进行内存分析,找出内存占用的瓶颈和内存泄漏的地方。具体操作步骤如下:
- 获取堆内存快照(Heap Dump)。
- 分析快照,找出内存占用最大的对象。
- 分析对象的引用链,找出持有这些对象引用的地方。
- 根据分析结果,修改代码,解决内存问题。
综上所述,发生老年代内存溢出时,可以从设置合理的堆内存大小、优化代码减少长期存活对象、排查内存泄漏、使用内存分析工具和垃圾回收器调优等方面入手,全面分析和解决问题。
如果核心线程数是 5,已经启动 4 个任务,后面又进来 1 个,是优先复用前面四个任务中的空闲线程还是重新创建新线程(2023 完美世界)
线程池是为了限制系统中执行线程的数量。根据系统的任务负载和资源容量,线程池可以灵活地调整线程的数量,优化线程的管理,这样可以减少线程创建和销毁带来的额外开销。
这个问题的答案取决于你使用的是什么样的线程池。如果你使用的是Java的ThreadPoolExecutor线程池,其行为会按照以下规则:
- 如果当前运行的线程数量小于核心线程数,即使线程池中存在空闲线程,新任务到来也会创建新的线程处理任务。
- 只有在运行的线程数量已经达到核心线程数,但是任务队列未满时,新任务会被放到任务队列中等待。
- 如果当前运行的线程数量等于最大线程数且任务队列已满,新任务将会被拒绝。 所以,在你提供的这种情况下,如果线程池使用的是Java的ThreadPoolExecutor,且核心线程数是5,已经启动4个任务,后面又进来1个任务,会新开一个线程处理新的任务,而不是复用前面四个任务中的空闲线程。这是因为核心线程数没有被用完,线程池会优先创建新的线程。
如果大量请求进来你怎么限流(2023 美团)
一些通用的限流手段是:
- 令牌桶:在令牌桶限流策略中,系统有一个令牌桶,桶中的令牌以一定的速率被添加。当一个新的请求到来时,系统会从桶中取出一个令牌。如果桶是空的,那么新的请求就会被拒绝。这种策略允许突然的大量请求,只要桶中有足够的令牌。在SpringCloud中可以使用spring-boot-starter-data-redis-reactive的令牌桶算法,根据Spring Cloud Gateway的客户端实际IP地址限制传入请求的速率。 简而言之,可以在路由上设置RequestRateLimiter过滤器,然后配置网关使用IP地址限制唯一客户端的请求。 在Spring Cloud中,你可以通过整合Redis以及使用Reactive编程模式来实现令牌桶算法。以下是一个基本的步骤:
首先,你需要在你的pom.xml文件中添加相关的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
在你的Spring Cloud Gateway应用中,你需要创建一个自定义的GatewayFilter。此过滤器将负责检查每个请求的IP地址,并限制每个IP地址的请求速率。
@Component
public class RateLimiterFilter implements GatewayFilterFactory<RateLimiterFilter.Config> {
private final RateLimiterService rateLimiterService;
public RateLimiterFilter(RateLimiterService rateLimiterService) {
this.rateLimiterService = rateLimiterService;
}
@Override
public GatewayFilter apply(Config config) {
return (exchange, chain) -> {
// 获取请求的IP地址
String ipAddress = exchange.getRequest().getRemoteAddress().getAddress().getHostAddress();
if (!rateLimiterService.isAllowed(ipAddress)) {
// 如果超过了限制,返回429状态码(Too Many Requests)
return Mono.error(new ResponseStatusException(HttpStatus.TOO_MANY_REQUESTS));
}
return chain.filter(exchange);
};
}
public static class Config {
// 配置属性可以在这里定义
}
}
然后,你需要创建一个RateLimiterService,在这个服务中,你可以使用令牌桶算法和Reactive Redis操作实现请求速率的限制:
@Service
public class RateLimiterService {
private final ReactiveStringRedisTemplate redisTemplate;
public RateLimiterService(ReactiveStringRedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
public boolean isAllowed(String ipAddress) {
// 使用Redis和令牌桶算法实现速率限制的逻辑
// 这个部分需要根据你的具体需求来实现
}
}
最后,在你的路由配置中使用这个过滤器:
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder, RateLimiterFilter rateLimiterFilter) {
return builder.routes()
.route(r -> r.path("/some-path/**")
.filters(f -> f.filter(rateLimiterFilter.apply(new RateLimiterFilter.Config())))
.uri("lb://some-service"))
.build();
}
- Sentinel 通过注解(@SentinelResource) 的方式将某个方法或者资源标记为受保护的资源,然后可以对这些资源设置各种规则,比如 QPS 限流,滑动窗口限流等。
例如:
@SentinelResource(value = "test", blockHandler = "exceptionHandler")
public String test() {
// your logic here
}
在这个例子中,test 方法被标记为受 Sentinel 保护的资源,如果这个方法的调用频率超过了设定的限制,Sentinel 就会调用 exceptionHandler 方法来处理这个问题。
- 使用消息队列 (MQ) 进行限流也是一个常见的做法。通过将请求放入消息队列中,然后通过调整处理请求的速度来实现限流。例如,你可以使用 RabbitMQ、Kafka 等消息队列技术,这种方式也可以起到异步处理的作用,提高系统的吞吐量。
写 MQ 时程序宕机了怎么办?(2023 美团)
如果在使用消息队列(MQ)时,生产者(Producer)程序在写入消息队列时宕机,那么你可能会面临消息丢失的问题。以下是一些可行的解决方案:
- 消息持久化:大多数消息队列系统(如RabbitMQ,Kafka)都支持消息的持久化。持久化的消息即使在宕机情况下也不会丢失,因为它们被存储在磁盘上。当服务器恢复后,可以继续从存储介质上读取并处理这些消息。但是,使用持久化会增加系统的开销并可能影响性能。
- 高可用配置:配置高可用集群可以提高系统的稳定性。对于Kafka,可以配置多个副本,当某个节点宕机时,其他节点可以继续提供服务。RabbitMQ 也支持类似的镜像队列(Mirrored Queues)机制。
- 生产者确认机制:许多消息队列系统提供了生产者确认(Producer Acknowledgments)机制,生产者只有在收到消息已成功写入消息队列的确认后,才会认为消息已成功发送。这样,如果在写入过程中服务器宕机,生产者知道消息没有成功发送,并且可以在服务器恢复后重新发送。
- 使用事务:如果你的应用场景允许,你可以使用事务来确保消息的完整性。在一次事务中,你可以将消息的发送和你的业务操作放在一起,要么都成功,要么都失败。但是,使用事务会增加系统的复杂性,并可能影响性能。
- 异步写入 + 本地日志:对于非常关键的消息,可以采取异步写入+本地日志的方式。先将消息写入本地日志,然后再异步写入消息队列,如果消息队列写入失败,通过后台进程重试,直到写入成功。
在设计和选择方案时,需要根据你的应用的具体需求和可接受的复杂性进行权衡。例如,你需要考虑你的应用是否能接受消息的丢失,是否需要保证消息的顺序,你的系统是否能承受持久化和事务的开销,以及你的系统是否有足够的资源来支持高可用配置。
秒杀场景下扣减库存太慢了怎么办?(2023 滴滴)
如果在秒杀场景下扣减库存的过程太慢,那么可能会导致系统的响应时间变长,用户体验下降,甚至系统过载。以下是一些优化扣减库存过程的建议:
- 使用内存数据库:相比于传统的关系型数据库,内存数据库如Redis的读写速度更快,适合处理高并发请求。你可以在活动开始前将库存信息预加载到Redis中,用户抢购时直接在Redis中扣减库存,活动结束后再将Redis中的数据同步回数据库。
- 异步处理:用户的抢购请求可以先进入消息队列,由后台服务异步处理。这样用户的请求就可以立即得到响应,提高了用户体验,同时也减轻了服务器的压力。
- 数据库优化:如果仍然使用关系型数据库,可以通过数据库层面的优化来提高效率,例如选择合适的索引、调整事务的隔离级别、使用批处理等。
- 减少数据库操作:每次扣减库存时都需要更新数据库,这会占用大量的I/O资源。你可以采用一些方法来减少数据库操作,例如将用户的请求先暂存起来,当积累到一定数量或者过了一段时间后再批量更新到数据库。
- 使用分布式系统:如果你的系统规模较大,可以考虑使用分布式系统来分担压力。例如,可以使用分布式数据库、分布式缓存、分布式计算等技术。
短信登录的短信怎么发送的(2023 滴滴)
短信登录的过程通常如下:
- 用户在应用程序或网站上输入手机号码。
- 系统验证该手机号码的格式是否正确。
- 如果手机号码正确,系统将生成一个随机的验证码。
- 系统使用短信服务提供商(如Twilio, Alibaba SMS Service等)将验证码作为短信发送到用户的手机号码上。
- 用户收到短信后,将验证码输入应用程序或网站。
- 系统验证输入的验证码是否与发送的验证码一致。
- 如果一致,系统允许用户登录。
旁路缓存机制具体解决的什么场景(2023 滴滴)
旁路缓存(Sidecar Caching)是一种在获取数据时避免缓存穿透、缓存击穿和缓存雪崩等问题的策略。在使用Redis作为缓存系统时,我们可以使用旁路缓存策略来提高系统的稳定性和性能。
旁路缓存与普通缓存的主要区别在于其处理缓存未命中的策略。普通缓存在未命中时会直接让所有相关的请求去数据库中获取数据,但这在高并发的环境中可能导致数据库的负载过大。另外,如果数据库中也没有数据,那么这些请求可能会重复地查询数据库,这种情况被称为缓存穿透。
旁路缓存策略则在缓存未命中时,会先将所有请求暂时挂起,然后由一个专门的线程或进程去数据库中获取数据并更新缓存。这样,其他的请求只需要等待缓存被更新,而不需要自己去数据库中获取数据。这可以有效地降低数据库的负载,并且减少缓存穿透的可能。
旁路缓存的目的主要是保护数据库,防止在高并发的环境下由于缓存未命中导致数据库的负载过大。同时,它也可以减少缓存穿透的可能,提高系统的稳定性和性能。
写:
- 先更新DB。
- 然后直接删除cache。

读:
- 从cache中读取数据,读取到就直接返回。
- cache中读取不到的话,就从DB读取返回。
- 再把数据写到cache中。
如果在写数据的过程中,可以先删除cache,再更新DB吗? 在写入数据时,采用“先删除缓存,再更新数据库”的策略是一种常见的做法。这种策略被称为"Cache-Aside"模式或"先删后写"策略。 其主要步骤如下:
- 删除缓存:在更新数据库之前,首先删除对应的缓存数据。
- 更新数据库:删除缓存后,再去更新数据库。 但这个策略需要注意的问题是,如果在你删除了缓存后,和数据库更新之间的这段时间里,如果有其他请求查询这个数据,那么这个查询请求可能会因为在缓存中没找到数据,去数据库中查询并将查询结果写入缓存。这时,再去更新数据库就可能会导致缓存与数据库中的数据不一致。 为了避免这种情况,你可以使用一种称为“读写锁”的机制。在更新数据时,首先获取写锁,然后删除缓存并更新数据库,最后释放写锁。在读取数据时,首先获取读锁,然后从缓存中获取数据,如果缓存中没有数据,就去数据库中查询并更新缓存,最后释放读锁。这样就可以确保数据的一致性。
如果先写BD,再删除cache就不会造成数据不一致了吗? "先写数据库,再删除缓存"也是一种常见的处理方式,其理论上可以避免"先删缓存,再写数据库"策略中可能出现的数据不一致问题。 在"先写数据库,再删除缓存"策略中,由于数据已经被先更新到数据库,即使在更新数据库和删除缓存的短暂时间间隔内有新的读请求到达并更新了缓存,该缓存数据也是最新的,因此不会出现数据不一致的问题。 然而,这种策略也有其自身的问题。在并发环境下,如果两个请求,一个是写请求,一个是读请求,它们几乎同时到达,可能会出现以下情况:
- 写请求先更新了数据库
- 读请求读取数据库,并将数据写入缓存
- 写请求删除了缓存 在这种情况下,缓存就会丢失,导致后续的读请求必须直接访问数据库,这可能会增加数据库的负载。因此,不论是"先删缓存,再写数据库"还是"先写数据库,再删缓存",都有可能存在问题
更新缓存失败了怎么办(2023 滴滴)
- 重新尝试:如果错误是暂时的,例如网络抖动,那么你可以尝试再次更新缓存。
- 失败后的兜底策略:如果缓存系统存在问题且无法立即修复,可以考虑暂时绕过缓存,直接访问原始数据源。这可以确保业务的正常运行,但可能会增加原始数据源的负载。
重试的时候,缓存中的错数据被访问多次了,怎么解决(2023 滴滴)
当尝试更新缓存时,如果数据已经被错误地写入到缓存中,那么这个错误数据可能会被多次访问。这是一个常见的问题,有几种可能的解决方案:
- 延迟更新:一种方法是在写入新数据之前,先将旧数据从缓存中删除,然后再写入新数据。这可以确保在新数据还没有被写入缓存时,客户端只能获取到旧的数据,而不是错误的数据。然而,这可能会导致缓存“空窗期”的问题。
- 读写锁:使用读写锁可以保证在写入新数据时,不会有读取操作发生。在更新缓存的过程中,写操作将会锁定数据,读操作将会被阻塞,直到新的数据写入完毕。
- 乐观并发控制:你可以使用乐观并发控制,只有在数据没有发生改变的情况下,才能更新缓存。这需要在原始数据源中保存数据版本信息,并在更新缓存时检查数据版本。
- 原子操作:一些缓存系统支持原子操作,可以确保数据的更新是原子的,即数据的更新要么全部成功,要么全部失败,不会出现部分成功的情况。
如何设计抢优惠券?(2023 滴滴)
设计一个抢优惠券的系统可以涉及到很多方面,包括并发控制、数据一致性、通知机制等等。以下是一个基本的设计思路:
- 预热数据:为了减少数据库的压力,可以在活动开始之前将优惠券的信息预热到缓存中,例如使用Redis。
- 限流:由于抢优惠券的活动可能会产生巨大的流量,需要采取限流措施防止服务器过载。可以使用如令牌桶或漏桶等限流算法。
- 并发控制:为了处理大量用户同时抢购的情况,可以采用Java的并发处理能力,如线程池、CompletableFuture等。也可以采用分布式系统设计,使用多个服务器共同处理请求。
- 数据一致性:为了避免超卖的问题,需要确保数据的一致性。这可以通过事务控制或分布式锁等方式实现。例如,使用Redis或ZooKeeper实现分布式锁。
- 异步处理:抢购的请求可以通过消息队列异步处理,不仅可以减轻服务器的压力,还可以提高用户的体验。比如,用户点击抢购后,立即返回一个正在处理的响应,然后通过消息队列在后台处理抢购的逻辑。
- 通知用户:当抢购处理完后,需要及时通知用户结果。可以通过邮件、短信、应用内通知或者推送通知等方式。
- 容错和备份:系统需要有足够的容错和备份机制,以便在出现问题时快速恢复。
- 监控和报警:设置监控和报警机制,对系统的运行状态进行实时监控,一旦发现异常,立即触发报警,便于及时处理。
有一个程序占用大量 cpu,并且一直运行,怎么排查?(2023 阿里实习)
- 识别问题进程:使用top或htop命令(Linux/macOS)或任务管理器(Windows)检查系统状态,找到占用大量CPU的Java进程。记下进程ID(PID)。
- 获取线程信息:对于找到的Java进程,我们可以使用jstack工具获取线程信息。jstack是Java Development Kit(JDK)中的一个实用程序,用于生成Java线程转储。运行以下命令:
jstack <PID> > thread_dump.txt
- 分析线程转储:打开thread_dump.txt文件,查找具有高CPU使用率的线程。线程转储中的每个线程都有一个16进制的线程ID(nid)。找到状态为RUNNABLE且堆栈跟踪表明可能在执行密集任务的线程。
- 关联操作系统线程:要确定哪些线程正在使用大量CPU资源,我们需要将Java线程与操作系统线程关联起来。在Linux上,可以使用
top -H -p <PID>命令查看特定进程的线程CPU使用情况。在Windows上,可以使用Process Explorer或Process Monitor等工具查看线程CPU使用情况。将操作系统线程ID转换为16进制,然后与thread_dump.txt中的线程进行匹配。 - 定位问题代码
两个包含5亿URL的文件,如何找到两个文件的重复URL,内存只有4G(2023 百度提前批)
处理两个包含5亿个URL的文件来找出重复URL,是一个内存和计算密集型的任务。在有限的内存下,我们需要考虑使用一些高效的数据处理技术,如外部排序和分布式计算。这里,我们将主要探讨使用基于硬盘的外部排序和哈希映射方法。
我们可以按以下步骤进行:
步骤1: 预处理并切割文件 首先,由于文件的数据量太大,无法一次性装入内存,我们需要将每个文件切分成更小的分区。我们可以将URL按照一定的哈希函数分桶(如URL的哈希值对10000取余),将相同哈希值的URL写入到同一个文件中,这样可以保证相同的URL一定在同一个文件中。
步骤2: 逐一处理切割后的文件 将切割后的小文件依次加载进内存中,对每个文件使用HashSet去重,然后保存到一个临时文件。
步骤3: 两两对比找出重复的URL 最后,我们再把第一个文件和第二个文件相同哈希值的临时文件分别加载到内存,然后用一个HashSet保存第一个文件的URL,遍历第二个文件的URL,如果在HashSet中找到就说明是重复的URL。
以上步骤需要进行的IO操作相当多,会消耗较大的时间。这是因为我们是在内存不足的情况下处理大数据问题,所以要通过牺牲时间来换取空间。在实际的大数据处理中,我们通常会使用更高效的工具如Spark、Hadoop等分布式处理工具来进行处理。
一瞬间提交140个请求,核心线程数为40,最大线程数为100,请求最大延迟为5ms,平均rt为3ms,如何设计线程池参数降低处理延迟?(2023 快手)
为了降低处理延迟,首先要确保线程池参数配置合理。考虑到您的场景,这里是一个建议的线程池参数配置:
- 核心线程数 (Core Pool Size): 由于你提到核心线程数为40,这是一个合理的起点,因为这确保了常驻的40个线程随时等待处理新的请求。
- 最大线程数 (Maximum Pool Size): 考虑到一瞬间会有140个请求,100的最大线程数似乎也是合理的。但请确保服务器的硬件可以同时处理这么多线程,否则可能会导致性能下降。
- 等待队列 (Queue): 你可以选择使用一个有界队列,如
LinkedBlockingQueue,其容量可以设置为(总的一瞬间的请求数 - 最大线程数),即40。这样,在瞬间涌入的140个请求中,100个请求会立即被100个工作线程处理,其余的40个请求会被放入等待队列中。 - 拒绝策略 (RejectedExecutionHandler): 当所有线程都在工作,而且队列也满了时,你需要一个策略来处理新进来的请求。一个合理的选择是
CallerRunsPolicy,它实际上是在调用者的线程中运行任务,从而实现一种回压效应。 - 线程超时 (Keep-alive times): 如果你不希望非核心线程长时间空闲等待,可以设置一个合理的超时时间,例如60秒,这样线程在空闲超过这个时间后就会被终止。
代码如下:
ThreadPoolExecutor executor = new ThreadPoolExecutor(
40, // 核心线程数
100, // 最大线程数
60L, // 线程空闲时间
TimeUnit.SECONDS, // 线程空闲时间的单位
new LinkedBlockingQueue<Runnable>(40), // 等待队列
new ThreadPoolExecutor.CallerRunsPolicy()); // 拒绝策略
最后,还要考虑操作系统和硬件的限制。如果你发现线程上下文切换太频繁,导致性能问题,那么可能需要减少最大线程数。同时,确保系统的其他应用或服务不会与此线程池争用太多的资源。
一个保存字符串的超大文件,如何判断一个字符串在不在这个文件这种。(2023 快手)
- 分治 + hashmap
假如有成千上百万条数据,内存空间无限大,怎么快速的往HashMap中插入数据?(2023 快手)
- 预估容量和负载因子
在创建HashMap实例时,你可以预估数据量并据此设置初始容量。这有助于减少rehashing(重新哈希)的次数。
javaCopy codeint initialCapacity = 1000000; // 根据预估的数据量设置
float loadFactor = 0.75f; // 默认值,可以根据需要调整
HashMap<String, String> map = new HashMap<>(initialCapacity, loadFactor);
- 并发插入
如果数据插入没有依赖关系,你可以考虑使用多线程进行并发插入。不过,请注意,普通的HashMap是非线程安全的。你可以使用ConcurrentHashMap来进行线程安全的并发插入。
ConcurrentHashMap<String, String> concurrentMap = new ConcurrentHashMap<>(initialCapacity, loadFactor);
- 批量插入
最直接的方式是使用putAll方法,该方法接受一个Map参数,将其中所有键-值对都插入到目标HashMap中。但是要注意,这并不会比逐一使用put方法插入快得多。
Map<String, String> existingMap = new HashMap<>();
Map<String, String> newEntries = new HashMap<>();
// ...填充newEntries
existingMap.putAll(newEntries);
🌀 其他
讲一讲cms?
内容管理系统(英语:content management system,缩写为 CMS)是指在一个合作模式下,用于管理工作流程的一套制度。该系统可应用于手工操作中,也可以应用到电脑或网络里。作为一种中央储存器(central repository),内容管理系统可将相关内容集中储存并具有群组管理、版本控制等功能。版本控制是内容管理系统的一个主要优势。
内容管理系统在物品或文案或数据的存储、掌管、修订(盘存)、语用充实、文档发布等方面有着广泛的应用。现在流行的开源CMS系统有WordPress、Joomla!、Drupal、Xoops、CmsTop等。
DTS 了解过吗?(2023 小红书【数据库dts方向】)
数字剧院系统(DTS,Digital Theater Systems)由DTS公司(DTS Inc.,NASDAQ:DTSI)开发,为多声道音频格式中的一种,广泛应用于DVD音效上。其最普遍的格式为5.1声道。与杜比数字为主要竞争对手。要实现DTS音效输出,需在硬件上及软件上符合DTS的规格,多数会在产品上标示DTS的商标。
了解过蚂蚁的 oceanbase 吗?(2023 蚂蚁金服)
OceanBase是一个开源的分布式关系型数据库,完全兼容MySQL。它完全由蚂蚁集团开发,并建立在一个公共服务器集群上。基于Paxos协议及其分布式结构,OceanBase提供高可用性和线性可扩展性。
参考: