Rust读书笔记-基础篇
Rust读书笔记-基础篇

感谢Rust语言圣经(Rust Course),正如书中所说在学习 Rust 的同时你会收获很多语言之外的知识,因此 Rust 在入门阶段比很多编程语言要更难,但是一旦入门,你将收获一个全新的自己,成为一个更加优秀的程序员。
要学好 Rust,你需要深入理解内存、堆栈、引用、变量作用域等这些其它高级语言往往不会深入接触的内容。另外,Rust 会通过语法、编译器和 clippy 这些静态检查工具半帮助半强迫的让你成为更优秀的程序员,写出更好的代码。同时,当你掌握 Rust 后,就会自发性的想要去做一些更偏底层的开发,这些都可以帮助你更加了解操作系统、网络、性能优化等底层知识,也会间接或者直接的接触到各种算法和数据结构的实现。
🔥笔记特色:建议结合Rust语言圣经(Rust Course)一起观看,因为部分内容涉及个人思考和代码踩坑,可以助力学习!
- 该笔记使用的Rust版本为:
1.62
🔥其他推荐:
🥳 安装rust
安装日期:2023-05-03
Mac
brew install rust
cargo -V
Win
过程有点麻烦还要装VS,就直接在Mac上敲了
😎推荐 在线练习
点击进入PlayGroundWindows的备用方案 无需下载Rust开发环境,可直接在线编写代码,不是打广告,感觉还挺方便的
1.1 🤪 Hello Rust
- 这是最简单的写法:
fn main() {
println!("Hello, world!");
}
- 稍微进阶一点需要了解一点知识:
.iter()Rust 的集合类型不能直接进行循环,需要变成迭代器(这里是通过 .iter() 方法),才能用于迭代循环"{}"输出占位符,类似于其它语言惯用的 %s、%d&println! 宏需要一个引用作为参数,因为 Rust 的字符串类型是一个包含多个字节的 UTF-8 编码的向量,而不是一个简单的字符数组。因此,打印一个字符串需要将它的引用传递给 println! 宏。这样做是为了避免将整个字符串复制到堆栈上,而是使用指向原始数据的引用来进行处理。这种方式可以避免性能上的问题,并且与 Java 中的字符串处理方式有所不同。println!在 Rust 中,这是 宏 操作符,你目前可以认为宏是一种特殊类型函数println!是一个 Rust 标准库提供的宏,用于在控制台输出文本。在这里 "!" 表示宏定义的开始,然后后面的内容是宏参数。
fn greet_world() {
let southern_germany = "Grüß Gott!";
let chinese = "世界,你好";
let english = "World, hello";
let regions = [southern_germany, chinese, english];
for region in regions.iter() {
println!("{}", ®ion);
}
}
fn main() {
}
- 再稍微进阶一点(这个例子也来自Rust圣经,但是我感觉这个例子有点劝退),需要了解下面的知识才能理解:
let在 Rust 中,常量和变量的定义是通过 let 关键字来进行的,后面会说变量如何定义lines、enumerate等都可以通过其他语言直观理解- 可能遇到问题的是这个
if let Ok(length) = fields[1].parse::<f32>()parse方法的作用类似于 Java 中的 parseInt 方法,都是将一个字符串解析为数字fields[1].parse::<f32>()将第二个元素解析为一个 f32 类型的浮点数,如果解析成功,返回一个Result<f32, ParseFloatError>类型的 Ok 枚举值,否则返回一个 Err(ParseFloatError) 类型的错误值。
parse 其中,self 是一个字符串类型的引用,F 是要解析成的数据类型。parse 方法返回一个 Result<F, ParseError> 类型的枚举值,如果解析成功,返回一个 Ok(F) 枚举值,其中包含解析得到的数据;如果解析失败,返回一个 Err(ParseError) 枚举值,其中包含解析失败的原因。
pub fn parse<F>(&self) -> Result<F, ParseError>
where F: FromStr
示例代码:
fn main() {
let penguin_data = "\
common name,length (cm)
Little penguin,33
Yellow-eyed penguin,65
Fiordland penguin,60
Invalid,data
";
let records = penguin_data.lines();
for (i, record) in records.enumerate() {
if i == 0 || record.trim().len() == 0 {
continue;
}
// 声明一个 fields 变量,类型是 Vec
// Vec 是 vector 的缩写,是一个可伸缩的集合类型,可以认为是一个动态数组
// <_>表示 Vec 中的元素类型由编译器自行推断,在很多场景下,都会帮我们省却不少功夫
let fields: Vec<_> = record
.split(',')
.map(|field| field.trim())
.collect();
if cfg!(debug_assertions) {
// 输出到标准错误输出
eprintln!("debug: {:?} -> {:?}",
record, fields);
}
let name = fields[0];
// 1. 尝试把 fields[1] 的值转换为 f32 类型的浮点数,如果成功,则把 f32 值赋给 length 变量
//
// 2. if let 是一个匹配表达式,用来从=右边的结果中,匹配出 length 的值:
// 1)当=右边的表达式执行成功,则会返回一个 Ok(f32) 的类型,若失败,则会返回一个 Err(e) 类型,if let 的作用就是仅匹配 Ok 也就是成功的情况,如果是错误,就直接忽略
// 2)同时 if let 还会做一次解构匹配,通过 Ok(length) 去匹配右边的 Ok(f32),最终把相应的 f32 值赋给 length
//
// 3. 当然你也可以忽略成功的情况,用 if let Err(e) = fields[1].parse::<f32>() {...}匹配出错误,然后打印出来,但是没啥卵用
if let Ok(length) = fields[1].parse::<f32>() {
// 输出到标准输出
println!("{}, {}cm", name, length);
}
}
}
1.2 👀 变量
😉常规定义
写一个变量,只是用let定义
fn main() {
let x = 6;
println!("The value of x is: {}", x);
x = 1008611; // 这里是错误的
println!("The value of x is: {}", x);
}
// 错误:cannot assign twice to immutable variable `x`
如果要让它成为变量,需要加入mut
fn main() {
let mut x = 6;
println!("The value of x is: {}", x);
x = 1008611; // 这里是错误的
println!("The value of x is: {}", x);
}
在rust中常量使用const来定义:
const MAX_POINTS: u32 = 100_000;
可能会有疑问,rust为什么既然常量用const定义,变量要用let定义为什么要加入mut?
- 使用 let 声明的变量是可变的,而使用 const 声明的常量是不可变的。这意味着,使用 let 声明的变量可以在程序中修改它们的值,而使用 const 声明的常量一旦被定义,就不能再修改它们的值。在 Rust 中,为了提高代码的可靠性和安全性,推荐尽可能使用常量而不是变量
- 类型注解:使用 let 声明变量时,通常不需要显式指定变量的类型,因为 Rust 编译器可以根据变量的值推断出变量的类型。而使用 const 声明常量时,必须显式指定常量的类型,因为 Rust 编译器不能根据常量的值推断出常量的类型。例如:let x = 10; const Y: i32 = 20;
- 声明位置:使用 let 声明变量时,可以在任何作用域内进行声明,包括函数内部和全局作用域。而使用 const 声明常量时,只能在全局作用域中进行声明。这是因为在 Rust 中,常量的值必须在编译时就确定下来,而变量的值可以在运行时确定。
⛔不要警告我
如果你创建了一个变量却不在任何地方使用它,Rust 通常会给你一个警告。所以可以使用下划线_表示Rust 不要警告未使用的变量
fn main() {
let mut x = 6;
}
// warning: unused variable: `x`
✔️正确写法,我不禁感叹,这也TTMD安全了:
fn main() {
let mut _x = 6;
}
在一次实验中我未使用mut,都可以提示了warning: variable does not need to be mutable
fn main() {
let (a, mut b): (bool, bool) = (true, false);
println!("a = {:?}, b = {:?}", a, b);
}
变量的解构
这里可能有疑问的点是{:?},为什么不直接使用{}
{:?} 占位符会使用 Debug trait 来格式化输出变量的值。Debug trait 是 Rust 中的一个特殊 trait,用于定义格式化输出调试信息的方法。许多内置类型和标准库中的类型都实现了 Debug trait,因此你可以在使用 {:?} 占位符时直接输出这些类型的值。{:?} 占位符输出的值通常包含了更多的信息,例如类型信息、结构体字段名等,这些信息对于调试代码非常有用。但是,由于输出的信息可能比较冗长,因此在正式的输出中可能需要使用其他的占位符。
还有一个函数assert_eq:断言两个表达式彼此相等。如果比较结果不相等,assert_eq! 宏会触发一个 panic,导致程序终止。
assert_eq! 宏是 Rust 中的一个非常常用的工具,可以帮助开发者快速定位代码中的错误,并提高代码的可靠性。
macro_rules! assert_eq {
($left : expr, $right : expr $(,) ?) => { ... };
($left : expr, $right : expr, $($arg : tt) +) => { ... };
}
例子:
let a = 3;
let b = 1 + 2;
assert_eq!(a, b);
assert_eq!(a, b, "we are testing addition with {} and {}", a, b);
有了上面的知识就可以学习这段示例了,非常类似JavaScript的语法:
fn main() {
let (a, mut b): (bool, bool) = (true, false);
println!("a = {:?}, b = {:?}", a, b);
b = true;
assert_eq!(a, b);
}
解构式赋值
在 Rust 1.59 版本后,我们可以在赋值语句的左式中使用元组、切片和结构体模式了。
- 这里的
..表示一个范围,即匹配数组中的第一个元素 c,和最后一个元素之前的所有元素 d - 将
Struct { e: 5 }解构为变量 e。这里使用了结构体解构语法,{ e, .. }表示只解构结构体中的字段 e,而其他字段都不关心。
fn main() {
let (a, b, c, d);
(a, b) = (1, 2);
// println!("a {:?}, b {:?}, c {:?}, d {:?}, e {:?}", a, b, c, d, e);
println!("a {:?}, b {:?}", a, b);
[c, .., d, _] = [1, 2, 3, 4, 5];
println!("a {:?}, b {:?}, c {:?}, d {:?}", a, b, c, d);
// 最后输入:a 1, b 2
// a 1, b 2, c 1, d 4
}
变量遮蔽
Rust 允许声明相同的变量名,在后面声明的变量会遮蔽掉前面声明的
这和 mut 变量的使用是不同的,第二个 let 生成了完全不同的新变量,两个变量只是恰好拥有同样的名称,涉及一次内存对象的再分配 ,而 mut 声明的变量,可以修改同一个内存地址上的值,并不会发生内存对象的再分配,性能要更好。变量遮蔽的用处在于,如果你在某个作用域内无需再使用之前的变量(在被遮蔽后,无法再访问到之前的同名变量),就可以重复的使用变量名字,而不用绞尽脑汁去想更多的名字。
这个就有点像Python了,在深度学习或者其他领域,变量又多又懒得起名字,直接就使用上一个覆盖:
fn main() {
let spaces = " ";
// usize数值类型
let spaces = spaces.len();
println!("{}", spaces);
// 3
}
但是如果不使用变量遮蔽,下面的情况就是错误的:
// error[E0308]: mismatched types
let mut spaces = " ";
spaces = spaces.len();
1.3 🚗 所有权 & 🚌 借用
这部分我也是第一次接触,和之前学过的Java虚拟机完全不一样,所以这章核心的内容要是我再添油加醋那么可能会带偏。本章内容十分重要,借用作者的一句话是由于所有权是一个新概念,因此读者需要花费一些时间来掌握它,一旦掌握,海阔天空任你飞跃。所以我搬运而来这块的内容,方便后面直接看。
本章的所有内容都来自:Rust语言圣经(Rust Course)。这章作者写的鬼斧神工,出神入化,我只能这样说了。
1.3.1🚗 所有权
所有的程序都必须和计算机内存打交道,如何从内存中申请空间来存放程序的运行内容,如何在不需要的时候释放这些空间,成了重中之重,也是所有编程语言设计的难点之一。在计算机语言不断演变过程中,出现了三种流派:
垃圾回收机制(GC),在程序运行时不断寻找不再使用的内存,典型代表:Java、Go 手动管理内存的分配和释放, 在程序中,通过函数调用的方式来申请和释放内存,典型代表:C++ 通过所有权来管理内存,编译器在编译时会根据一系列规则进行检查 其中 Rust 选择了第三种,最妙的是,这种检查只发生在编译期,因此对于程序运行期,不会有任何性能上的损失。
一段不安全的代码
先来看看一段来自 C 语言的糟糕代码:
int* foo() {
int a; // 变量a的作用域开始
a = 100;
char *c = "xyz"; // 变量c的作用域开始
return &a;
} // 变量a和c的作用域结束
这段代码虽然可以编译通过,但是其实非常糟糕,变量 a 和 c 都是局部变量,函数结束后将局部变量 a 的地址返回,但局部变量 a 存在栈中,在离开作用域后,a 所申请的栈上内存都会被系统回收,从而造成了 悬空指针(Dangling Pointer) 的问题。这是一个非常典型的内存安全问题,虽然编译可以通过,但是运行的时候会出现错误, 很多编程语言都存在。
再来看变量 c,c 的值是常量字符串,存储于常量区,可能这个函数我们只调用了一次,也可能我们不再会使用这个字符串,但 "xyz" 只有当整个程序结束后系统才能回收这片内存。
所以内存安全问题,一直都是程序员非常头疼的问题,好在, 在 Rust 中这些问题即将成为历史,因为 Rust 在编译的时候就可以帮助我们发现内存不安全的问题,那 Rust 如何做到这一点呢?
预热知识: 栈(Stack)与堆(Heap)
栈和堆是编程语言最核心的数据结构,但是在很多语言中,你并不需要深入了解栈与堆。 但对于 Rust 这样的系统编程语言,值是位于栈上还是堆上非常重要, 因为这会影响程序的行为和性能。
栈和堆的核心目标就是为程序在运行时提供可供使用的内存空间。
栈 栈按照顺序存储值并以相反顺序取出值,这也被称作后进先出。想象一下一叠盘子:当增加更多盘子时,把它们放在盘子堆的顶部,当需要盘子时,再从顶部拿走。不能从中间也不能从底部增加或拿走盘子!
增加数据叫做进栈,移出数据则叫做出栈。
因为上述的实现方式,栈中的所有数据都必须占用已知且固定大小的内存空间,假设数据大小是未知的,那么在取出数据时,你将无法取到你想要的数据。
堆 与栈不同,对于大小未知或者可能变化的数据,我们需要将它存储在堆上。
当向堆上放入数据时,需要请求一定大小的内存空间。操作系统在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的指针, 该过程被称为在堆上分配内存,有时简称为 “分配”(allocating)。
接着,该指针会被推入栈中,因为指针的大小是已知且固定的,在后续使用过程中,你将通过栈中的指针,来获取数据在堆上的实际内存位置,进而访问该数据。
由上可知,堆是一种缺乏组织的数据结构。想象一下去餐馆就座吃饭: 进入餐馆,告知服务员有几个人,然后服务员找到一个够大的空桌子(堆上分配的内存空间)并领你们过去。如果有人来迟了,他们也可以通过桌号(栈上的指针)来找到你们坐在哪。
性能区别 写入方面:入栈比在堆上分配内存要快,因为入栈时操作系统无需分配新的空间,只需要将新数据放入栈顶即可。相比之下,在堆上分配内存则需要更多的工作,这是因为操作系统必须首先找到一块足够存放数据的内存空间,接着做一些记录为下一次分配做准备。
读取方面:得益于 CPU 高速缓存,使得处理器可以减少对内存的访问,高速缓存和内存的访问速度差异在 10 倍以上!栈数据往往可以直接存储在 CPU 高速缓存中,而堆数据只能存储在内存中。访问堆上的数据比访问栈上的数据慢,因为必须先访问栈再通过栈上的指针来访问内存。
因此,处理器处理分配在栈上数据会比在堆上的数据更加高效。
所有权与堆栈 当你的代码调用一个函数时,传递给函数的参数(包括可能指向堆上数据的指针和函数的局部变量)依次被压入栈中,当函数调用结束时,这些值将被从栈中按照相反的顺序依次移除。
因为堆上的数据缺乏组织,因此跟踪这些数据何时分配和释放是非常重要的,否则堆上的数据将产生内存泄漏 —— 这些数据将永远无法被回收。这就是 Rust 所有权系统为我们提供的强大保障。
对于其他很多编程语言,你确实无需理解堆栈的原理,但是在 Rust 中,明白堆栈的原理,对于我们理解所有权的工作原理会有很大的帮助。
所有权原则
理解了堆栈,接下来看一下关于所有权的规则,首先请谨记以下规则:
- Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
- 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
变量作用域
作用域是一个变量在程序中有效的范围, 假如有这样一个变量:
let s = "hello";
变量 s 绑定到了一个字符串字面值,该字符串字面值是硬编码到程序代码中的。s 变量从声明的点开始直到当前作用域的结束都是有效的:
{ // s 在这里无效,它尚未声明
let s = "hello"; // 从此处起,s 是有效的
// 使用 s
} // 此作用域已结束,s不再有效
简而言之,s 从创建伊始就开始有效,然后有效期持续到它离开作用域为止,可以看出,就作用域来说,Rust 语言跟其他编程语言没有区别。
简单介绍 String 类型
这里我大致介绍下大纲:
- 了解字符串的硬编码
- 了解动态字符串,例如用户输入进去的情况应该如何创建?
之前提到过,本章会用 String 作为例子,因此这里会进行一下简单的介绍,具体的 String 学习请参见 String 类型。
我们已经见过字符串字面值 let s ="hello",s 是被硬编码进程序里的字符串值(类型为 &str )。字符串字面值是很方便的,但是它并不适用于所有场景。原因有二:
字符串字面值是不可变的,因为被硬编码到程序代码中 并非所有字符串的值都能在编写代码时得知 例如,字符串是需要程序运行时,通过用户动态输入然后存储在内存中的,这种情况,字符串字面值就完全无用武之地。 为此,Rust 为我们提供动态字符串类型: String, 该类型被分配到堆上,因此可以动态伸缩,也就能存储在编译时大小未知的文本。
可以使用下面的方法基于字符串字面量来创建 String 类型:
let s = String::from("hello");
:: 是一种调用操作符,这里表示调用 String 中的 from 方法,因为 String 存储在堆上是动态的,你可以这样修改它:
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() 在字符串后追加字面值
println!("{}", s); // 将打印 `hello, world!`
言归正传,了解 String 内容后,一起来看看关于所有权的交互。
变量绑定背后的数据交互
转移所有权
先来看一段代码:
let x = 5;
let y = x;
代码背后的逻辑很简单, 将 5 绑定到变量 x;接着拷贝 x 的值赋给 y,最终 x 和 y 都等于 5,因为整数是 Rust 基本数据类型,是固定大小的简单值,因此这两个值都是通过自动拷贝的方式来赋值的,都被存在栈中,完全无需在堆上分配内存。
可能有同学会有疑问:这种拷贝不消耗性能吗?实际上,这种栈上的数据足够简单,而且拷贝非常非常快,只需要复制一个整数大小(i32,4 个字节)的内存即可,因此在这种情况下,拷贝的速度远比在堆上创建内存来得快的多。实际上,上一章我们讲到的 Rust 基本类型都是通过自动拷贝的方式来赋值的,就像上面代码一样。
然后再来看一段代码:
let s1 = String::from("hello");
let s2 = s1;
此时,可能某个大聪明(善意昵称)已经想到了:嗯,把 s1 的内容拷贝一份赋值给 s2,实际上,并不是这样。之前也提到了,对于基本类型(存储在栈上),Rust 会自动拷贝,但是 String 不是基本类型,而且是存储在堆上的,因此不能自动拷贝。
实际上, String 类型是一个复杂类型,由存储在栈中的堆指针、字符串长度、字符串容量共同组成,其中堆指针是最重要的,它指向了真实存储字符串内容的堆内存,至于长度和容量,如果你有 Go 语言的经验,这里就很好理解:容量是堆内存分配空间的大小,长度是目前已经使用的大小。
总之 String 类型指向了一个堆上的空间,这里存储着它的真实数据, 下面对上面代码中的 let s2 = s1 分成两种情况讨论:
- 拷贝 String 和存储在堆上的字节数组 如果该语句是拷贝所有数据(深拷贝),那么无论是 String 本身还是底层的堆上数据,都会被全部拷贝,这对于性能而言会造成非常大的影响
- 只拷贝 String 本身 这样的拷贝非常快,因为在 64 位机器上就拷贝了 8字节的指针、8字节的长度、8字节的容量,总计 24 字节,但是带来了新的问题,还记得我们之前提到的所有权规则吧?其中有一条就是:一个值只允许有一个所有者,而现在这个值(堆上的真实字符串数据)有了两个所有者:s1 和 s2。
好吧,就假定一个值可以拥有两个所有者,会发生什么呢?
当变量离开作用域后,Rust 会自动调用 drop 函数并清理变量的堆内存。不过由于两个 String 变量指向了同一位置。这就有了一个问题:当 s1 和 s2 离开作用域,它们都会尝试释放相同的内存。这是一个叫做 二次释放(double free) 的错误,也是之前提到过的内存安全性 BUG 之一。两次释放(相同)内存会导致内存污染,它可能会导致潜在的安全漏洞。
因此,Rust 这样解决问题:当 s1 赋予 s2 后,Rust 认为 s1 不再有效,因此也无需在 s1 离开作用域后 drop 任何东西,这就是把所有权从 s1 转移给了 s2,s1 在被赋予 s2 后就马上失效了。
再来看看,在所有权转移后再来使用旧的所有者,会发生什么:
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);
由于 Rust 禁止你使用无效的引用,你会看到以下的错误:
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:28
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{}, world!", s1);
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info)
这里我再进一步解释一下:代码会报错,因为在 Rust 中,变量绑定具有所有权 (ownership)。当你将 s1 绑定到新的变量 s2 时,所有权会转移,而 s1 不再有效。这是 Rust 的一个关键特性,它有助于避免内存不安全。错误发生在 println! 行,因为你试图使用已经失效的变量 s1。
🌅另外这段代码可以解决:1. 克隆 2. 引用
- 克隆(clone):
let s1 = String::from("hello");
let s2 = s1.clone();
println!("{}, world!", s1);
// 这会创建一个新的 `String` 实例,其内容与 `s1` 相同,并将其绑定到 `s2`。这样,`s1` 和 `s2` 都可以在后续代码中使用。
- 引用 (references):
let s1 = String::from("hello");
let s2 = &s1;
println!("{}, world!", s1);
// 在这个例子中,我们使用了一个对 `s1` 的引用并将其赋值给 `s2`。这样 `s1` 仍然拥有所有权,而 `s2` 只是借用 (borrow)。注意,当使用引用时,可能需要考虑生命周期 (lifetimes) 和可变性 (mutability)。
现在再回头看看之前的规则,相信大家已经有了更深刻的理解:
- Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
- 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
如果你在其他语言中听说过术语 浅拷贝(shallow copy) 和 深拷贝(deep copy),那么拷贝指针、长度和容量而不拷贝数据听起来就像浅拷贝,但是又因为 Rust 同时使第一个变量 s1 无效了,因此这个操作被称为 移动(move),而不是浅拷贝。上面的例子可以解读为 s1 被移动到了 s2 中。那么具体发生了什么,用一张图简单说明: 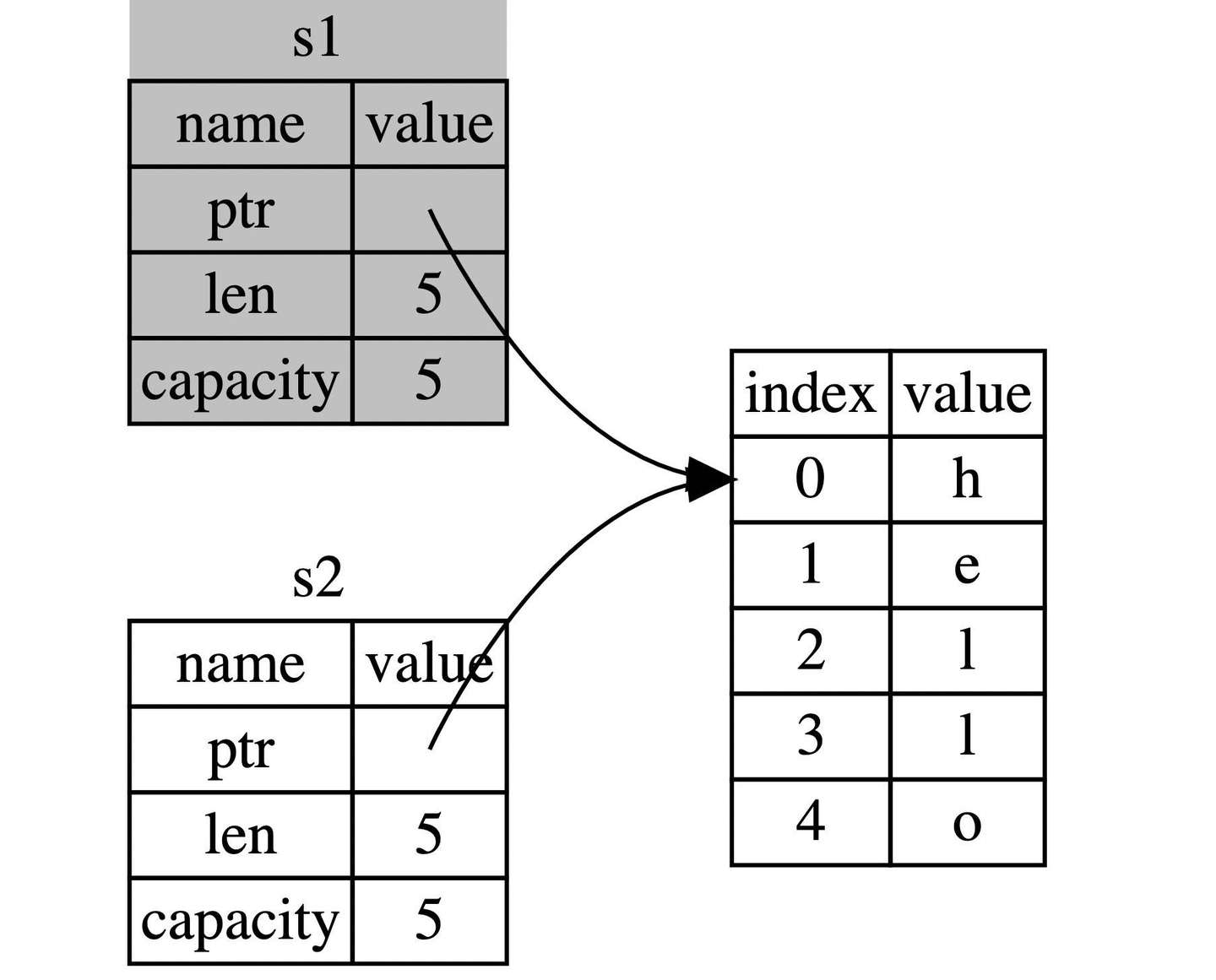 这样就解决了我们之前的问题,s1 不再指向任何数据,只有 s2 是有效的,当 s2 离开作用域,它就会释放内存。 相信此刻,你应该明白了,为什么 Rust 称呼 let a = b 为变量绑定了吧?
这样就解决了我们之前的问题,s1 不再指向任何数据,只有 s2 是有效的,当 s2 离开作用域,它就会释放内存。 相信此刻,你应该明白了,为什么 Rust 称呼 let a = b 为变量绑定了吧?
再来看一段代码:
fn main() {
let x: &str = "hello, world";
let y = x;
println!("{},{}",x,y);
}
这段代码,大家觉得会否报错?如果参考之前的 String 所有权转移的例子,那这段代码也应该报错才是,但是实际上呢?
这段代码和之前的 String 有一个本质上的区别:在 String 的例子中 s1 持有了通过String::from("hello") 创建的值的所有权,而这个例子中,x 只是引用了存储在二进制中的字符串 "hello, world",并没有持有所有权。
因此 let y = x 中,仅仅是对该引用进行了拷贝,此时 y 和 x 都引用了同一个字符串。如果还不理解也没关系,当学习了下一章节 "引用与借用" 后,大家自然而言就会理解。
克隆(深拷贝)
首先,Rust 永远也不会自动创建数据的 “深拷贝”。因此,任何自动的复制都不是深拷贝,可以被认为对运行时性能影响较小。
如果我们确实需要深度复制 String 中堆上的数据,而不仅仅是栈上的数据,可以使用一个叫做 clone 的方法。
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);
这段代码能够正常运行,因此说明 s2 确实完整的复制了 s1 的数据。
如果代码性能无关紧要,例如初始化程序时,或者在某段时间只会执行一次时,你可以使用 clone 来简化编程。但是对于执行较为频繁的代码(热点路径),使用 clone 会极大的降低程序性能,需要小心使用!
拷贝(浅拷贝)
浅拷贝只发生在栈上,因此性能很高,在日常编程中,浅拷贝无处不在。
再回到之前看过的例子:
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);
但这段代码似乎与我们刚刚学到的内容相矛盾:没有调用 clone,不过依然实现了类似深拷贝的效果 —— 没有报所有权的错误。
原因是像整型这样的基本类型在编译时是已知大小的,会被存储在栈上,所以拷贝其实际的值是快速的。这意味着没有理由在创建变量 y 后使 x 无效(x、y 都仍然有效)。换句话说,这里没有深浅拷贝的区别,因此这里调用 clone 并不会与通常的浅拷贝有什么不同,我们可以不用管它(可以理解成在栈上做了深拷贝)。
Rust 有一个叫做 Copy 的特征,可以用在类似整型这样在栈中存储的类型。如果一个类型拥有 Copy 特征,一个旧的变量在被赋值给其他变量后仍然可用。
那么什么类型是可 Copy 的呢?可以查看给定类型的文档来确认,不过作为一个通用的规则: 任何基本类型的组合可以 Copy ,不需要分配内存或某种形式资源的类型是可以 Copy 的。如下是一些 Copy 的类型:
- 所有整数类型,比如 u32
- 布尔类型,bool,它的值是 true 和 false
- 所有浮点数类型,比如 f64
- 字符类型,char
- 元组,当且仅当其包含的类型也都是 Copy 的时候。比如,(i32, i32) 是 Copy 的,但 (i32, String) 就不是
- 不可变引用 &T ,例如转移所有权中的最后一个例子,但是注意: 可变引用 &mut T 是不可以 Copy的
函数传值与返回
将值传递给函数,一样会发生 移动 或者 复制,就跟 let 语句一样,下面的代码展示了所有权、作用域的规则:
fn main() {
let s = String::from("hello"); // s 进入作用域
takes_ownership(s); // s 的值移动到函数里 ...
// ... 所以到这里不再有效
let x = 5; // x 进入作用域
makes_copy(x); // x 应该移动函数里,
// 但 i32 是 Copy 的,所以在后面可继续使用 x
} // 这里, x 先移出了作用域,然后是 s。但因为 s 的值已被移走,
// 所以不会有特殊操作
fn takes_ownership(some_string: String) { // some_string 进入作用域
println!("{}", some_string);
} // 这里,some_string 移出作用域并调用 `drop` 方法。占用的内存被释放
fn makes_copy(some_integer: i32) { // some_integer 进入作用域
println!("{}", some_integer);
} // 这里,some_integer 移出作用域。不会有特殊操作
你可以尝试在 takes_ownership 之后,再使用 s,看看如何报错?例如添加一行 println!("在move进函数后继续使用s: {}",s);。
fn main() {
let s = String::from("hello"); // s 进入作用域
takes_ownership(s); // s 的值移动到函数里 ...
// ... 所以到这里不再有效
let y = s;
println!(y); // 这里进行实验
// ====================================
%%error: format argument must be a string literal
--> src/main.rs:7:14
|
7 | println!(y);
| ^
|
help: you might be missing a string literal to format with
|
7 | println!("{}", y);
| +++++
error: could not compile `Demo` due to previous erro%%r
同样的,函数返回值也有所有权,例如:
fn main() {
let s1 = gives_ownership(); // gives_ownership 将返回值
// 移给 s1
let s2 = String::from("hello"); // s2 进入作用域
let s3 = takes_and_gives_back(s2); // s2 被移动到
// takes_and_gives_back 中,
// 它也将返回值移给 s3
} // 这里, s3 移出作用域并被丢弃。s2 也移出作用域,但已被移走,
// 所以什么也不会发生。s1 移出作用域并被丢弃
fn gives_ownership() -> String { // gives_ownership 将返回值移动给
// 调用它的函数
let some_string = String::from("hello"); // some_string 进入作用域.
some_string // 返回 some_string 并移出给调用的函数
}
// takes_and_gives_back 将传入字符串并返回该值
fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域
a_string // 返回 a_string 并移出给调用的函数
}
所有权很强大,避免了内存的不安全性,但是也带来了一个新麻烦: 总是把一个值传来传去来使用它。 传入一个函数,很可能还要从该函数传出去,结果就是语言表达变得非常啰嗦,幸运的是,Rust 提供了新功能解决这个问题。
1.3.2 🚌 借用
上节中提到,如果仅仅支持通过转移所有权的方式获取一个值,那会让程序变得复杂。 Rust 能否像其它编程语言一样,使用某个变量的指针或者引用呢?答案是可以。
Rust 通过 借用(Borrowing) 这个概念来达成上述的目的,获取变量的引用,称之为借用(borrowing)。正如现实生活中,如果一个人拥有某样东西,你可以从他那里借来,当使用完毕后,也必须要物归原主。
引用与解引用
常规引用是一个指针类型,指向了对象存储的内存地址。在下面代码中,我们创建一个 i32 值的引用 y,然后使用解引用运算符来解出 y 所使用的值:
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}
变量 x 存放了一个 i32 值 5。y 是 x 的一个引用。可以断言 x 等于 5。然而,如果希望对 y 的值做出断言,必须使用 *y 来解出引用所指向的值(也就是解引用)。一旦解引用了 y,就可以访问 y 所指向的整型值并可以与 5 做比较。
相反如果尝试编写 assert_eq!(5, y);,则会得到如下编译错误:
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}` // 无法比较整数类型和引用类型
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= help: the following other types implement trait `PartialEq<Rhs>`:
不可变引用
下面的代码,我们用 s1 的引用作为参数传递给 calculate_length 函数,而不是把 s1 的所有权转移给该函数:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
能注意到两点:
- 无需像上章一样:先通过函数参数传入所有权,然后再通过函数返回来传出所有权,代码更加简洁
- calculate_length 的参数 s 类型从 String 变为 &String 这里,& 符号即是引用,它们允许你使用值,但是不获取所有权,如图所示:
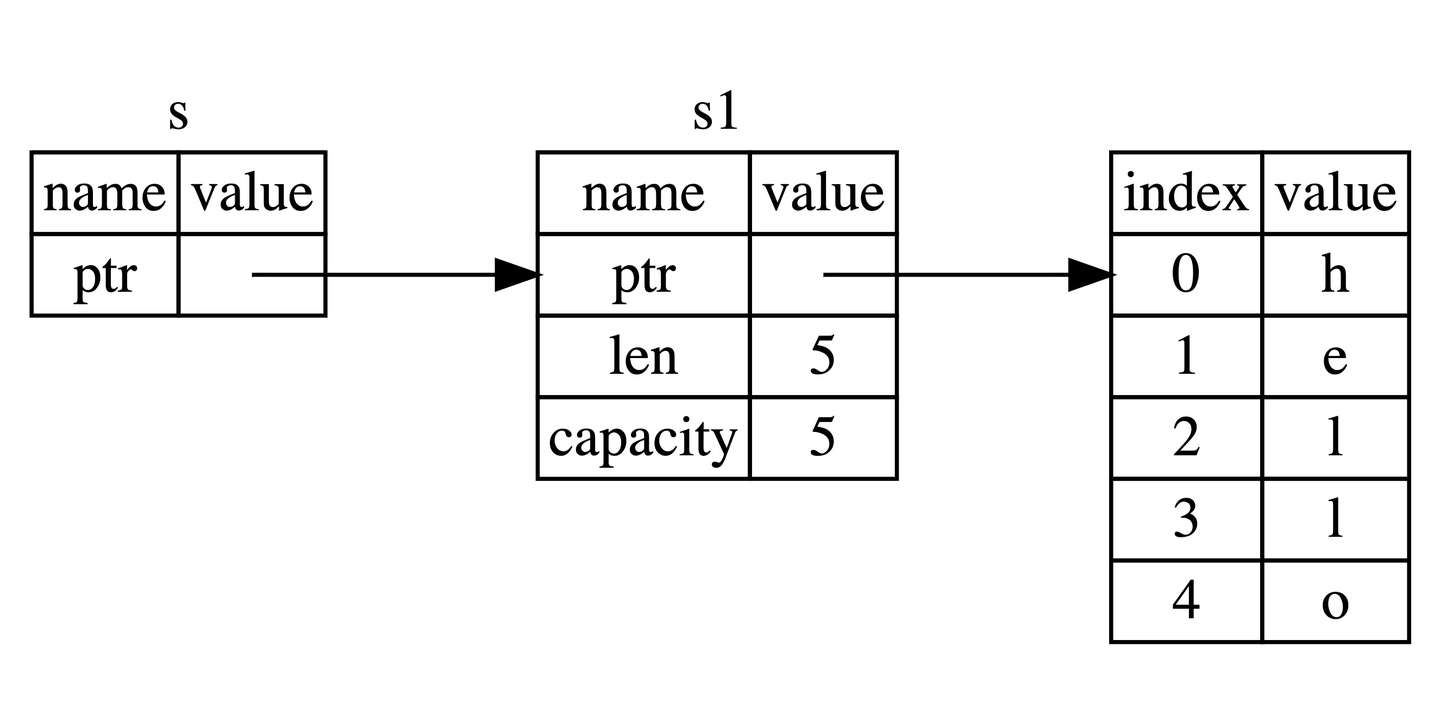 通过 &s1 语法,我们创建了一个指向 s1 的引用,但是并不拥有它。因为并不拥有这个值,当引用离开作用域后,其指向的值也不会被丢弃。
通过 &s1 语法,我们创建了一个指向 s1 的引用,但是并不拥有它。因为并不拥有这个值,当引用离开作用域后,其指向的值也不会被丢弃。
同理,函数 calculate_length 使用 & 来表明参数 s 的类型是一个引用:
fn calculate_length(s: &String) -> usize { // s 是对 String 的引用
s.len()
} // 这里,s 离开了作用域。但因为它并不拥有引用值的所有权,
// 所以什么也不会发生
很不幸,妹子你没抱到,哦口误,你修改错了:
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
7 | fn change(some_string: &String) {
| ------- help: consider changing this to be a mutable reference: `&mut String`
------- 帮助:考虑将该参数类型修改为可变的引用: `&mut String`
8 | some_string.push_str(", world");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable\
`some_string`是一个`&`类型的引用,因此它指向的数据无法进行修改
For more information about this error, try `rustc --explain E0596`.
error: could not compile `Demo` due to previous error
正如变量默认不可变一样,引用指向的值默认也是不可变的,没事,来一起看看如何解决这个问题。
可变引用
只需要一个小调整,即可修复上面代码的错误:
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
首先,声明 s 是可变类型,其次创建一个可变的引用 &mut s 和接受可变引用参数 some_string: &mut String 的函数。
可变引用同时只能存在一个
不过可变引用并不是随心所欲、想用就用的,它有一个很大的限制: 同一作用域,特定数据只能有一个可变引用:
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
以上代码会报错:
error[E0499]: cannot borrow `s` as mutable more than once at a time 同一时间无法对 `s` 进行两次可变借用
--> src/main.rs:5:10
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here 首个可变引用在这里借用
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here 第二个可变引用在这里借用
6 |
7 | println!("{}, {}", r1, r2);
| -- first borrow later used here 第一个借用在这里使用
For more information about this error, try `rustc --explain E0499`.
error: could not compile `Demo` due to previous error
这段代码出错的原因在于,第一个可变借用 r1 必须要持续到最后一次使用的位置 println!,在 r1 创建和最后一次使用之间,我们又尝试创建第二个可变借用 r2。
对于新手来说,这个特性绝对是一大拦路虎,也是新人们谈之色变的编译器 borrow checker 特性之一,不过各行各业都一样,限制往往是出于安全的考虑,Rust 也一样。
这种限制的好处就是使 Rust 在编译期就避免数据竞争,数据竞争可由以下行为造成:
- 两个或更多的指针同时访问同一数据
- 至少有一个指针被用来写入数据
- 没有同步数据访问的机制
数据竞争会导致未定义行为,这种行为很可能超出我们的预期,难以在运行时追踪,并且难以诊断和修复。而 Rust 避免了这种情况的发生,因为它甚至不会编译存在数据竞争的代码!
很多时候,大括号可以帮我们解决一些编译不通过的问题,通过手动限制变量的作用域:
let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1 在这里离开了作用域,所以我们完全可以创建一个新的引用
let r2 = &mut s;
可变引用与不可变引用不能同时存在
下面的代码会导致一个错误:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // 没问题
let r2 = &s; // 没问题
let r3 = &mut s; // 大问题
println!("{}, {}, and {}", r1, r2, r3);
}
错误如下:
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // 没问题
| -- immutable borrow occurs here
5 | let r2 = &s; // 没问题
6 | let r3 = &mut s; // 大问题
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{}, {}, and {}", r1, r2, r3);
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `Demo` due to previous error
其实这个也很好理解,正在借用不可变引用的用户,肯定不希望他借用的东西,被另外一个人莫名其妙改变了。多个不可变借用被允许是因为没有人会去试图修改数据,每个人都只读这一份数据而不做修改,因此不用担心数据被污染。
注意,引用的作用域 s 从创建开始,一直持续到它最后一次使用的地方,这个跟变量的作用域有所不同,变量的作用域从创建持续到某一个花括号 }
Rust 的编译器一直在优化,早期的时候,引用的作用域跟变量作用域是一致的,这对日常使用带来了很大的困扰,你必须非常小心的去安排可变、不可变变量的借用,免得无法通过编译,例如以下代码:
fn main() {
let mut s = String::from("hello");
let r1 = &s;
let r2 = &s;
println!("{} and {}", r1, r2);
// 新编译器中,r1,r2作用域在这里结束
let r3 = &mut s;
println!("{}", r3);
} // 老编译器中,r1、r2、r3作用域在这里结束
// 新编译器中,r3作用域在这里结束
在老版本的编译器中(Rust 1.31 前),将会报错,因为 r1 和 r2 的作用域在花括号 } 处结束,那么 r3 的借用就会触发 无法同时借用可变和不可变的规则。
但是在新的编译器中,该代码将顺利通过,因为 引用作用域的结束位置从花括号变成最后一次使用的位置,因此 r1 借用和 r2 借用在 println! 后,就结束了,此时 r3 可以顺利借用到可变引用。
NLL
对于这种编译器优化行为,Rust 专门起了一个名字 —— Non-Lexical Lifetimes(NLL),专门用于找到某个引用在作用域(})结束前就不再被使用的代码位置。
虽然这种借用错误有的时候会让我们很郁闷,但是你只要想想这是 Rust 提前帮你发现了潜在的 BUG,其实就开心了,虽然减慢了开发速度,但是从长期来看,大幅减少了后续开发和运维成本。
悬垂引用(Dangling References)
悬垂引用也叫做悬垂指针,意思为指针指向某个值后,这个值被释放掉了,而指针仍然存在,其指向的内存可能不存在任何值或已被其它变量重新使用。在 Rust 中编译器可以确保引用永远也不会变成悬垂状态:当你获取数据的引用后,编译器可以确保数据不会在引用结束前被释放,要想释放数据,必须先停止其引用的使用。
让我们尝试创建一个悬垂引用,Rust 会抛出一个编译时错误:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}
这里是错误:
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime
|
5 | fn dangle() -> &'static String {
| ~~~~~~~~
错误信息引用了一个我们还未介绍的功能:生命周期(lifetimes)。不过,即使你不理解生命周期,也可以通过错误信息知道这段代码错误的关键信息:
this function's return type contains a borrowed value, but there is no value for it to be borrowed from. 该函数返回了一个借用的值,但是已经找不到它所借用值的来源
仔细看看 dangle 代码的每一步到底发生了什么:
fn dangle() -> &String { // dangle 返回一个字符串的引用
let s = String::from("hello"); // s 是一个新字符串
&s // 返回字符串 s 的引用
} // 这里 s 离开作用域并被丢弃。其内存被释放。
// 危险!
因为 s 是在 dangle 函数内创建的,当 dangle 的代码执行完毕后,s 将被释放,但是此时我们又尝试去返回它的引用。这意味着这个引用会指向一个无效的 String,这可不对!
其中一个很好的解决方法是直接返回 String:
fn no_dangle() -> String {
let s = String::from("hello");
s
}
这样就没有任何错误了,最终 String 的 所有权被转移给外面的调用者。
借用规则总结
总的来说,借用规则如下:
- 同一时刻,你只能拥有要么一个可变引用, 要么任意多个不可变引用
- 引用必须总是有效的
至此,我终于搬完了,累死了!
1.4 🗛 字符串
先试试这段代码的结果是怎样的?
fn main() {
let my_name = "Pascal";
greet(my_name);
}
fn greet(name: String) {
println!("Hello, {}!", name);
}
这段代码会报错,因为在调用 greet 函数时,my_name 只是一个字符串切片(&str),而不是一个 String 类型。在 Rust 中,&str 和 String 是两种不同的字符串类型,String 是可变的,而 &str 是不可变的。
为了解决这个问题,您可以将 greet 函数的参数类型更改为 &str,如下所示:
error[E0308]: mismatched types
--> src/main.rs:3:9
|
3 | greet(my_name);
| ^^^^^^^- help: try using a conversion method: `.to_string()` // 尝试使用转换方法:'.to_string()'
| |
| expected struct `String`, found `&str` // 当前结构'String',预期找到'&str'
For more information about this error, try `rustc --explain E0308`.
error: could not compile `Demo` due to previous error
解决方案:
fn main() {
let my_name = "Pascal";
greet(my_name);
}
fn greet(name: &str) {
println!("Hello, {}!", name);
}
切片(slice)
下面先写一个Go语言和Python语言的切片,方便渐入佳境
Go语言
package main
import "fmt"
func main() {
// 创建切片
numbers := []int{1, 2, 3, 4, 5}
// 输出切片
fmt.Println("切片 numbers:", numbers)
// 切片从索引 1 到索引 4
fmt.Println("numbers[1:4]:", numbers[1:4])
// 默认下限为0
fmt.Println("numbers[:3]:", numbers[:3])
// 默认上限为 len(s)
fmt.Println("numbers[2:]:", numbers[2:])
// 创建一个切片,len=0,cap=2
slice1 := make([]int, 0, 2)
fmt.Println("slice1:", slice1)
// 追加元素
slice1 = append(slice1, 1)
fmt.Println("slice1:", slice1)
// 追加多个元素
slice1 = append(slice1, 2, 3, 4)
fmt.Println("slice1:", slice1)
}
Python:
# 创建列表
numbers = [1, 2, 3, 4, 5]
# 输出列表
print("列表 numbers:", numbers)
# 切片从索引 1 到索引 4
print("numbers[1:4]:", numbers[1:4])
# 默认下限为0
print("numbers[:3]:", numbers[:3])
# 默认上限为 len(s)
print("numbers[2:]:", numbers[2:])
# 创建一个列表
list1 = []
# 追加元素
list1.append(1)
print("list1:", list1)
# 追加多个元素
list1.extend([2, 3, 4])
print("list1:", list1)
rust: 
fn main() {
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
println!("{}, {}", hello, world);
// hello, world
}
当然,你可以横切竖切,想怎么切怎么切:
- 从0开始切
fn main() {
let s = String::from("hello world");
let tmp = &s[..2];
println!("{:?}", tmp); // he
}
- 从某个位置切到尾巴
fn main() {
let s = String::from("hello world");
let tmp = &s[2..s.len()];
println!("{:?}", tmp); // llo world
}
- 完整切
fn main() {
let s = String::from("hello world");
let tmp = &s[..];
println!("{:?}", tmp); // hello world
}
⚠️ warning:在对字符串使用切片语法时需要格外小心,切片的索引必须落在字符之间的边界位置,也就是 UTF-8 字符的边界,例如中文在 UTF-8 中占用三个字节,下面的代码就会崩溃:
fn main() {
let s = "中国人";
let a = &s[0..2];
println!("{}",a);
}
thread 'main' panicked at 'byte index 2 is not a char boundary; it is inside '中' (bytes 0..3) of `中国人`', library/core/src/str/mod.rs:127:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
主线程在字节索引2处,这不是一个char边界;它在'中国人", Library/core/src/str/mod.rs:127:5的'中'(字节0…3)中
注意:使用'RUST_BACKTRACE=1'环境变量运行以显示回溯
因为我们只取 s 字符串的前两个字节,但是本例中每个汉字占用三个字节,因此没有落在边界处,也就是连 中 字都取不完整,此时程序会直接崩溃退出,如果改成 &s[0..3],则可以正常通过编译。
fn main() {
let s = "中国人";
let a = &s[0..3];
println!("{}",a);
}
字符串切片的类型标识是 &str 在这里其实有点混乱,String和&str有什么区别呢?
- String是一个拥有所有权的可变字符串类型。这意味着它可以动态地增加或缩小字符串的长度,因为它在堆上分配内存,并且可以自动地调整大小以适应更改。
- &str是一个不可变的字符串切片类型,它是一个指向字符串数据的引用。这意味着它不能动态地改变字符串的长度,因为它只是字符串数据的引用,而不是实际的字符串。因此,&str通常用于不需要修改字符串的情况,例如函数参数,或者在字符串数据不需要拥有所有权时使用。
fn main() {
// 创建一个String类型的字符串
let mut s = String::from("hello");
// 在字符串末尾添加一个字符
s.push(' ');
// 添加一个&str类型的字符串
s.push_str("world");
// 使用&操作符将String类型的字符串转换为&str类型的字符串切片
let slice = &s[..];
println!("{}", slice);
}
在上面的示例中,我们使用String类型的s变量创建一个可变字符串,并在其末尾添加字符和字符串。然后,我们使用&操作符将String类型的字符串转换为&str类型的字符串切片,并将其赋值给slice变量。最后,我们打印slice变量,它包含完整的"hello world"字符串。
有了这个理解就可以来看比较妙的代码了:
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {}", word);
}
fn first_word(s: &String) -> &str {
&s[..1]
}
我的理解是:
let mut s = String::from("hello world");这里是String,拥有所有权的可变字符串类型let word = first_word(&s);返回一个&str,不可变的字符串切片类型s.clear()需要一个可变借用,但是现在已经(word)是&str,不可变的字符串切片类型println!("the first word is: {}", word);需要一个不可变借用,在 s.clear() 处可变借用与不可变借用试图同时生效,因此编译无法通过。
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let word = first_word(&s);
| -- immutable borrow occurs here // 不可变的借用发生在这里
5 |
6 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here // 可变借用发生在这里
7 |
8 | println!("the first word is: {}", word);
| ---- immutable borrow later used here // 不可变借后来用在这里
For more information about this error, try `rustc --explain E0502`.
error: could not compile `Demo` due to previous error
注:在Rust中,可以使用&操作符将String类型的字符串转换为&str类型的字符串切片。这种转换并不涉及内存分配或复制,因为&str只是一个指向String类型字符串的不可变引用。但需要注意的是,&str引用的字符串必须在String变量的生命周期内,否则会导致悬垂引用错误。
字符串字面量是切片
之前提到过字符串字面量,但是没有提到它的类型:
let s = "Hello, world!";
实际上,s 的类型是 &str,因此你也可以这样声明:
let s: &str = "Hello, world!";
该切片指向了程序可执行文件中的某个点,这也是为什么字符串字面量是不可变的,因为 &str 是一个不可变引用。
字符串类型
- str 类型是硬编码进可执行文件,也无法被修改
- String 则是一个可增长、可改变且具有所有权的 UTF-8 编码字符串,当 Rust 用户提到字符串时,往往指的就是 String 类型和 &str 字符串切片类型,这两个类型都是 UTF-8 编码。
- &str 字符串切片
String 与 &str 的转换
&str 类型生成 String 类型的操作:
String::from("hello,world")
"hello,world".to_string()
String 类型转为 &str 类型 -- 引用:
fn main() {
let s = String::from("hello,world!"); // String
say_hello(&s); // 这里开始转换成&str
say_hello(&s[..]);
say_hello(s.as_str());
}
fn say_hello(s: &str) {
println!("{}",s);
}
字符串索引
在Rust中下面的代码如果使用a[0]则无法访问,这是为什么呢?作为一名Java程序员,感觉很蛋疼
fn main() {
let a = "123";
println!("{}", a[0]); // error
println!("{}", &a[..2]); // running!
}
报错内容如下:
error[E0277]: the type `str` cannot be indexed by `{integer}`
--> src/main.rs:3:20
|
3 | println!("{}", a[0]); // error
| ^^^^ string indices are ranges of `usize`
|
= help: the trait `SliceIndex<str>` is not implemented for `{integer}`
= note: you can use `.chars().nth()` or `.bytes().nth()`
for more information, see chapter 8 in The Book: <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
= help: the trait `SliceIndex<[T]>` is implemented for `usize`
= note: required because of the requirements on the impl of `Index<{integer}>` for `str`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `Demo` due to previous error
原因分析
- Rust 字符串底层数据存储格式是
Vec<u8>,一个字节数组。对于多字节字符,比如汉字,一个字符可能会占用多个字节,因此字符串长度与字节数并不一定相等。
let s = String::from("中国人");
let bytes = s.as_bytes();
println!("{:?}", bytes); // 输出 [228, 184, 173, 229, 155, 189, 228, 184, 128]
- Rust 提供了不同的字符串展现方式,包括字节串、Unicode 字符串和语言字符串。字节串是底层字节数组的直接展现,Unicode 字符串可以使用 chars() 方法获取,语言字符串可以使用 graphemes() 方法获取。
let s = String::from("नमस्ते");
let bytes = s.as_bytes(); // 字节串
let chars = s.chars(); // Unicode 字符串
let graphemes = s.graphemes(true); // 语言字符串
println!("{:?}", bytes); // 输出 [224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164, 224, 165, 135]
println!("{:?}", chars.collect::<Vec<char>>()); // 输出 ['न', 'म', 'स', '्', 'त', 'े']
println!("{:?}", graphemes.collect::<Vec<&str>>()); // 输出 ["न", "म", "स्", "ते"]
- Rust 不允许直接索引字符串,即不能使用类似
str[index]的方式获取字符串中的某个字符。这是因为字符串的字符可能占用多个字节,因此无法保证 O(1) 的性能表现。如果确实需要访问字符串中的某个字符,可以使用迭代器或者字符切片等方式来遍历字符串。
let s = String::from("Hello, world!");
let third = s.chars().nth(2); // 第三个字符,返回 Option<char>
let slice = &s[0..5]; // 字符切片,包含 s[0] 到 s[4]
println!("{:?}", third); // 输出 Some('l')
println!("{:?}", slice); // 输出 "Hello"
字符串的一些常用API
追加(push)
首先介绍push和push_str
pub fn push_str(&mut self, string: &str) 将给定的字符串切片追加到这个 String 的末尾。
let mut s = String::from("foo");
s.push_str("bar");
assert_eq!("foobar", s);
pub fn push(&mut self, ch: char) 将给定的 char 追加到该 String 的末尾。
let mut s = String::from("abc");
s.push('1');
s.push('2');
s.push('3');
assert_eq!("abc123", s);
注:目前只要知道区别是:push() 方法只能添加单个字符,如果想要添加一个字符串,需要将字符串转换为字符切片再使用 push_str() 方法。
插入(Insert)
pub fn insert(&mut self, idx: usize, ch: char) 在此 String 的字节位置插入一个字符。这是一个 O(n) 操作,因为它需要复制缓冲区中的每个元素。
let mut s = String::with_capacity(3);
s.insert(0, 'f');
s.insert(1, 'o');
s.insert(2, 'o');
assert_eq!("foo", s);
pub fn insert_str(&mut self, idx: usize, string: &str) 在此 String 的字节位置处插入字符串切片。这是一个 O(n) 操作,因为它需要复制缓冲区中的每个元素。
let mut s = String::from("bar");
s.insert_str(0, "foo");
assert_eq!("foobar", s);
替换(Replace)
pub fn replace<'a, P>(&'a self, from: P, to: &str) -> String 用另一个字符串替换模式的所有匹配项。 replace 创建一个新的 String,并将此字符串切片中的数据复制到其中。 这样做时,它将尝试查找某个模式的匹配项。 如果找到,则将其替换为替换字符串切片。
let s = "this is old";
assert_eq!("this is new", s.replace("old", "new"));
当模式不匹配时:
let s = "this is old";
assert_eq!(s, s.replace("cookie monster", "little lamb"));
pub fn replacen<'a, P>(&'a self, pat: P, to: &str, count: usize) -> String 用另一个字符串替换模式的前 N 个匹配项。 replacen 创建一个新的 String,并将此字符串切片中的数据复制到其中。 这样做时,它将尝试查找某个模式的匹配项。 如果找到任何内容,则最多 count 次将它们替换为替换字符串切片。
let s = "foo foo 123 foo";
assert_eq!("new new 123 foo", s.replacen("foo", "new", 2));
assert_eq!("faa fao 123 foo", s.replacen('o', "a", 3));
assert_eq!("foo foo new23 foo", s.replacen(char::is_numeric, "new", 1));
不匹配时:
let s = "this is old";
assert_eq!(s, s.replacen("cookie monster", "little lamb", 10));
pub fn replace_range
<R>(&mut self, range: R, replace_with: &str) 删除字符串中的指定范围,并将其替换为给定的字符串。 给定的字符串不必与范围相同。
let mut s = String::from("α is alpha, β is beta");
let beta_offset = s.find('β').unwrap_or(s.len());
// 替换范围直到字符串中的 β
s.replace_range(..beta_offset, "Α is capital alpha; ");
assert_eq!(s, "Α is capital alpha; β is beta");
删除
pub fn pop(&mut self) -> Option
<char>从字符串缓冲区中删除最后一个字符并返回它。 如果 String 为空,则返回 None。
let mut s = String::from("foo");
assert_eq!(s.pop(), Some('o'));
assert_eq!(s.pop(), Some('o'));
assert_eq!(s.pop(), Some('f'));
assert_eq!(s.pop(), None);
pub fn remove(&mut self, idx: usize) -> char 从该 String 的字节位置删除 char 并将其返回。 这是 O(n) 操作,因为它需要复制缓冲区中的每个元素。
let mut s = String::from("foo");
assert_eq!(s.remove(0), 'f');
assert_eq!(s.remove(1), 'o');
assert_eq!(s.remove(0), 'o');
pub fn truncate(&mut self, new_len: usize) 将此 String 缩短为指定的长度。 如果 new_len 大于字符串的当前长度,则无效。 请注意,此方法对字符串的分配容量没有影响
let mut s = String::from("hello");
s.truncate(2);
assert_eq!("he", s);
pub fn clear(&mut self) 截断此 String,删除所有内容。 虽然这意味着 String 的长度为零,但它并未触及其容量。
let mut s = String::from("foo");
s.clear();
assert!(s.is_empty());
assert_eq!(0, s.len());
assert_eq!(3, s.capacity());
连接 (Concatenate)
- 使用 + 或者 += 连接字符串 理论上来说,对于Java程序员,直接上就完事。But
fn main() {
let string_append = String::from("hello ");
let string_rust = String::from("rust");
println!("{}", string_append + string_rust)
}
报错如下:
error[E0308]: mismatched types
--> src/main.rs:4:36
|
4 | println!("{}", string_append + string_rust)
| ^^^^^^^^^^^
| |
| expected `&str`, found struct `String`
| help: consider borrowing here: `&string_rust`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `Demo` due to previous error
查看别人写代码是这样:
let result = string_append + &string_rust;
然后就有这样的疑惑:为什么我进行字符串连接的时候,第一个String类型的不用引用,第二个以及后面的要引用? 原因是,在 Rust 中,+ 运算符用于字符串连接,但是它的实现方式与我们熟悉的加法运算符不同。具体来说,+ 运算符会调用 add 方法,该方法的定义如下:
fn add(self, s: &str) -> String
可以看到,add 方法接收一个 self 参数和一个字符串切片 s 参数。由于 self 参数的类型是 String,而 s 参数的类型是 &str,因此在使用 + 运算符进行字符串连接时,第一个字符串可以是 String 类型,而第二个及之后的字符串必须是字符串切片类型。
所以最终代码是
fn main() {
let string_append = String::from("hello ");
let string_rust = String::from("rust");
let string_world = String::from("world");
println!("{}", string_append + &string_rust + &string_world);
}
总结:String + &str返回一个 String,然后再继续跟一个 &str 进行 + 操作,返回一个 String 类型,不断循环,最终生成一个 s,也是 String 类型。
s1 这个变量通过调用 add() 方法后,所有权被转移到 add() 方法里面, add() 方法调用后就被释放了,同时 s1 也被释放了。再使用 s1 就会发生错误。这里涉及到所有权转移(Move)的相关知识。
- 使用 format! 连接字符串
fn main() {
let s1 = "hello";
let s2 = String::from("rust");
let s = format!("{} {}!", s1, s2);
println!("{}", s);
}
操作 UTF-8 字符串
如果你想要以 Unicode 字符的方式遍历字符串,最好的办法是使用 chars 方法,例如:
for c in "中国人".chars() {
println!("{}", c);
}
如果要返回字符串的底层字节数组表现形式:
for b in "中国人".bytes() {
println!("{}", b);
}
想要准确的从 UTF-8 字符串中获取子串是较为复杂的事情,例如想要从 holla中国人नमस्ते 这种变长的字符串中取出某一个子串,使用标准库你是做不到的。 你需要在 crates.io 上搜索 utf8 来寻找想要的功能。
可以考虑尝试下这个库:utf8_slice。
字符串深度剖析
那么问题来了,为啥 String 可变,而字符串字面值 str 却不可以?
就字符串字面值来说,我们在编译时就知道其内容,最终字面值文本被直接硬编码进可执行文件中,这使得字符串字面值快速且高效,这主要得益于字符串字面值的不可变性。不幸的是,我们不能为了获得这种性能,而把每一个在编译时大小未知的文本都放进内存中(你也做不到!),因为有的字符串是在程序运行得过程中动态生成的。
对于 String 类型,为了支持一个可变、可增长的文本片段,需要在堆上分配一块在编译时未知大小的内存来存放内容,这些都是在程序运行时完成的:
首先向操作系统请求内存来存放 String 对象 在使用完成后,将内存释放,归还给操作系统 其中第一部分由 String::from 完成,它创建了一个全新的 String。
重点来了,到了第二部分,就是百家齐放的环节,在有垃圾回收 GC 的语言中,GC 来负责标记并清除这些不再使用的内存对象,这个过程都是自动完成,无需开发者关心,非常简单好用;但是在无 GC 的语言中,需要开发者手动去释放这些内存对象,就像创建对象需要通过编写代码来完成一样,未能正确释放对象造成的后果简直不可估量。
对于 Rust 而言,安全和性能是写到骨子里的核心特性,如果使用 GC,那么会牺牲性能;如果使用手动管理内存,那么会牺牲安全,这该怎么办?为此,Rust 的开发者想出了一个无比惊艳的办法:变量在离开作用域后,就自动释放其占用的内存:
{
let s = String::from("hello"); // 从此处起,s 是有效的
// 使用 s
} // 此作用域已结束,
// s 不再有效,内存被释放
与其它系统编程语言的 free 函数相同,Rust 也提供了一个释放内存的函数: drop,但是不同的是,其它语言要手动调用 free 来释放每一个变量占用的内存,而 Rust 则在变量离开作用域时,自动调用 drop 函数: 上面代码中,Rust 在结尾的 } 处自动调用 drop。
其实,在 C++ 中,也有这种概念: Resource Acquisition Is Initialization (RAII)。如果你使用过 RAII 模式的话应该对 Rust 的 drop 函数并不陌生。
这个模式对编写 Rust 代码的方式有着深远的影响,在后面章节我们会进行更深入的介绍。
1.5 🥥 元组
不多介绍,直接看示例即可:
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() 返回字符串的长度
(s, length)
}
1.6 🧇 结构体
一般定义
结构体我个人认为,它与Go语言、c/cpp的结构体思想都差不多,那么就先用其他语言渐入佳境
C/C++语言结构体:C/C++语言中的结构体定义使用关键字 struct,并且使用花括号包含成员变量。
#include <stdio.h>
struct Person {
char *name;
int age;
};
int main() {
struct Person p = {"John", 30};
printf("Name: %s, Age: %d\n", p.name, p.age);
return 0;
}
Go语言结构体:Go语言中的结构体定义使用关键字 type,并且使用花括号包含成员变量
package main
import "fmt"
type Person struct {
name string
age int
}
func main() {
p := Person{"John", 30}
fmt.Printf("Name: %s, Age: %d\n", p.name, p.age)
}
Rust结构体:Rust语言中的结构体定义使用关键字 struct,并且使用花括号包含成员变量,但是成员变量的定义使用了冒号和类型注解。
struct Person {
name: String,
age: u32,
}
fn main() {
let p = Person { name: String::from("John"), age: 30 };
println!("Name: {}, Age: {}", p.name, p.age);
}
结构体的内存排列
下面可以手打下下面的代码:
#[derive(Debug)]
struct File {
name: String,
data: Vec<u8>,
}
fn main() {
let file = File {
name: String::from("f1.txt"),
data: Vec::new()
};
let file_name = file.name;
let file_data_len = file.data.len();
println!("{:?}", file);
println!("{} is {} bytes long", file_name, file_data_len);
}
其实这段代码是错误的,在这段代码中,当你使用 let file_name = file.name; 和 let file_data_len = file.data.len(); 时,你将 file 的 name 和 data 字段的所有权移动到了 file_name 和 file_data_len 变量中。因此,当你尝试打印 file 变量时,它已经失去了 name 和 data 字段的所有权,导致编译错误。正好复习一下所有权
只要加上&即可,告诉Rust借我用下,用完还你:
let file_name = &file.name;
let file_data_len = file.data.len();
进入正题,上面定义的 File 结构体在内存中的排列如下图所示: 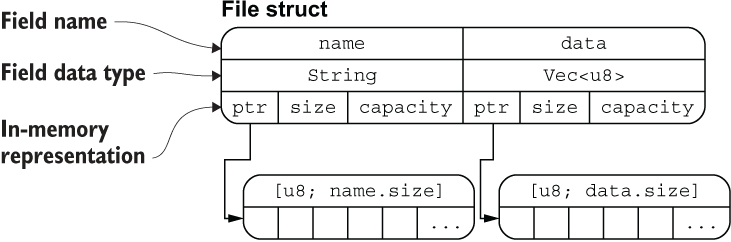 从图中可以清晰地看出 File 结构体两个字段 name 和 data 分别拥有底层两个 [u8] 数组的所有权(String 类型的底层也是 [u8] 数组),通过 ptr 指针指向底层数组的内存地址,这里你可以把 ptr 指针理解为 Rust 中的引用类型。
从图中可以清晰地看出 File 结构体两个字段 name 和 data 分别拥有底层两个 [u8] 数组的所有权(String 类型的底层也是 [u8] 数组),通过 ptr 指针指向底层数组的内存地址,这里你可以把 ptr 指针理解为 Rust 中的引用类型。
关于 ptr 指针,它是一个指向底层数组内存地址的指针。在 Rust 中,引用类型也是指针类型,因此你可以将 ptr 指针理解为 Rust 中的引用类型。当你使用 & 符号来借用 name 字段时,实际上是创建了一个指向 name 字段底层数组内存地址的引用。这个引用不拥有底层数组的所有权,因此你可以在不移动所有权的情况下访问 name 字段。
该图片也侧面印证了:把结构体中具有所有权的字段转移出去后,将无法再访问该字段,但是可以正常访问其它的字段。
很抽象,非常抽象。上面这段话是我搬运了作者的话,但是个人来说不是很理解。经过研究我的理解是:File 结构体的 name 和 data 字段都是拥有底层 [u8] 数组的所有权的。在 Rust 中,String 类型的底层也是 [u8] 数组。因此,name 字段拥有 String 类型的底层 [u8] 数组的所有权,而 data 字段拥有 Vec<u8> 类型的底层 [u8] 数组的所有权。 即,在 Rust 中,所有权是一个非常重要的概念。当你将一个拥有所有权的值移动到另一个变量中时,原始变量将失去对该值的所有权。这意味着你不能再访问该值,因为它已经被移动到了其他地方。在这段代码中,当你将 file.name 和 file.data 的所有权移动到 file_name 和 file_data_len 变量中时,file 变量将失去对这些值的所有权。因此,你不能再访问 file.name 和 file.data 字段了。
我不信不能访问,所以我做了下面的实验:
fn main() {
let file = File {
name: String::from("f1.txt"),
data: Vec::new()
};
let file_name = file.name;
let file_data_len = file.data.len();
println!("{}", file.name); // error: 转移了所有权
println!("{}", file.data); // error: 转移了所有权
println!("{:?}", file);
println!("{} is {} bytes long", file_name, file_data_len);
}
果然报错了:
error[E0277]: `Vec<u8>` doesn't implement `std::fmt::Display`
--> src/main.rs:17:18
|
17 | println!("{}", file.data);
| ^^^^^^^^^ `Vec<u8>` cannot be formatted with the default formatter // 无法<u8>使用默认格式化程序格式化“Vec”
|
= help: the trait `std::fmt::Display` is not implemented for `Vec<u8>`
= help:trait `std::fmt::Display`未为`Vec `实现<u8>
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
= 注意:在格式化字符串中,您可以使用`{:?}` (or联系我们 for pretty-print)代替
= note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info)
= 注意:此错误源于宏`$crate::format_args_nl`(在Nightly build中,使用-Z宏回溯运行以获取更多信息)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `Demo` due to previous error
元组结构体(Tuple Struct)
看示例即可学习
#![allow(unused)]
fn main() {
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
}
单元结构体(Unit-like Struct)
在Rust中,单元结构体(Unit-like Struct)是一种类似于元组结构体的结构体,但它不包含任何字段。具体来说,单元结构体的定义形式为:struct MyUnitStruct;,它不包含任何字段,也不需要任何语句作为结构体定义的主体。它的主要作用是在某些场景下提供一种空类型,用于表示某个操作或状态的存在或者不存在。
单元结构体的定义形式和普通结构体的定义形式非常类似,它也可以使用impl块来为它定义方法。在使用单元结构体时,通常只需要使用它的类型名即可,因为它不包含任何字段。
单元结构体在Rust中的主要作用是提供一种空类型,用于表示某个操作或状态的存在或者不存在,比如在某些函数中,可能需要传入一个参数,但实际上这个参数并不需要使用,这时可以使用单元结构体作为参数类型,表示这个操作需要传入一个参数,但实际上这个参数是没有用的。
#![allow(unused)]
fn main() {
struct AlwaysEqual;
let subject = AlwaysEqual;
// 我们不关心 AlwaysEqual 的字段数据,只关心它的行为,因此将它声明为单元结构体,然后再为它实现某个特征
impl SomeTrait for AlwaysEqual {
}
}
结构体数据的所有权
在之前的 User 结构体的定义中,有一处细节:我们使用了自身拥有所有权的 String 类型而不是基于引用的 &str 字符串切片类型。这是一个有意而为之的选择:因为我们想要这个结构体拥有它所有的数据,而不是从其它地方借用数据。 你也可以让 User 结构体从其它对象借用数据,不过这么做,就需要引入生命周期(lifetimes)这个新概念(也是一个复杂的概念),简而言之,生命周期能确保结构体的作用范围要比它所借用的数据的作用范围要小。
总之,如果你想在结构体中使用一个引用,就必须加上生命周期,否则就会报错:
struct User {
username: &str,
email: &str,
sign_in_count: u64,
active: bool,
}
fn main() {
let user1 = User {
email: "someone@example.com",
username: "someusername123",
active: true,
sign_in_count: 1,
};
}
error[E0106]: missing lifetime specifier
--> src/main.rs:2:15
|
2 | username: &str,
| ^ expected named lifetime parameter // 需要一个生命周期
|
help: consider introducing a named lifetime parameter // 考虑像下面的代码这样引入一个生命周期
|
1 ~ struct User<'a> {
2 ~ username: &'a str,
|
error[E0106]: missing lifetime specifier
--> src/main.rs:3:12
|
3 | email: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct User<'a> {
2 | username: &str,
3 ~ email: &'a str,
|
使用 #[derive(Debug)] 来打印结构体的信息
在前面的代码中我们使用 #[derive(Debug)] 对结构体进行了标记,这样才能使用 println!("{:?}", s); 的方式对其进行打印输出,如果不加,看看会发生什么:
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {}", rect1);
}
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
--> src/main.rs:12:29
|
12 | println!("rect1 is {}", rect1);
| ^^^^^ `Rectangle` cannot be formatted with the default formatter
|
= help: the trait `std::fmt::Display` is not implemented for `Rectangle`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
= note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `Demo` due to previous error
#[derive(Debug)]是一个宏,它可以自动生成实现Debug trait的代码。Debug trait是一个用于调试的trait,它允许我们打印出结构体的内容,以便于调试程序。因此,每次打印结构体时,我们需要在结构体上加上#[derive(Debug)],以便于使用println!宏打印出结构体的内容。
- 定义:
#[derive(Debug)] - 打印需要:
{:?}
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {:?}", rect1);
}
还有一个简单的输出 debug 信息的方法,那就是使用 dbg! 宏,它会拿走表达式的所有权,然后打印出相应的文件名、行号等 debug 信息,当然还有我们需要的表达式的求值结果。除此之外,它最终还会把表达式值的所有权返回!
dbg! 输出到标准错误输出 stderr,而 println! 输出到标准输出 stdout。
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let scale = 2;
let rect1 = Rectangle {
width: dbg!(30 * scale),
height: 50,
};
dbg!(&rect1);
}
1.7 枚举
枚举的一般写法
#[derive(Debug)]
enum Poker {
Clubs,
Spade,
Diamonds,
Hearts,
}
fn main() {
let heart = Poker::Hearts;
let diamonds = Poker::Diamonds;
println!("{:?}", heart);
println!("{:?}", diamonds);
}
学习到这里我感觉忽略了一个细节,我以为#[derive(Debug)]放到程序头就可以让每一个结构体打印,其实不然,可以看下面的程序:
#[derive(Debug)]
enum Poker {
Clubs,
Spade,
Diamonds,
Hearts,
}
struct PokerCard {
suit: Poker,
value: u8,
}
fn main() {
let c1 = PokerCard {
suit: Poker::Clubs,
value: 1,
};
let c2 = PokerCard {
suit: Poker::Diamonds,
value: 12,
};
println!("{:?}", c1);
println!("{:?}", c2);
}
运行以上程序会报错:
error[E0277]: `PokerCard` doesn't implement `Debug`
--> src/main.rs:24:22
|
24 | println!("{:?}", c1);
| ^^ `PokerCard` cannot be formatted using `{:?}`
|
= help: the trait `Debug` is not implemented for `PokerCard`
= note: add `#[derive(Debug)]` to `PokerCard` or manually `impl Debug for PokerCard`
= note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider annotating `PokerCard` with `#[derive(Debug)]`
|
9 | #[derive(Debug)]
|
error[E0277]: `PokerCard` doesn't implement `Debug`
--> src/main.rs:25:22
|
25 | println!("{:?}", c2);
| ^^ `PokerCard` cannot be formatted using `{:?}`
|
= help: the trait `Debug` is not implemented for `PokerCard`
= note: add `#[derive(Debug)]` to `PokerCard` or manually `impl Debug for PokerCard`
= note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider annotating `PokerCard` with `#[derive(Debug)]`
|
9 | #[derive(Debug)]
|
For more information about this error, try `rustc --explain E0277`.
error: could not compile `Demo` due to 2 previous errors
这就是理解上出现了错误,需要给每一个结构体加上#[derive(Debug)]才行
#[derive(Debug)]
enum Poker {
Clubs,
Spade,
Diamonds,
Hearts,
}
#[derive(Debug)]
struct PokerCard {
suit: Poker,
value: u8,
}
枚举再进阶一点就是:
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let m1 = Message::Quit;
let m2 = Message::Move{x:1,y:1};
let m3 = Message::ChangeColor(255,255,0);
}
同一化类型
最后,再用一个实际项目中的简化片段,来结束枚举类型的语法学习。
例如我们有一个 WEB 服务,需要接受用户的长连接,假设连接有两种:TcpStream 和 TlsStream,但是我们希望对这两个连接的处理流程相同,也就是用同一个函数来处理这两个连接,代码如下:
#![allow(unused)]
fn main() {
fn new (stream: TcpStream) {
let mut s = stream;
if tls {
s = negotiate_tls(stream)
}
// websocket是一个WebSocket<TcpStream>或者
// WebSocket<native_tls::TlsStream<TcpStream>>类型
websocket = WebSocket::from_raw_socket(
stream, ......)
}
}
此时,枚举类型就能帮上大忙:
#![allow(unused)]
fn main() {
enum Websocket {
Tcp(Websocket<TcpStream>),
Tls(Websocket<native_tls::TlsStream<TcpStream>>),
}
}
Option 枚举用于处理空值
Option 枚举包含两个成员,一个成员表示含有值:Some(T), 另一个表示没有值:None,定义如下:
enum Option<T> {
Some(T),
None,
}
其中 T 是泛型参数,Some(T)表示该枚举成员的数据类型是 T,换句话说,Some 可以包含任何类型的数据。\
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
println!("{:?}", five);
println!("{:?}", six);
println!("{:?}", none);
}
1.8 🔢 数组
rust的数组基本和JavaScript差不多,直接来一个综合例子:
- [0; 3]比较特殊,是[0, 0, 0]
fn main() {
// 编译器自动推导出one的类型
let one = [1, 2, 3];
// 显式类型标注
let two: [u8; 3] = [1, 2, 3];
let blank1 = [0; 3];
let blank2: [u8; 3] = [0; 3];
// arrays是一个二维数组,其中每一个元素都是一个数组,元素类型是[u8; 3]
let arrays: [[u8; 3]; 4] = [one, two, blank1, blank2];
// 借用arrays的元素用作循环中
for a in &arrays {
print!("{:?}: ", a);
// 将a变成一个迭代器,用于循环
// 你也可以直接用for n in a {}来进行循环
for n in a.iter() {
print!("\t{} + 10 = {}", n, n+10);
}
let mut sum = 0;
// 0..a.len,是一个 Rust 的语法糖,其实就等于一个数组,元素是从0,1,2一直增加到到a.len-1
for i in 0..a.len() {
sum += a[i];
}
println!("\t({:?} = {})", a, sum);
}
}
做个总结,数组虽然很简单,但是其实还是存在几个要注意的点:
- 数组类型容易跟数组切片混淆,
[T;n]描述了一个数组的类型,而[T]描述了切片的类型, 因为切片是运行期的数据结构,它的长度无法在编译期得知,因此不能用[T;n]的形式去描述 [u8; 3]和[u8; 4]是不同的类型,数组的长度也是类型的一部分- 在实际开发中,使用最多的是数组切片[T],我们往往通过引用的方式去使用
&[T],因为后者有固定的类型大小 至此,关于数据类型部分,我们已经全部学完了,对于 Rust 学习而言,我们也迈出了坚定的第一步,后面将开始更高级特性的学习。未来如果大家有疑惑需要检索知识,一样可以继续回顾过往的章节,因为本书不仅仅是一门 Rust 的教程,还是一本厚重的 Rust 工具书。
1.9 ⭕流程控制
其他都差不多,就这两个比较特殊。
for循环
for item in collection 转移所有权
for item in &collection 或者 for item in collection.iter() 不可变借用
for item in &mut collection 或者 for item in collection.iter_mut() 可变借用
loop
fn main() {
loop {
println!("again!");
}
}
1.10 💁♂️ 模式匹配
先展示一下Java17的Switch,就懂了:
public class Main {
public static void main(String[] args) {
enum Color { RED, GREEN, BLUE }
Color c = Color.RED;
switch (c) {
case RED -> System.out.println("RED");
case GREEN -> System.out.println("GREEN");
case BLUE -> System.out.println("BLUE");
default -> System.out.println("UNKNOWN");
}
}
}
再来看Rust简单的例子:
fn main() {
enum Color { Red, Green, Blue }
let c = Color::Red;
match c {
Color::Red => println!("RED"),
Color::Green => println!("GREEN"),
Color::Blue => println!("BLUE"),
_ => println!("UNKNOWN")
}
}
另外还有一些额外的技能
使用 match 表达式赋值
enum IpAddr {
Ipv4,
Ipv6
}
fn main() {
let ip1 = IpAddr::Ipv6;
let ip_str = match ip1 {
IpAddr::Ipv4 => "127.0.0.1",
_ => "::1",
};
println!("{}", ip_str);
}
同理 Java17也能做到
public class Main {
enum IpAddr {
Ipv4,
Ipv6
}
public static void main(String[] args) {
IpAddr ip1 = IpAddr.Ipv6;
String ipStr = switch (ip1) {
case Ipv4 -> "127.0.0.1";
default -> "::1";
};
System.out.println(ipStr);
}
}
_ 通配符
通过将 _ 其放置于其他分支后,_ 将会匹配所有遗漏的值。() 表示返回单元类型与所有分支返回值的类型相同,所以当匹配到 _ 后,什么也不会发生。
#![allow(unused)]
fn main() {
let some_u8_value = 0u8;
match some_u8_value {
1 => println!("one"),
3 => println!("three"),
5 => println!("five"),
7 => println!("seven"),
_ => (),
}
}
let if 进行匹配
当你只要匹配一个条件,且忽略其他条件时就用 if let ,否则都用 match。
#![allow(unused)]
fn main() {
if let Some(3) = v {
println!("three");
}
}
matches!宏
它可以将一个表达式跟模式进行匹配,然后返回匹配的结果 true or false。
#![allow(unused)]
fn main() {
let foo = 'f';
assert!(matches!(foo, 'A'..='Z' | 'a'..='z'));
println!("{}", matches!(foo, 'A'..='Z' | 'a'..='z')); // true
变量覆盖
无论是 match 还是 if let,他们都可以在模式匹配时覆盖掉老的值,绑定新的值:
fn main() {
let age = Some(30);
println!("在匹配前,age是{:?}",age);
if let Some(age) = age {
println!("匹配出来的age是{}",age);
}
println!("在匹配后,age是{:?}",age);
}
小结
本章的内容其实有很多被我删减了,而且有些我看的瞌睡都来了,因为我感觉有些内容Java也有,到时候项目用到再说具体可以看大大总结的:
1.11 👨🔧 方法
Rust和其他语言的方法对比: 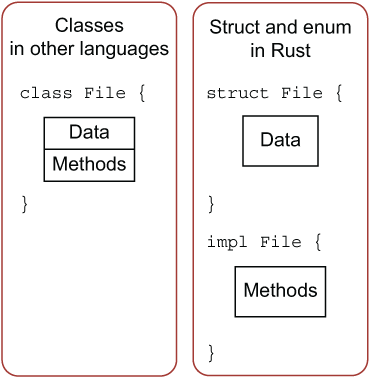
rust创建方法:
impl是实现implementation的缩写
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
fn main() {
let rect1 = Rectangle { width: 30, height: 50 };
println!(
"The area of the rectangle is {} square pixels.",
rect1.area()
);
}
其实看到这里是十分疑惑的,尤其是和fn对比起来,下面我来总结下:
- impl块用于定义在特定类型上的方法。它R往往跟结构体、枚举、特征(Trait)一起使用。
- fn用于定义普通的全局或内部功能。它不依赖于任何特定类型。
- 简单来说,要实现结构体的函数就要使用impl,它这个实现和Go语言十分类似!
Go语言进行对比学习,将person赋予SayHello能力。与 Rust 的 impl 不同的是,Go 中的接收者类型可以是值类型或指针类型。如果接收者类型是值类型,则会将该值的副本传递给方法,而如果接收者类型是指针类型,则会将指向该值的指针传递给方法。这使得我们可以在方法中修改接收者的状态,并将这些更改保持在调用方法之后。
type Person struct {
Name string
Age int
}
func (p Person) SayHello() {
fmt.Printf("Hello, my name is %s and I am %d years old.\n", p.Name, p.Age)
}
函数
fn add(a: i32, b: i32) -> i32 {
a + b
}
方法。至于这个self具体是什么东西,是否和Python的self一样,我将在下一节介绍。
struct Point {
x: f64,
y: f64,
}
impl Point {
fn distance(&self, other: &Point) -> f64 {
((self.x - other.x).powi(2) + (self.y - other.y).powi(2)).sqrt()
}
}
fn main() {
let p = Point {
x: 12.0,
y: 13.0,
};
let p2 = Point {
x: 14.0,
y: 15.0,
};
let ans = p.distance(&p2);
println!("{}", ans);
}
self、&self 和 &mut self
在一个 impl 块内,Self 指代被实现方法的结构体类型,self 指代此类型的实例,换句话说,self 指代的是结构体实例,这样的写法会让我们的代码简洁很多,而且非常便于理解:我们为哪个结构体实现方法,那么 self 就是指代哪个结构体的实例。
从而可以得出 >> 虽然 Rust 和 Python 是不同的编程语言,但它们在某些方面有相似之处。self 关键字在两种语言中都用于表示当前实例,使得我们可以在方法中访问和修改实例的属性和方法。
在Rust中,self是有所有权的概念的
self表示 结构体 的所有权转移到该方法中,这种形式用的较少&self表示该方法对 结构体 的不可变借用&mut self表示可变借用 总之,self 的使用就跟函数参数一样,要严格遵守 Rust 的所有权规则。
关联函数
参数中不包含 self 即可。在 impl 中且没有 self 的函数被称之为关联函数: 因为它没有 self,不能用 f.read() 的形式调用,因此它是一个函数而不是方法,它又在 impl 中,与结构体紧密关联,因此称为关联函数。
注意观察下面例子中的new
pub struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
pub fn new(width: u32, height: u32) -> Self {
Rectangle { width, height }
}
pub fn width(&self) -> u32 {
return self.width;
}
}
fn main() {
let rect1 = Rectangle::new(30, 50);
println!("{}", rect1.width());
}
Rust 中有一个约定俗成的规则,使用 new 来作为构造器的名称,出于设计上的考虑,Rust 特地没有用 new 作为关键字。
因为是函数,所以不能用 . 的方式来调用,我们需要用 :: 来调用,例如 let sq = Rectangle::new(3, 3);。这个方法位于结构体的命名空间中::: 语法用于关联函数和模块创建的命名空间。
多个 impl 定义
直接看例子即可
#![allow(unused)]
fn main() {
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
}
为枚举实现方法
枚举类型之所以强大,不仅仅在于它好用、可以同一化类型,还在于,我们可以像结构体一样,为枚举实现方法:
#![allow(unused)]
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
impl Message {
fn call(&self) {
// 在这里定义方法体
}
}
fn main() {
let m = Message::Write(String::from("hello"));
m.call();
}
1.121 🦜 泛型
结构体中使用泛型
先上例子体验一下:
- 使用的时候需要在结构体名字后面加入
<T>
#[derive(Debug)]
struct Point<T> {
x: T,
y: T,
}
fn main() {
let integer = Point { x: 5, y: 10 };
let float = Point { x: 1.0, y: 4.0 };
println!("{:?}", integer);
println!("{:?}", float);
}
此时的声明是x, y必须是一样的类型,如果要不一样的声明就要两种不同的泛型:
#[derive(Debug)]
struct Point<T,U> {
x: T,
y: U,
}
fn main() {
let integer = Point { x: 5, y: 1.1 };
let float = Point { x: 222, y: 3.0 };
println!("{:?}", integer);
println!("{:?}", float);
}
枚举中使用泛型
提到枚举类型,Option 永远是第一个应该被想起来的
enum Option<T> {
Some(T),
None,
}
Option<T> 是一个拥有泛型 T 的枚举类型,它第一个成员是 Some(T),存放了一个类型为 T 的值。得益于泛型的引入,我们可以在任何一个需要返回值的函数中,去使用 Option<T> 枚举类型来做为返回值,用于返回一个任意类型的值 Some(T),或者没有值 None。
方法中使用泛型
- 使用泛型参数前,依然需要提前声明:
impl<T>
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}
为具体的泛型类型实现方法
不仅能定义基于 T 的方法,还能针对特定的具体类型,进行方法定义,例如f32:
#![allow(unused)]
fn main() {
impl Point<f32> {
fn distance_from_origin(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
}
const 泛型(Rust 1.51 版本引入的重要特性)
在之前学过数组打印
fn display_array(arr: &[i32]) {
println!("{:?}", arr);
}
fn main() {
let arr: [i32; 3] = [1, 2, 3];
display_array(&arr);
let arr: [i32;2] = [1,2];
display_array(&arr);
}
现在将它改造成泛型
- 需要对 T 加一个限制
std::fmt::Debug,我的理解是加入后,目前的函数是支持传入可打印的数组
fn display_array<T: std::fmt::Debug>(arr: &[T]) {
println!("{:?}", arr);
}
fn main() {
let arr: [i32; 3] = [1, 2, 3];
display_array(&arr);
let arr: [i32;2] = [1,2];
display_array(&arr);
}
有了 const 泛型,也就是针对值的泛型,正好可以用于处理数组长度的问题:
fn display_array<T: std::fmt::Debug, const N: usize>(arr: [T; N]) {
println!("{:?}", arr);
}
fn main() {
let arr: [i32; 3] = [1, 2, 3];
display_array(arr);
let arr: [i32; 2] = [1, 2];
display_array(arr);
}
其实阅读到这里我有两个问题:
- 我是在没读懂作者说的处理数组长度的问题是什么意思
- 仅仅是加入
T: std::fmt::Debug不就可以了吗,为什么还要加入const N: usize。(可能是没理解1)
原因是:显式传递数组大小提供了一些安全性和灵活性优势,由于Rust的静态类型安全性,代码也可以以任何方式工作。在这种情况下,编译器可以从参数推断数组大小。总而言之,要求const N: usize作为参数主要通过在编译时而不是运行时启用验证来增强安全性。由于额外的信息,它为优化带来了更多的保证和机会。
光说不做啥也不懂,直接举一个如果不使用const N: usize的例子:
fn display_array<T: std::fmt::Debug>(arr: [T; N]) {
println!("{:?}", arr);
}
fn main() {
let arr: [i32; 3] = [1, 2, 3];
display_array(arr);
let arr2: [i32; 100000] = [0; 100000];
display_array(arr2);
}
error[E0425]: cannot find value `N` in this scope
--> src/main.rs:1:47
|
1 | fn display_array<T: std::fmt::Debug>(arr: [T; N]) {
| - ^ not found in this scope 在此范围内找不到
| |
| help: you might be missing a type parameter: `, N`
帮助:您可能缺少类型参数:', N'
error[E0282]: type annotations needed
--> src/main.rs:7:5
|
7 | display_array(arr);
| ^^^^^^^^^^^^^ cannot infer type for type parameter `T` declared on the function `display_array` 无法推断在函数display_array上声明的类型参数T的类型
Some errors have detailed explanations: E0282, E0425.
For more information about an error, try `rustc --explain E0282`.
error: could not compile `Demo` due to 2 previous errors
只能说Rust作者十分贴心,连help都给你写了,省的去Stack Overflow去搜索。这段代码会导致编译时错误,原因是arr2太大。 没有const大小参数,编译器没有关于数组参数大小的信息。它假定函数可以使用任何大小的数组进行调用。 这在编译时会导致问题,因为Rust中的函数对堆栈大小、线程堆栈大小等有严格限制。非常大的数组参数将超出这些限制。
经过我查询资料,省略size参数可能会导致:
- 非常大的大小的编译时错误。
- 由于未知大小,运行时出现不安全的内存问题。
- 有限优化的次优性能。
总结:要求const N: usize通过允许基于在编译时完全了解参数大小的静态验证和优化代码生成来提供安全性、安全性和效率。
泛型的效率 (单态化)
在 Rust 中泛型是零成本的抽象,意味着你在使用泛型时,完全不用担心性能上的问题。
但是任何选择都是权衡得失的,既然我们获得了性能上的巨大优势,那么又失去了什么呢?Rust 是在编译期为泛型对应的多个类型,生成各自的代码,因此损失了编译速度和增大了最终生成文件的大小。
具体来说:
Rust 通过在编译时进行泛型代码的 单态化(monomorphization) 来保证效率。单态化是一个通过填充编译时使用的具体类型,将通用代码转换为特定代码的过程。
编译器所做的工作正好与我们创建泛型函数的步骤相反,编译器寻找所有泛型代码被调用的位置并针对具体类型生成代码。
在原书中我根本没法跟上作者的单态化的理解,因为这是其他语言没有的理解。经过查阅举例说明:
- 单态化发生在编译时,而不是运行时
- 避免动态调度
- Rust安全、快速泛型方法的关键部分
- 可能会导致更大的二进制大小
fn add<T>(x: T, y: T) -> T {
x + y
}
fn main() {
let x = 1; // i32
let y = 2; // i32
let z = add(x, y); // z is i32
let a = 1.0; // f64
let b = 2.0; // f64
let c = add(a, b); // c is f64
}
在编译时,这会产生两个“单态”版本的 add:
fn add_i32(x: i32, y: i32) -> i32 { ... }
fn add_f64(x: f64, y: f64) -> f64 { ... }
它的调用结构会变成:
let z = add_i32(x, y);
let c = add_f64(a, b);
导致每种具体类型都有自己的泛型函数的专用版本。这意味着在使用泛型时没有运行时开销;当代码运行,它的执行效率就跟好像手写每个具体定义的重复代码一样。这个单态化过程正是 Rust 泛型在运行时极其高效的原因。
1.122 🥒 特征 Trait
特征在Rust中而可以暂时理解为抽象类(在圣经中作者说是接口,但是我看到默认方法的时候我就觉得是抽象,谁能在接口里实现方法的,见下⬇️) 特征定义了一组可以被共享的行为,只要实现了特征,你就能使用这组行为。
例如,我们现在有文章 Post 和微博 Weibo 两种内容载体,而我们想对相应的内容进行总结,也就是无论是文章内容,还是微博内容,都可以在某个时间点进行总结,那么总结这个行为就是共享的,因此可以用特征来定义:
pub trait Summary {
fn summary(&self) -> String;
}
pub struct Post {
pub title: String, // 标题
pub author: String, // 作者
pub content: String, // 内容
}
impl Summary for Post {
fn summary(&self) -> String {
format!("文章{}, 作者是{}", self.title, self.author)
}
}
pub struct Weibo {
pub username: String,
pub content: String
}
impl Summary for Weibo {
fn summary(&self) -> String {
format!("{}发表了微博{}", self.username, self.content)
}
}
fn main() {
let post = Post{title: "Rust语言简介".to_string(),author: "Sunface".to_string(), content: "Rust泰裤辣!".to_string()};
let weibo = Weibo{username: "sunface".to_string(),content: "好像微博没Tweet好用".to_string()};
println!("{}", post.summary());
println!("{}", weibo.summary());
}
孤儿规则(Orphan Rule)
孤儿规则(Rust中的孤儿规则旨在这个限制的主要目的是避免在不同库之间产生特质实现的冲突。例如,如果两个库都试图为同一个类型实现同一个特质,这将导致不确定性和潜在的错误。孤儿规则通过确保特质实现的唯一性来提高库之间的兼容性)这里,在圣经阅读过程中我认为此处地方讲的太过于混乱,甚至不好理解。下面详细讲解下。
孤儿规则适用于特质实现,具体要求如下:
- 特质必须是当前 crate(包)定义的;
- 类型必须是当前 crate(包)定义的。 只要满足以上两个条件之一,就可以为某个类型实现特质。这样做的目的是为了避免特质实现冲突,确保库之间的兼容性。
假设我们有两个库:my_crate 和 external_crate。在这两个库中,分别定义了一个类型和一个特质:
// external_crate库中
pub struct Foo;
pub trait Bar {
fn do_something(&self);
}
// my_crate库中
pub struct MyType;
pub trait MyTrait {
fn do_another_thing(&self);
}
根据孤儿规则,我们可以在 my_crate 中实现以下特质实现:
- 为
MyType实现MyTrait,因为MyType和MyTrait都是在当前 crate(包)定义的。
impl MyTrait for MyType {
fn do_another_thing(&self) {
println!("MyType 实现了 MyTrait!");
}
}
- 为
MyType实现external_crate中定义的Bar特质,因为MyType是在当前 crate(包)定义的。
use external_crate::Bar;
impl Bar for MyType {
fn do_something(&self) {
println!("MyType 实现了 Bar!");
}
}
然而,根据孤儿规则,我们不能在 my_crate 中实现以下特质实现: 为 external_crate 中定义的 Foo 类型实现 MyTrait 特质,因为这两个都不是在当前 crate(包)定义的。
// 这将导致编译错误,因为违反了孤儿规则
use external_crate::Foo;
impl MyTrait for Foo {
fn do_another_thing(&self) {
println!("Foo 实现了 MyTrait!");
}
}
总之,这样理解,在你的库(my_crate)中,你可以为当前库中定义的类型实现其他库(如external_crate)中定义的特质,也可以为当前库中定义的类型实现当前库中定义的特质。然而,你不能为其他库(如external_crate)中定义的类型实现你的库(my_crate)中定义的特质。孤儿规则主要关注的是特质实现,以确保库之间的兼容性。
默认方法
在讲述特征的地方修改两处地方即可知道默认方法的效果:
pub trait Summary {
fn summary(&self) -> String {
String::from("(Read more...)")
}
}
impl Summary for Post {
}
默认实现允许调用相同特征中的其他方法,哪怕这些方法没有默认实现。所以我一开始说它十分像其他语言的抽象类
pub trait Summary {
fn summarize_author(&self) -> String;
fn summary(&self) -> String {
String::from("(Read more...)")
}
}
pub struct Weibo {
pub username: String,
pub content: String
}
impl Summary for Weibo {
fn summary(&self) -> String {
format!("{}发表了微博{}", self.username, self.content)
}
//为了使用 Summary,只需要实现 summarize_author 方法即可:
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}
fn main() {
let weibo = Weibo{username: "sunface".to_string(),content: "好像微博没Tweet好用".to_string()};
println!("{}", weibo.summary());
println!("{}", weibo.summarize_author());
}
使用特征作为函数参数
现在我们来讲下,真正可以让特征大放光彩的地方。
现在,先定义一个函数,使用特征作为函数参数:
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}
impl Summary,只能说想出这个类型的人真的是起名鬼才,简直太贴切了,故名思义,它的意思是 实现了Summary特征 的 item 参数。
这样看来,这个特征确实吊,稍微修改下代码即可:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summary(&self) -> String {
String::from("(Read more...)")
}
}
pub struct Weibo {
pub username: String,
pub content: String
}
impl Summary for Weibo {
fn summary(&self) -> String {
format!("{}发表了微博{}", self.username, self.content)
}
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}
// 作为函数参数
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summary());
}
fn main() {
let weibo = Weibo{username: "sunface".to_string(),content: "好像微博没Tweet好用".to_string()};
notify(&weibo);
}
特征约束(trait bound)
在简单的场景下 impl Trait 这种语法糖就足够使用
pub fn notify(item1: &impl Summary, item2: &impl Summary) {}
如果我们想要强制函数的两个参数是同一类型? 可以再用上面的微博的例子举例
pub trait Summary {
fn summary(&self) -> String {
String::from("(Read more...)")
}
}
pub struct Post {
pub title: String, // 标题
pub author: String, // 作者
pub content: String, // 内容
}
impl Summary for Post {
fn summary(&self) -> String {
format!("文章{}, 作者是{}", self.title, self.author)
}
}
pub struct Weibo {
pub username: String,
pub content: String
}
impl Summary for Weibo {
fn summary(&self) -> String {
format!("{}发表了微博{}", self.username, self.content)
}
}
pub fn notify(item: &impl Summary, item2: &impl Summary) {
println!("{}", item.summary());
println!("{}", item2.summary());
}
fn main() {
let post = Post{title: "Rust语言简介".to_string(),author: "Sunface".to_string(), content: "Rust泰裤辣!".to_string()};
let weibo = Weibo{username: "sunface".to_string(),content: "好像微博没Tweet好用".to_string()};
notify(&post, &weibo);
}
泛型类型 T 说明了 item1 和 item2 必须拥有同样的类型,同时 T: Summary 说明了 T 必须实现 Summary 特征。 此时我们更换了之后在运行就运行不起来了
pub fn notify<T: Summary>(item: &T, item2: &T) {
println!("{}", item.summary());
println!("{}", item2.summary());
}
// ===================================
%%error[E0308]: mismatched types
--> src/main.rs:38:19
|
38 | notify(&post, &weibo);
| ^^^^^^ expected struct `Post`, found struct `Weibo`
|
= note: expected reference `&Post`
found reference `&Weibo`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `Demo` due to previous error%%
再看我在main中修改的和打印的结果就知道必须是同样的类型是什么意思了:
pub fn notify<T: Summary>(item: &T, item2: &T) {
println!("{}", item.summary());
println!("{}", item2.summary());
}
fn main() {
let post = Post{title: "Rust语言简介".to_string(),author: "Sunface".to_string(), content: "Rust泰裤辣!".to_string()};
let weibo = Weibo{username: "sunface".to_string(),content: "好像微博没Tweet好用".to_string()};
notify(&post, &post);
notify(&weibo, &weibo);
// 也可以这样改,者是运用了泛型参数
// notify::<Post>(&post, &post);
// notify::<Weibo>(&weibo, &weibo);
}
// 文章Rust语言简介, 作者是Sunface
// 文章Rust语言简介, 作者是Sunface
// sunface发表了微博好像微博没Tweet好用
// sunface发表了微博好像微博没Tweet好用
多重约束
要了解这个有两个概念需要了解,在原作者的文章中直接举例,但凡是个第一次学Rust的正常人都懵逼
- 导包
use std::fmt;
- 给Post加入Display特征的实现:
介绍下display:
pub trait Display { fn fmt(&self, f: &mut Formatter<'_>) -> Result<(), Error>; }
空格式的格式 trait,{}。 Display 与 Debug 类似,但 Display 是面向用户的输出,因此无法导出。 有关格式化程序的更多信息,请参见 模块级文档。
例子:
use std::fmt;
struct Point {
x: i32,
y: i32,
}
impl fmt::Display for Point {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
write!(f, "({}, {})", self.x, self.y)
}
}
let origin = Point { x: 0, y: 0 };
assert_eq!(format!("The origin is: {}", origin), "The origin is: (0, 0)");
有了上述两个基础,就可以给Post加入Display特征的实现
impl fmt::Display for Post {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
write!(f, "({}, {})", self.title, self.author)
}
}
然后就可以给方法加入新的特征约束:
pub fn notify(item: &(impl Summary + fmt::Display)) {
println!("{}", item.summary());
}
where约束
通过上面的学习再看where约束应该不难 当特征约束变得很多时,函数的签名将变得很复杂:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {}
严格来说,上面的例子还是不够复杂,但是我们还是能对其做一些形式上的改进,通过 where:
fn some_function<T, U>(t: &T, u: &U) -> i32
where T: Display + Clone,
U: Clone + Debug
{}
使用特征约束有条件地实现方法或特征
感觉作者在写这几章内容的时候应该是失恋了,也有可能作者对于某些知识具备可能没考虑到初学者的感受,在下面的例子中要看懂首先要知道这个特征:
Trait std::cmp::PartialOrd 一个可以比较排序顺序的值的 trait。
- Partial 部分存在的
- Ord 即order,排序
下面的例子就可以看到作者的意思
实现new,创建构造函数实现cmp_display,并约束传入的值只能是Display(可以打印)PartialOrd(可以排序)的。
#![allow(unused)]
fn main() {
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self {
x,
y,
}
}
}
// 在这个方法中,首先比较 x 和 y 的大小,然后打印出较大的值。
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}
}
相信你也和我一样,理解了特征约束是什么意思了。
函数返回中的 impl Trait
根据作者的例子进行举一反三:
pub fn notify(item: &impl Summary) {
println!("{}", item.summary());
}
fn returns_summarizable() -> impl Summary {
Post {
title: String::from("sunface"),
content: String::from(
"m1 max太厉害了,电脑再也不会卡",
),
author: String::from("none")
}
}
fn main() {
let post = returns_summarizable();
notify(&post);
}
修复上一节中的 largest 函数
在圣经中作者真是高看我了,我已经对这个函数失忆了,这段作者好像又从失恋中走出来了,感觉鬼斧神工的能力又回来了。 在源代码中是无法编译通过的:
fn largest<T>(list: &[T]) -> T {
let mut largest = list[0];
for &item in list.iter() {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {}", result);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {}", result);
}
error[E0369]: binary operation `>` cannot be applied to type `T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- T
| |
| T
|
help: consider restricting type parameter `T`
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `Demo` due to previous error
下面来一步一步来体验Rust的安全性,刚刚我们学习了可排序特性:PartialOrd,我们就给这个list加上这个特性:
fn largest<T: PartialOrd>(list: &[T]) -> T {
let mut largest = list[0];
for &item in list.iter() {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {}", result);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {}", result);
}
还是报错,但是不要紧,感觉要出来了
error[E0507]: cannot move out of a shared reference
--> src/main.rs:4:18
|
4 | for &item in list.iter() {
| ----- ^^^^^^^^^^^
| ||
| |data moved here
| |move occurs because `item` has type `T`, which does not implement the `Copy` trait
| help: consider removing the `&`: `item`
Some errors have detailed explanations: E0507, E0508.
For more information about an error, try `rustc --explain E0507`.
error: could not compile `Demo` due to 2 previous errors
从上述的提示看出来应该是iter()出了问题,错误的核心是 cannot move out of type [T], a non-copy slice,原因是 T 没有实现 Copy 特性,因此我们只能把所有权进行转移,毕竟只有 i32 等基础类型才实现了 Copy 特性,可以存储在栈上,而 T 可以指代任何类型(严格来说是实现了 PartialOrd 特征的所有类型)。
因此,为了让 T 拥有 Copy 特性,我们可以增加特征约束: 在这之前介绍下copy
pub unsafe fn copy
<T>(src: *const T, dst: *mut T, count: usize) 将 count * size_of::<T>() 字节从 src 复制到 dst。源和目标可能会重叠。
fn largest<T: PartialOrd + Copy>(list: &[T]) -> T {
let mut largest = list[0];
for &item in list.iter() {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {}", result);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {}", result);
}
如果并不希望限制 largest 函数只能用于实现了 Copy 特征的类型,我们可以在 T 的特征约束中指定 Clone 特征 而不是 Copy 特征。并克隆 list 中的每一个值使得 largest 函数拥有其所有权。使用 clone 函数意味着对于类似 String 这样拥有堆上数据的类型,会潜在地分配更多堆上空间,而堆分配在涉及大量数据时可能会相当缓慢。
// 通用的 trait,用于显式复制对象。
pub trait Clone {
fn clone(&self) -> Self;
fn clone_from(&mut self, source: &Self) { ... }
}
另一种 largest 的实现方式是返回在 list 中 T 值的引用。如果我们将函数返回值从 T 改为 &T 并改变函数体使其能够返回一个引用,我们将不需要任何 Clone 或 Copy 的特征约束而且也不会有任何的堆分配。尝试自己实现这种替代解决方式吧!
通过 derive 派生特征
在本书中,形如 #[derive(Debug)] 的代码已经出现了很多次,这种是一种特征派生语法,被 derive 标记的对象会自动实现对应的默认特征代码,继承相应的功能。
例如 Debug 特征,它有一套自动实现的默认代码,当你给一个结构体标记后,就可以使用 println!("{:?}", s) 的形式打印该结构体的对象。
再如 Copy 特征,它也有一套自动实现的默认代码,当标记到一个类型上时,可以让这个类型自动实现 Copy 特征,进而可以调用 copy 方法,进行自我复制。
总之,derive 派生出来的是 Rust 默认给我们提供的特征,在开发过程中极大的简化了自己手动实现相应特征的需求,当然,如果你有特殊的需求,还可以自己手动重载该实现。
调用方法需要引入特征
在一些场景中,使用 as 关键字做类型转换会有比较大的限制,因为你想要在类型转换上拥有完全的控制,例如处理转换错误,那么你将需要 TryInto:
TryInto:消耗 self 的尝试转换,这可能很昂贵,也可能不昂贵。库作者通常不应直接实现此 trait,而应首选实现 TryFrom trait,它具有更大的灵活性,并免费提供了等效的 TryInto 实现,这要归功于标准库中的全面实现。 有关此的更多信息,请参见 Into 的文档。
pub trait TryInto<T> {
type Error;
fn try_into(self) -> Result<T, Self::Error>;
}
例子:
use std::convert::TryInto;
fn main() {
let a: i32 = 10;
let b: u16 = 100;
let b_ = b.try_into()
.unwrap();
if a < b_ {
println!("Ten is less than one hundred.");
}
}
再看一个例子,可以将一个 i32 类型的值转换为 u8 类型,并在转换失败时返回一个错误:
use std::convert::TryInto;
fn main() {
let i: i32 = 300;
let result: Result<u8, _> = i.try_into(); // 尝试将 i32 类型转换为 u8 类型
match result {
Ok(value) => println!("Converted to u8: {}", value),
Err(e) => println!("Failed to convert: {}", e),
}
}
在上面的示例中,我们首先将 i 的值设置为 300,这是一个超出 u8 取值范围的值。然后,我们使用 i.try_into() 方法尝试将 i 转换为 u8 类型,并将结果存储在 result 变量中。由于 i 的值超出了 u8 的取值范围,因此转换失败,result 的值将是一个 Err 枚举变体,其中包含一个错误信息。在 match 表达式中,我们检查 result 的值,并打印出相应的信息。
总之,std::convert::TryInto trait 和相关方法提供了一种安全的类型转换方式,可以在转换失败时返回错误信息,避免了不安全的类型转换和潜在的运行时错误。
✨ 特征对象
原圣经中在这块讲的稍微有点混乱,让我来整理下。 在Rust编程语言中,特征对象(trait object) 是一种允许我们在运行时处理不同类型的对象,同时满足某一特征(trait)约束的方法。特征对象可以实现多态(polymorphism),这使得在处理同一特征的不同类型对象时可以更简单地编写代码。
特征对象的使用场景通常是当你希望使用一个指针(如引用或者Box)来指向实现了某个特征的类型,但是在编译时无法确定具体类型的情况。这时,你可以使用动态分发(dynamic dispatch) 来处理这些对象。动态分发会在运行时为你调用正确的方法实现,而不是在编译时确定。
要使用特征对象,你需要遵循以下几个步骤:
定义一个特征。例如,我们定义一个叫做Drawable的特征,包含一个draw方法:
trait Drawable {
fn draw(&self);
}
为多个结构体(struct)或枚举(enum)实现这个特征。比如,我们创建一个Circle结构体和一个Rectangle结构体,并实现Drawable特征:
struct Circle {
radius: f64,
}
struct Rectangle {
width: f64,
height: f64,
}
impl Drawable for Circle {
fn draw(&self) {
println!("Drawing a circle with radius: {}", self.radius);
}
}
impl Drawable for Rectangle {
fn draw(&self) {
println!("Drawing a rectangle with width: {} and height: {}", self.width, self.height);
}
}
使用特征对象。我们可以创建一个函数,接受一个实现了Drawable特征的类型的引用,并调用draw方法:
fn draw_shapes(shapes: &[&dyn Drawable]) {
for shape in shapes {
shape.draw();
}
}
在上述示例中,&dyn Drawable就是一个特征对象,它表示一个引用,指向实现了Drawable特征的类型。我们可以在运行时处理实现了Drawable特征的不同类型的对象。然后可以调用它们:
fn main() {
let circle = Circle { radius: 5.0 };
let rectangle = Rectangle { width: 10.0, height: 20.0 };
let shapes: [&dyn Drawable; 2] = [&circle, &rectangle];
draw_shapes(&shapes);
}
当然在原圣经中使用了集合,现在理解了就可以使用下:
- 创建一个存储
- 其中存储了一个动态数组
Vec,里面元素的类型是 Draw 特征对象:Box<dyn Draw>,任何实现了 Draw 特征的类型,都可以存放其中。
pub struct Screen {
pub components: Vec<Box<dyn Drawable>>,
}
- 为了让每一个形状都能被打印,给这个Screen实现方法
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
- 在main中,定义这些形状加入到集合里
fn main() {
let components: Vec<Box<dyn Drawable>> = vec![
Box::new(Circle {
radius: 1.5
}),
Box::new(Rectangle {
width: 2.0,
height: 2.0,
})
];
}
- 让它运行起来
fn main() {
let components: Vec<Box<dyn Drawable>> = vec![
Box::new(Circle {
radius: 1.5
}),
Box::new(Rectangle {
width: 2.0,
height: 2.0,
})
];
let screen = Screen {
components
};
screen.run();
}
- 你可能运行的很顺利,但是我运行的相当不顺利,原因出在
let components: Vec<Box<dyn Drawable>>,Rust在自动推断的时候一直判断它是一个circle,而不是动态的,导致出问题,不信可以删除试试
需要注意的是,使用特征对象时会有一些性能损失,因为Rust需要在运行时查找并调用正确的方法实现。但在许多情况下,这种性能损失是可以接受的,并且特征对象为我们提供了更大的灵活性。
特征对象的动态分发
回忆一下泛型章节我们提到过的,泛型是在编译期完成处理的:编译器会为每一个泛型参数对应的具体类型生成一份代码,这种方式是静态分发(static dispatch),因为是在编译期完成的,对于运行期性能完全没有任何影响。
与静态分发相对应的是动态分发(dynamic dispatch),在这种情况下,直到运行时,才能确定需要调用什么方法。之前代码中的关键字 dyn 正是在强调这一“动态”的特点。
当使用特征对象时,Rust 必须使用动态分发。编译器无法知晓所有可能用于特征对象代码的类型,所以它也不知道应该调用哪个类型的哪个方法实现。为此,Rust 在运行时使用特征对象中的指针来知晓需要调用哪个方法。动态分发也阻止编译器有选择的内联方法代码,这会相应的禁用一些优化。
下面这张图很好的解释了静态分发 Box<T> 和动态分发 Box<dyn Trait> 的区别: 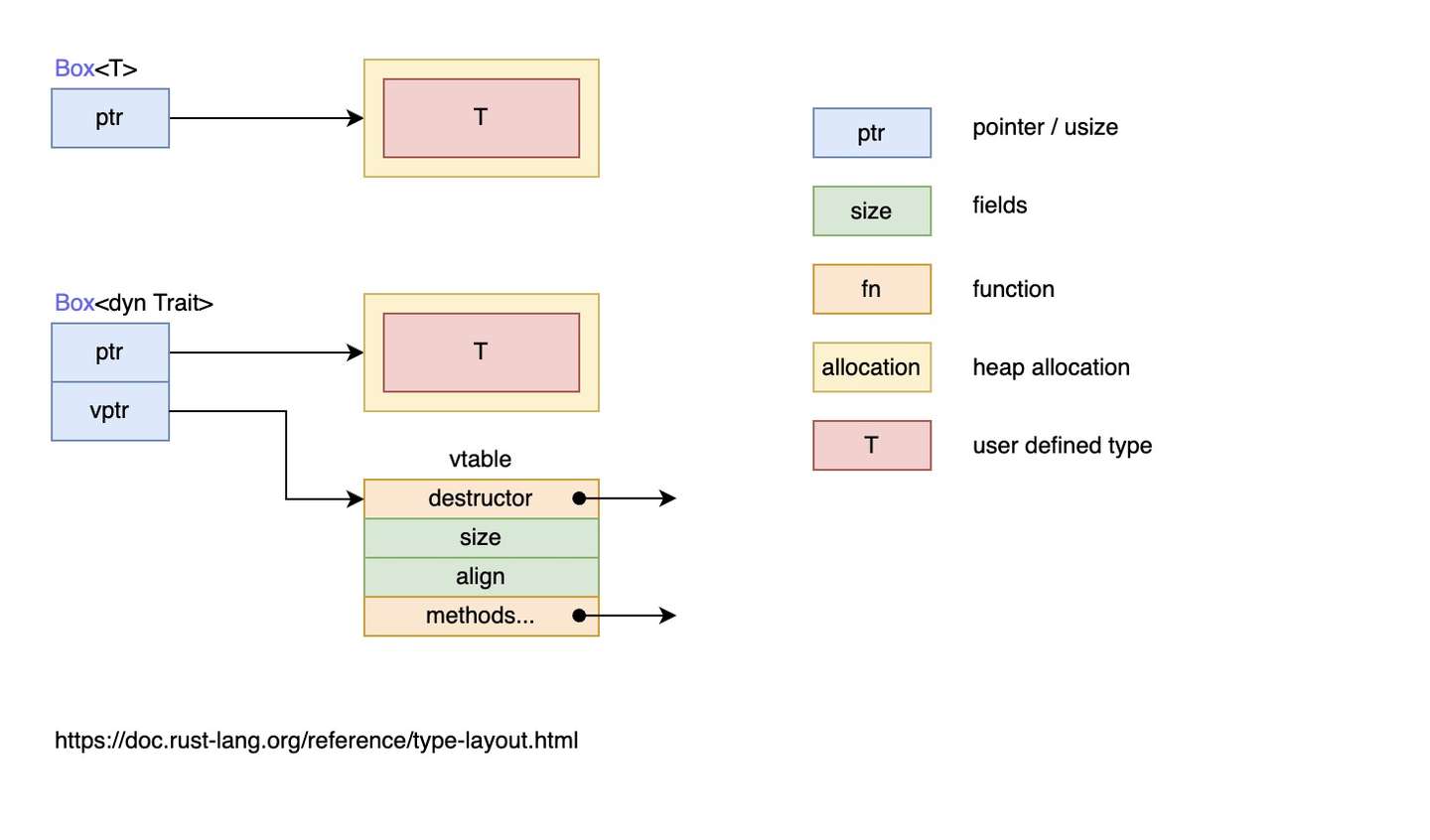 结合上文的内容和这张图可以了解:
结合上文的内容和这张图可以了解:
- 特征对象大小不固定:这是因为,对于特征 Draw,类型 Button 可以实现特征 Draw,类型 SelectBox 也可以实现特征 Draw,因此特征没有固定大小
- 几乎总是使用特征对象的引用方式,如
&dyn Draw、Box<dyn Draw>- 虽然特征对象没有固定大小,但它的引用类型的大小是固定的,它由两个指针组成(ptr 和 vptr),因此占用两个指针大小
- 一个指针 ptr 指向实现了特征 Draw 的具体类型的实例,也就是当作特征 Draw 来用的类型的实例,比如类型 Button 的实例、类型 SelectBox 的实例
- 另一个指针 vptr 指向一个虚表 vtable,vtable 中保存了类型 Button 或类型 SelectBox 的实例对于可以调用的实现于特征 Draw 的方法。当调用方法时,直接从 vtable 中找到方法并调用。之所以要使用一个 vtable 来保存各实例的方法,是因为实现了特征 Draw 的类型有多种,这些类型拥有的方法各不相同,当将这些类型的实例都当作特征 Draw 来使用时(此时,它们全都看作是特征 Draw 类型的实例),有必要区分这些实例各自有哪些方法可调用 简而言之,当类型 Button 实现了特征 Draw 时,类型 Button 的实例对象 btn 可以当作特征 Draw 的特征对象类型来使用,btn 中保存了作为特征对象的数据指针(指向类型 Button 的实例数据)和行为指针(指向 vtable)。
一定要注意,此时的 btn 是 Draw 的特征对象的实例,而不再是具体类型 Button 的实例,而且 btn 的 vtable 只包含了实现自特征 Draw 的那些方法(比如 draw),因此 btn 只能调用实现于特征 Draw 的 draw 方法,而不能调用类型 Button 本身实现的方法和类型 Button 实现于其他特征的方法。也就是说,btn 是哪个特征对象的实例,它的 vtable 中就包含了该特征的方法。
总的来说,泛型是静态分发,而特征对象则是使用动态分发。特征对象的大小不固定,使用特征对象的引用方式来解决,它的引用类型的大小是固定的,由两个指针组成。一个指针指向实现了特征的具体类型的实例,另一个指针则指向虚表,虚表中保存了实现了特征的类型的实例中可以调用的特征方法。因为特征对象的实例不再是具体类型的实例,所以只能调用实现于特征本身的方法,而不能调用具体类型实现的方法和实现于其他特征的方法。
Self 与 self
在 Rust 中,有两个self,一个指代当前的实例对象,一个指代特征或者方法类型的别名:
trait Draw {
fn draw(&self) -> Self;
}
#[derive(Clone)]
struct Button;
impl Draw for Button {
fn draw(&self) -> Self {
return self.clone()
}
}
fn main() {
let button = Button;
let newb = button.draw();
}
上述代码中,self指代的就是当前的实例对象,也就是 button.draw() 中的 button 实例,Self 则指代的是 Button 类型。
特征对象的限制
不是所有特征都能拥有特征对象,只有对象安全的特征才行。当一个特征的所有方法都有如下属性时,它的对象才是安全的:
- 方法的返回类型不能是 Self
- 方法没有任何泛型参数
对象安全对于特征对象是必须的,因为一旦有了特征对象,就不再需要知道实现该特征的具体类型是什么了。
小结:对象安全是指只有特定条件下的特征才能作为特征对象,不是所有特征都能拥有特征对象,只有对象安全的特征才可以。对象安全要求特征方法不能返回 Self 类型且没有泛型参数,因为特征对象的具体类型被抹去了,无法知道放入泛型参数类型是什么。标准库中的 Clone 特征就不符合对象安全的要求,因为它的其中一个方法返回了 Self 类型。如果违反了对象安全的规则,编译器会提示错误。
pub struct Screen {
pub components: Vec<Box<dyn Clone>>,
}
关联类型
在了解这个类型之前我来补全下Iterator
功能:
- Iterator是一个trait,代表一个可以产生一系列元素的迭代器。
- next方法是Iterator trait的一个方法,返回迭代器的下一个元素。
输入:
self:迭代器类型的可变引用。 输出: -Option<Self::Item>:一个包含下一个元素的Option枚举。如果没有更多元素了,则返回None。
pub trait Iterator {
type Item;
/// Returns the next element of the iterator, or `None` if there are no more elements.
///
/// # Examples
///
/// ```
/// let v = vec![1, 2, 3];
/// let mut iter = v.iter();
///
/// assert_eq!(iter.next(), Some(&1));
/// assert_eq!(iter.next(), Some(&2));
/// assert_eq!(iter.next(), Some(&3));
/// assert_eq!(iter.next(), None);
/// ```
fn next(&mut self) -> Option<Self::Item>;
}
- type Item:关联类型,代表迭代器产生的元素类型。
- fn next(&mut self) -> OptionSelf::Item:方法签名,使用&mut self来可变地引用迭代器本身,并返回下一个元素或None。在上面的例子中,我们使用了一个包含整数的向量来创建一个迭代器,并对其进行迭代,直到没有更多元素为止。
概述关联类型(associated type) 是Rust编程语言中一个重要的概念,它主要用于在trait中定义和抽象出具有关联性的类型。关联类型让我们能够在trait中定义一个类型的占位符,使得在实现trait时,这个占位符能被具体的类型替代。这样可以提高代码的灵活性和可复用性。
以下是关联类型相较于泛型的一些优点:
- 语义清晰:关联类型表示一种内在的关联,它表明在实现该trait的类型中存在一个与之相关的类型。而泛型参数表示一种更加外部的关联,它可以用于多种类型,与实现该trait的类型关联性不强。关联类型可以让代码的意图更加明确,提高代码的可读性。
- 简洁性:在某些场景下,使用关联类型可以让代码更简洁。尤其是在涉及多个泛型参数时,使用关联类型可以减少泛型参数的数量,让代码更简洁易懂。
- 灵活性:关联类型允许在trait内部对某些类型的约束进行更精细的控制,而泛型参数在某些情况下可能会导致约束不够严格。
关联类型在trait中使用type关键字进行定义。以下是一个关联类型的例子:
trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
在这个例子中,我们定义了一个名为Iterator的trait,它包含一个名为Item的关联类型和一个名为next的方法。next方法的返回类型是OptionSelf::Item,这里的Self::Item就是关联类型的用法,表示实现这个trait时,Item关联类型会被具体的类型替代。
当我们实现这个trait时,需要指定关联类型Item的具体类型。例如,我们可以实现一个简单的整数迭代器:
struct Integers {
start: i32,
end: i32,
}
impl Iterator for Integers {
type Item = i32;
fn next(&mut self) -> Option<Self::Item> {
if self.start >= self.end {
None
} else {
let result = self.start;
self.start += 1;
Some(result)
}
}
}
在这个例子中,我们为Integers结构体实现了Iterator trait,并指定了关联类型Item的具体类型为i32。在next方法中,我们可以直接使用Self::Item来表示i32类型。
通过关联类型,我们可以更灵活地定义和实现trait,使得代码更具有通用性和可复用性。
直接运行即可:
fn main() {
let mut a = Integers{
start: 1,
end: 5,
};
while let Some(itor) = a.next() {
println!("当前的整数: {}", itor);
}
}
读到这里肯定会有疑惑的,因为不知道泛型和关联类型到底有什么区别?为什么能用泛型解决的要用关联类型来解决?
我的答案是提高代码简洁性,如果只用上面的iterator我感觉是解释不清楚的,所以我用图的方式(节点和边作为特征的属性)来解决这个问题:
trait Graph<N, E> {
fn has_edge(&self, &N, &N) -> bool;
fn edges(&self, &N) -> Vec<E>;
}
impl<N, E, G> Graph<N, E> for G
where
G: Iterator<Item = (N, N, E)>
{
// ...
}
在这个例子中,我们定义了一个名为Graph的trait,它包含两个泛型参数N和E,分别表示节点和边的类型。然后我们为一个G类型实现了Graph<N, E>,这个G类型本身实现了Iterator<Item = (N, N, E)>。
在这种情况下,我们可以使用关联类型简化代码:
trait Graph {
type Node;
type Edge;
fn has_edge(&self, &Self::Node, &Self::Node) -> bool;
fn edges(&self, &Self::Node) -> Vec<Self::Edge>;
}
impl<G> Graph for G
where
G: Iterator<Item = (Self::Node, Self::Node, Self::Edge)>
{
// ...
}
通过使用关联类型,我们将Graph trait的泛型参数N和E替换为关联类型Node和Edge,从而使代码更加简洁易懂。
当然,并非所有情况下关联类型都比泛型更适用。具体选择应根据实际需求和场景进行权衡。实际上,在许多场景中,关联类型和泛型可以一起使用,以实现更灵活、更通用的代码。
默认泛型类型参数
没懂,我看到作者最后写了大部分情况用不到就没看了
当使用泛型类型参数时,可以为其指定一个默认的具体类型,例如标准库中的 std::ops::Add 特征:
trait Add<RHS=Self> {
type Output;
fn add(self, rhs: RHS) -> Self::Output;
}
它有一个泛型参数 RHS,但是与我们以往的用法不同,这里它给 RHS 一个默认值,也就是当用户不指定 RHS 时,默认使用两个同样类型的值进行相加,然后返回一个关联类型 Output。
可能上面那段不太好理解,下面我们用代码来举例:
use std::ops::Add;
#[derive(Debug, PartialEq)]
struct Point {
x: i32,
y: i32,
}
impl Add for Point {
type Output = Point;
fn add(self, other: Point) -> Point {
Point {
x: self.x + other.x,
y: self.y + other.y,
}
}
}
fn main() {
assert_eq!(Point { x: 1, y: 0 } + Point { x: 2, y: 3 },
Point { x: 3, y: 3 });
}
上面的代码主要干了一件事,就是为 Point 结构体提供 + 的能力,这就是运算符重载,不过 Rust 并不支持创建自定义运算符,你也无法为所有运算符进行重载,目前来说,只有定义在 std::ops 中的运算符才能进行重载。
跟 + 对应的特征是 std::ops::Add,我们在之前也看过它的定义 trait Add<RHS=Self>,但是上面的例子中并没有为 Point 实现 Add<RHS> 特征,而是实现了 Add 特征(没有默认泛型类型参数),这意味着我们使用了 RHS 的默认类型,也就是 Self。换句话说,我们这里定义的是两个相同的 Point 类型相加,因此无需指定 RHS。
与上面的例子相反,下面的例子,我们来创建两个不同类型的相加:
#![allow(unused)]
fn main() {
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}
}
这里,是进行 Millimeters + Meters 两种数据类型的 + 操作,因此此时不能再使用默认的 RHS,否则就会变成 Millimeters + Millimeters 的形式。使用 Add<Meters> 可以将 RHS 指定为 Meters,那么 fn add(self, rhs: RHS) 自然而言的变成了 Millimeters 和 Meters 的相加。
默认类型参数主要用于两个方面:
- 减少实现的样板代码
- 扩展类型但是无需大幅修改现有的代码 之前的例子就是第一点,虽然效果也就那样。在 + 左右两边都是同样类型时,只需要 impl Add 即可,否则你需要 impl Add<SOME_TYPE>,嗯,会多写几个字:)
对于第二点,也很好理解,如果你在一个复杂类型的基础上,新引入一个泛型参数,可能需要修改很多地方,但是如果新引入的泛型参数有了默认类型,情况就会好很多,添加泛型参数后,使用这个类型的代码需要逐个在类型提示部分添加泛型参数,就很麻烦;但是有了默认参数(且默认参数取之前的实现里假设的值的情况下)之后,原有的使用这个类型的代码就不需要做改动了。
归根到底,默认泛型参数,是有用的,但是大多数情况下,咱们确实用不到,当需要用到时,大家再回头来查阅本章即可,手上有剑,心中不慌。
调用同名的方法
拿下面的例子进行举例说明同名方法:
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
优先调用类型上的方法。默认调用该类型中定义的方法:
fn main() {
let person = Human;
person.fly();
}
// *waving arms furiously*
调用特征上的方法。如果要使用其他特征可以显示调用:
fn main() {
let person = Human;
Pilot::fly(&person); // 调用Pilot特征上的方法
Wizard::fly(&person); // 调用Wizard特征上的方法
person.fly(); // 调用Human类型自身的方法
}
//This is your captain speaking.
//Up!
//*waving arms furiously*
完全限定语法。下面有这样的示例代码:
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Dog::baby_name());
}
如果显式调用Dog是没有问题,但是调用Animal就有问题:
error[E0283]: type annotations needed
--> src/main.rs:21:43
|
21 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^ cannot infer type
|
= note: cannot satisfy `_: Animal`
For more information about this error, try `rustc --explain E0283`.
error: could not compile `Demo` due to previous erro
但是但凡是个正常逻辑都不会这样写代码:
- 有一个狗的结构体,为狗实现一个baby_name的方法,会打印出一个Spot。
- 有一个Animal特征(在这里可以理解为一个抽象类),狗如果实现了这个抽象类的方法(impl Animal for Dog),那么这个baby_name的方法打印puppy
整理完逻辑后再看这个println!("A baby dog is called a {}", Animal::baby_name());代码,这个Animal特征都没有被任何结构体所实现完全就不知道是要打印谁?万一我又添加一个impl Animal for Cat。
明白上述问题,Rust就通过完全限定语法来解决,明确这个Animal是谁:as
fn main() {
println!("A baby dog is called a {}", Dog::baby_name());
println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
}
// A baby dog is called a Spot
// A baby dog is called a puppy
再Rust中完全限定语法的定义为:
<Type as Trait>::function(receiver_if_method, next_arg, ...);
上面定义中,第一个参数是方法接收器 receiver (三种 self),只有方法才拥有,例如关联函数就没有 receiver。
特征定义中的特征约束
首先来感受一下这是什么东西,直接CV下面的代码:
use std::fmt;
use std::fmt::Display;
trait OutlinePrint: Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {} *", output);
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
impl OutlinePrint for Point {}
struct Point {
x: i32,
y: i32,
}
// impl fmt::Display for Point {
// fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
// write!(f, "({}, {})", self.x, self.y)
// }
// }
fn main() {
let p = Point{x: 11, y: 12};
println!("{}", p);
Point::outline_print(&p);
}
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:16:6
|
16 | impl OutlinePrint for Point {}
| ^^^^^^^^^^^^ `Point` 不能用默认格式化的点进行格式化
|
= help: 对于 "Point "来说,"std::fmt::Display "这个特性没有实现。
= note: 在格式化字符串中,你可以使用`{:?}`(或{:#?}来代替pretty-print)。
note: required by a bound in `OutlinePrint`
--> src/main.rs:4:21
|
4 | trait OutlinePrint: Display {
| ^^^^^^^ 在 "OutlinePrint "中,此绑定所要求的。
For more information about this error, try `rustc --explain E0277`.
warning: `Demo` (bin "Demo") generated 1 warning
error: could not compile `Demo` due to previous error; 1 warning emitted
然后把注释取消,就可以运行了:
(11, 12)
************
* *
* (11, 12) *
* *
************
上面代码为 Point 一开始是没有实现display特征的,但是OutlinePrint实现了display,现在point要实现OutlinePrint的特征(可以实现outline_print),那么就要实现display方法,否则无法使用,所以point才会有(对于 "Point "来说,"std::fmt::Display "这个特性没有实现)报错。简而言之:特征定义中的特征约束,用于让某个特征A使用另一个特征B的功能。如果想实现特征A,则必须先实现特征B。例如,特征OutlinePrint需要实现Display特征后,才能在其方法中调用to_string方法。没有特征约束时编译器会报错,因此需要先满足编译器的要求,为类型实现所需的特征。
在外部类型上实现外部特征 (newtype)
该封装类型是本地的,因此我们可以为此类型实现外部的特征。
newtype 模式,简而言之:就是为一个元组结构体创建新类型。下面这段代码使用了装饰器模式,包装了一个中括号:
use std::fmt;
struct Wrapper(Vec<String>);
impl fmt::Display for Wrapper {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "[{}]", self.0.join(", "))
}
}
fn main() {
let w = Wrapper(vec![String::from("hello"), String::from("world")]);
println!("w = {}", w);
}
// w = [hello, world]
其中,struct Wrapper(Vec<String>) 就是一个元组结构体,它定义了一个新类型 Wrapper 可以看到在实现fmt的时候内部使用了self.0.join(", "),这就是访问数组里的内容,但是这样很麻烦,所以Rust就提供了一个特征叫 Deref,实现该特征后,可以自动做一层类似类型转换的操作,可以将 Wrapper 变成Vec<String>来使用。这样就会像直接使用数组那样去使用 Wrapper,而无需为每一个操作都添加上 self.0。
1.13 👨👩👧👦 集合
动态数组 Vector
创建动态数组
使用 Vec::new 创建动态数组是最 rusty 的方式,它调用了 Vec 中的 new 关联函数:
let v: Vec<i32> = Vec::new();
let mut v = Vec::new();
v.push(1);
vec![]
还可以使用宏 vec! 来创建数组
let v = vec![1, 2, 3];
添加元素
let mut v = Vec::new();
v.push(1);
读取元素
读取指定位置的元素有两种方式可选:
- 通过下标索引访问。
- 使用 get 方法。
let v = vec![1, 2, 3, 4, 5];
let third: &i32 = &v[2];
println!("第三个元素是 {}", third);
match v.get(2) {
Some(third) => println!("第三个元素是 {third}"),
None => println!("去你的第三个元素,根本没有!"),
}
删除元素
删除某个位置
let mut vec = vec![1, 2, 3, 4, 5];
let index = vec.iter().position(|&x| x == 3).unwrap(); // 找到元素3的索引位置
vec.remove(index); // 删除元素3
删除头结点 & 尾节点
let mut vec = vec![1, 2, 3, 4, 5];
vec.remove(0); // 删除头结点
vec.pop(); // 删除尾节点
迭代遍历
let v = vec![1, 2, 3];
for i in &v {
println!("{i}");
}
存储不同类型的元素
#[derive(Debug)]
enum IpAddr {
V4(String),
V6(String)
}
fn main() {
let v = vec![
IpAddr::V4("127.0.0.1".to_string()),
IpAddr::V6("::1".to_string())
];
for ip in v {
show_addr(ip)
}
}
fn show_addr(ip: IpAddr) {
println!("{:?}",ip);
}
Vector 与其元素共存亡
跟结构体一样,Vector 类型在超出作用域范围后,会被自动删除:
{
let v = vec![1, 2, 3];
// ...
} // <- v超出作用域并在此处被删除
当 Vector 被删除后,它内部存储的所有内容也会随之被删除。目前来看,这种解决方案简单直白,但是当 Vector 中的元素被引用后,事情可能会没那么简单。
同时借用多个数组元素
既然涉及到借用数组元素,那么很可能会遇到同时借用多个数组元素的情况,还记得在所有权和借用章节咱们讲过的借用规则嘛?如果记得,就来看看下面的代码 😃
如果有一个不可变引用,则可以假定其引用的数据是不会被修改的,但是同时另外一个可变引用却可以对数据进行修改,这显然是不安全的。因此,Rust编译器会将这种情况视为编译错误,要求开发者更改代码,保证在同一时间内只存在一种类型的借用(可变或不可变),以保证代码的内存安全。
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {first}");
}
先不运行,来推断下结果,首先 first = &v[0] 进行了不可变借用,v.push 进行了可变借用,如果 first 在 v.push 之后不再使用,那么该段代码可以成功编译(原因见引用的作用域)。
可是上面的代码中,first 这个不可变借用在可变借用 v.push 后被使用了,那么妥妥的,编译器就会报错:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable 无法对v进行可变借用,因此之前已经进行了不可变借用
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here // 不可变借用发生在此处
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here // 可变借用发生在此处
7 |
8 | println!("The first element is: {}", first);
| ----- immutable borrow later used here // 不可变借用在这里被使用
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` due to previous error
其实,按理来说,这两个引用不应该互相影响的:一个是查询元素,一个是在数组尾部插入元素,完全不相干的操作,为何编译器要这么严格呢?
原因在于:数组的大小是可变的,当旧数组的大小不够用时,Rust 会重新分配一块更大的内存空间,然后把旧数组拷贝过来。这种情况下,之前的引用显然会指向一块无效的内存,这非常 rusty —— 对用户进行严格的教育。
其实想想,在长大之后,我们感激人生路上遇到过的严师益友,正是因为他们,我们才在正确的道路上不断前行,虽然在那个时候,并不能理解他们,而 Rust 就如那个良师益友,它不断的在纠正我们不好的编程习惯,直到某一天,你发现自己能写出一次性通过的漂亮代码时,就能明白它的良苦用心。
有两种方法可以解决上述问题:
// 方法一:将 &v[0] 放在 v.push(6) 语句之后
let mut v = vec![1, 2, 3, 4, 5];
v.push(6);
let first = &v[0];
println!("The first element is: {}", first);
// 方法二:使用 v[0] 访问第一个元素
let mut v = vec![1, 2, 3, 4, 5];
v.push(6);
let first = v[0];
println!("The first element is: {}", first);
KV 存储 HashMap
用 new 方法创建 & 查询
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
// 将宝石类型和对应的数量写入表中
map.insert("红宝石", 1);
map.insert("蓝宝石", 2);
map.insert("河边捡的误以为是宝石的破石头", 18);
// 使用 {} 打印会报错
// println!("{}", map.get("红宝石"));
// 使用 {:?} 打印可以正常输出
println!("{:?}", map.get("红宝石"));
for (key, value) in &map {
println!("{}: {}", key, value);
}
}
在这里会有一个小问题:对于 HashMap,get() 方法返回的是 Option<&V> 类型,其中 V 是 HashMap 存储的值类型。由于 &V 类型默认没有实现 std::fmt::Display trait,所以不能直接使用 {} 进行打印,否则会报错。
但是,&V 类型默认实现了 std::fmt::Debug trait,因此可以使用 {:?} 进行打印,它会自动调用 Debug trait 中的 fmt() 方法来输出可读性较高的调试信息。
小结:
- get 方法返回一个 Option<&i32> 类型:当查询不到时,会返回一个 None,查询到时返回 Some(&i32)
- &i32 是对 HashMap 中值的借用,如果不使用借用,可能会发生所有权的转移
使用迭代器和 collect 方法创建
fn main() {
use std::collections::HashMap;
let teams_list = vec![
("中国队".to_string(), 100),
("美国队".to_string(), 10),
("日本队".to_string(), 50),
];
let teams_map: HashMap<_,_> = teams_list.into_iter().collect();
println!("{:?}",teams_map)
}
// {"中国队": 100, "美国队": 10, "日本队": 50}
所有权转移
HashMap 的所有权规则与其它 Rust 类型没有区别:
- 若类型实现 Copy 特征,该类型会被复制进 HashMap,因此无所谓所有权
- 若没实现 Copy 特征,所有权将被转移给 HashMap 中
fn main() {
use std::collections::HashMap;
let name = String::from("Sunface");
let age = 18;
let mut handsome_boys = HashMap::new();
handsome_boys.insert(&name, age);
std::mem::drop(name);
println!("因为过于无耻,{:?}已经被除名", handsome_boys);
println!("还有,他的真实年龄远远不止{}岁", age);
}
上面代码,我们借用 name 获取了它的引用,然后插入到 handsome_boys 中,至此一切都很完美。但是紧接着,就通过 drop 函数手动将 name 字符串从内存中移除,再然后就报错了:
error[E0505]: cannot move out of `name` because it is borrowed
--> src/main.rs:10:20
|
8 | handsome_boys.insert(&name, age);
| ----- borrow of `name` occurs here
9 |
10 | std::mem::drop(name);
| ^^^^ move out of `name` occurs here
11 | println!("因为过于无耻,{:?}已经被除名", handsome_boys);
| ------------- borrow later used here
For more information about this error, try `rustc --explain E0505`.
error: could not compile `Demo` due to previous error
更新 HashMap 中的值
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert("Blue", 10);
// 覆盖已有的值
let old = scores.insert("Blue", 20);
assert_eq!(old, Some(10));
// 查询新插入的值
let new = scores.get("Blue");
assert_eq!(new, Some(&20));
// 查询Yellow对应的值,若不存在则插入新值
let v = scores.entry("Yellow").or_insert(5);
assert_eq!(*v, 5); // 不存在,插入5
// 查询Yellow对应的值,若不存在则插入新值
let v = scores.entry("Yellow").or_insert(50);
assert_eq!(*v, 5); // 已经存在,因此50没有插入
}
更新已有值
use std::collections::HashMap;
let text = "hello world wonderful world";
let mut map = HashMap::new();
// 根据空格来切分字符串(英文单词都是通过空格切分)
for word in text.split_whitespace() {
let count = map.entry(word).or_insert(0);
*count += 1;
}
println!("{:?}", map);
上面代码中,新建一个 map 用于保存词语出现的次数,插入一个词语时会进行判断:若之前没有插入过,则使用该词语作 Key,插入次数 0 作为 Value,若之前插入过则取出之前统计的该词语出现的次数,对其加一。
有两点值得注意:
- or_insert 返回了 &mut v 引用,因此可以通过该可变引用直接修改 map 中对应的值
- 使用 count 引用时,需要先进行解引用 *count,否则会出现类型不匹配
1.14 💱 生命周期
生命周期也是比较重要的概念,在圣经中已经讲的很好了,我也没必要添油加醋,直接搬运过来方便以后查看。
悬垂指针和生命周期
生命周期的主要作用是避免悬垂引用,它会导致程序引用了本不该引用的数据:
{
let r;
{
let x = 5;
r = &x;
}
println!("r: {}", r);
}
这段代码有几点值得注意:
let r;的声明方式貌似存在使用null的风险,实际上,当我们不初始化它就使用时,编译器会给予报错- r 引用了内部花括号中的 x 变量,但是 x 会在内部花括号 } 处被释放,因此回到外部花括号后,r 会引用一个无效的 x 此处
r 就是一个悬垂指针,它引用了提前被释放的变量 x,可以预料到,这段代码会报错:
error[E0597]: `x` does not live long enough // `x` 活得不够久
--> src/main.rs:7:17
|
7 | r = &x;
| ^^ borrowed value does not live long enough // 被借用的 `x` 活得不够久
8 | }
| - `x` dropped here while still borrowed // `x` 在这里被丢弃,但是它依然还在被借用
9 |
10 | println!("r: {}", r);
| - borrow later used here // 对 `x` 的借用在此处被使用
在这里 r 拥有更大的作用域,或者说活得更久。如果 Rust 不阻止该悬垂引用的发生,那么当 x 被释放后,r 所引用的值就不再是合法的,会导致我们程序发生异常行为,且该异常行为有时候会很难被发现。
借用检查
为了保证 Rust 的所有权和借用的正确性,Rust 使用了一个借用检查器(Borrow checker),来检查我们程序的借用正确性:
#![allow(unused)]
fn main() {
{
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {}", r); // |
} // ---------+
}
这段代码和之前的一模一样,唯一的区别在于增加了对变量生命周期的注释。这里,r 变量被赋予了生命周期 'a,x 被赋予了生命周期 'b,从图示上可以明显看出生命周期 'b 比 'a 小很多。
在编译期,Rust 会比较两个变量的生命周期,结果发现 r 明明拥有生命周期 'a,但是却引用了一个小得多的生命周期 'b,在这种情况下,编译器会认为我们的程序存在风险,因此拒绝运行。
如果想要编译通过,也很简单,只要 'b 比 'a 大就好。总之,x 变量只要比 r 活得久,那么 r 就能随意引用 x 且不会存在危险:
{
let x = 5; // ----------+-- 'b
// |
let r = &x; // --+-- 'a |
// | |
println!("r: {}", r); // | |
// --+ |
}
根据之前的结论,我们重新实现了代码,现在 x 的生命周期 'b 大于 r 的生命周期 'a,因此 r 对 x 的引用是安全的。
通过之前的内容,我们了解了何为生命周期,也了解了 Rust 如何利用生命周期来确保引用是合法的,下面来看看函数中的生命周期。
在 Rust 中,生命周期的长短与变量的作用域有关。生命周期指明了引用(或借用)的有效期,在其生命周期内才能进行访问操作,超出生命周期则不能再使用。 对于上述代码中的变量 x 和 r,它们分别有自己的作用域和生命周期。变量 x 的作用域是当前代码块内部,而生命周期是 'b,即从 x 定义开始一直到当前代码块结束。变量 r 是对变量 x 的引用,其生命周期是 'a,也就是从 r 定义开始一直到当前代码块结束。由于代码块的作用域包括了变量 r 和 x,因此变量 r 的生命周期必须小于或等于其引用的变量 x 的生命周期。 由于变量 x 的生命周期('b)比变量 r 的生命周期('a)更长,因此变量 x 在变量 r 的引用期间都是有效的,即 r 引用的是有效值,不会出现悬垂指针(Dangling Pointer)等内存安全问题。如果将变量 r 的生命周期延长到比变量 x 更长的时间,就可能会出现悬垂指针,导致程序崩溃或出现其他内存安全问题。 因此,在 Rust 中,生命周期长的变量必须至少包含生命周期短的变量的整个生命周期。这是 Rust 保证内存安全的重要机制之一。
函数中的生命周期
先来考虑一个例子 - 返回两个字符串切片中较长的那个,该函数的参数是两个字符串切片,返回值也是字符串切片:
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
这段 longest 实现,非常标准优美,就连多余的 return 和分号都没有,可是现实总是给我们重重一击:
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter // 参数需要一个生命周期
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is
borrowed from `x` or `y`
= 帮助: 该函数的返回值是一个引用类型,但是函数签名无法说明,该引用是借用自 `x` 还是 `y`
help: consider introducing a named lifetime parameter // 考虑引入一个生命周期
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ^^^^ ^^^^^^^ ^^^^^^^ ^^^
喔,这真是一个复杂的提示,那感觉就好像是生命周期去非诚勿扰相亲,结果在初印象环节就 23 盏灯全灭。等等,先别急,如果你仔细阅读,就会发现,其实主要是编译器无法知道该函数的返回值到底引用 x 还是 y ,因为编译器需要知道这些,来确保函数调用后的引用生命周期分析。
不过说来尴尬,就这个函数而言,我们也不知道返回值到底引用哪个,因为一个分支返回 x,另一个分支返回 y...这可咋办?先来分析下。
我们在定义该函数时,首先无法知道传递给函数的具体值,因此到底是 if 还是 else 被执行,无从得知。其次,传入引用的具体生命周期也无法知道,因此也不能像之前的例子那样通过分析生命周期来确定引用是否有效。同时,编译器的借用检查也无法推导出返回值的生命周期,因为它不知道 x 和 y 的生命周期跟返回值的生命周期之间的关系是怎样的(说实话,人都搞不清,何况编译器这个大聪明)。
因此,这时就回到了文章开头说的内容:在存在多个引用时,编译器有时会无法自动推导生命周期,此时就需要我们手动去标注,通过为参数标注合适的生命周期来帮助编译器进行借用检查的分析。
生命周期标注语法
生命周期标注并不会改变任何引用的实际作用域 -- 鲁迅
鲁迅说过的话,总是值得重点标注,当你未来更加理解生命周期时,你才会发现这句话的精髓和重要!现在先简单记住,标记的生命周期只是为了取悦编译器,让编译器不要难为我们,记住了吗?没记住,再回头看一遍,这对未来你遇到生命周期问题时会有很大的帮助!
在很多时候编译器是很聪明的,但是总有些时候,它会化身大聪明,自以为什么都很懂,然后去拒绝我们代码的执行,此时,就需要我们通过生命周期标注来告诉这个大聪明:别自作聪明了,听我的就好。
例如一个变量,只能活一个花括号,那么就算你给它标注一个活全局的生命周期,它还是会在前面的花括号结束处被释放掉,并不会真的全局存活。
生命周期的语法也颇为与众不同,以 ' 开头,名称往往是一个单独的小写字母,大多数人都用 'a 来作为生命周期的名称。 如果是引用类型的参数,那么生命周期会位于引用符号 & 之后,并用一个空格来将生命周期和引用参数分隔开:
&i32 // 一个引用
&'a i32 // 具有显式生命周期的引用
&'a mut i32 // 具有显式生命周期的可变引用
一个生命周期标注,它自身并不具有什么意义,因为生命周期的作用就是告诉编译器多个引用之间的关系。例如,有一个函数,它的第一个参数 first 是一个指向 i32 类型的引用,具有生命周期 'a,该函数还有另一个参数 second,它也是指向 i32 类型的引用,并且同样具有生命周期 'a。此处生命周期标注仅仅说明,这两个参数 first 和 second 至少活得和'a 一样久,至于到底活多久或者哪个活得更久,抱歉我们都无法得知:
fn useless<'a>(first: &'a i32, second: &'a i32) {}
函数签名中的生命周期标注 继续之前的 longest 函数,从两个字符串切片中返回较长的那个:
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
需要注意的点如下:
- 和泛型一样,使用生命周期参数,需要先声明 <'a>
- x、y 和返回值至少活得和 'a 一样久(因为返回值要么是 x,要么是 y) 该函数签名表明对于某些生命周期 'a,函数的两个参数都至少跟 'a 活得一样久,同时函数的返回引用也至少跟 'a 活得一样久。实际上,这意味着返回值的生命周期与参数生命周期中的较小值一致:虽然两个参数的生命周期都是标注了 'a,但是实际上这两个参数的真实生命周期可能是不一样的(生命周期 'a 不代表生命周期等于 'a,而是大于等于 'a)。
回忆下“鲁迅”说的话,再参考上面的内容,可以得出:在通过函数签名指定生命周期参数时,我们并没有改变传入引用或者返回引用的真实生命周期,而是告诉编译器当不满足此约束条件时,就拒绝编译通过。
因此 longest 函数并不知道 x 和 y 具体会活多久,只要知道它们的作用域至少能持续 'a 这么长就行。
当把具体的引用传给 longest 时,那生命周期 'a 的大小就是 x 和 y 的作用域的重合部分,换句话说,'a 的大小将等于 x 和 y 中较小的那个。由于返回值的生命周期也被标记为 'a,因此返回值的生命周期也是 x 和 y 中作用域较小的那个。
说实话,这段文字我写的都快崩溃了,不知道你们读起来如何,实在**太绕了。。那就干脆用一个例子来解释吧:
fn main() {
let string1 = String::from("long string is long");
{
let string2 = String::from("xyz");
let result = longest(string1.as_str(), string2.as_str());
println!("The longest string is {}", result);
}
}
在上例中,string1 的作用域直到 main 函数的结束,而 string2 的作用域到内部花括号的结束 },那么根据之前的理论,'a 是两者中作用域较小的那个,也就是 'a 的生命周期等于 string2 的生命周期,同理,由于函数返回的生命周期也是 'a,可以得出函数返回的生命周期也等于 string2 的生命周期。
现在来验证下上面的结论:result 的生命周期等于参数中生命周期最小的,因此要等于 string2 的生命周期,也就是说,result 要活得和 string2 一样久,观察下代码的实现,可以发现这个结论是正确的!
因此,在这种情况下,通过生命周期标注,编译器得出了和我们肉眼观察一样的结论,而不再是一个蒙圈的大聪明。
再来看一个例子,该例子证明了 result 的生命周期必须等于两个参数中生命周期较小的那个:
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {}", result);
}
Bang,错误冒头了:
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {}", result);
| ------ borrow later used here
在上述代码中,result 必须要活到 println!处,因为 result 的生命周期是 'a,因此 'a 必须持续到 println!。
在 longest 函数中,string2 的生命周期也是 'a,由此说明 string2 也必须活到 println! 处,可是 string2 在代码中实际上只能活到内部语句块的花括号处 },小于它应该具备的生命周期 'a,因此编译出错。
作为人类,我们可以很清晰的看出 result 实际上引用了 string1,因为 string1 的长度明显要比 string2 长,既然如此,编译器不该如此矫情才对,它应该能认识到 result 没有引用 string2,让我们这段代码通过。只能说,作为尊贵的人类,编译器的发明者,你高估了这个工具的能力,它真的做不到!而且 Rust 编译器在调教上是非常保守的:当可能出错也可能不出错时,它会选择前者,抛出编译错误。
总之,显式的使用生命周期,可以让编译器正确的认识到多个引用之间的关系,最终帮我们提前规避可能存在的代码风险。
小练习:尝试着去更改 longest 函数,例如修改参数、生命周期或者返回值,然后推测结果如何,最后再跟编译器的输出进行印证。
深入思考生命周期标注 使用生命周期的方式往往取决于函数的功能,例如之前的 longest 函数,如果它永远只返回第一个参数 x,生命周期的标注该如何修改(该例子就是上面的小练习结果之一)?
fn longest<'a>(x: &'a str, y: &str) -> &'a str {
x
}
在此例中,y 完全没有被使用,因此 y 的生命周期与 x 和返回值的生命周期没有任何关系,意味着我们也不必再为 y 标注生命周期,只需要标注 x 参数和返回值即可。
函数的返回值如果是一个引用类型,那么它的生命周期只会来源于:
- 函数参数的生命周期
- 函数体中某个新建引用的生命周期 若是后者情况,就是典型的悬垂引用场景:
fn longest<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string");
result.as_str()
}
上面的函数的返回值就和参数 x,y 没有任何关系,而是引用了函数体内创建的字符串,那么很显然,该函数会报错:
error[E0515]: cannot return value referencing local variable `result` // 返回值result引用了本地的变量
--> src/main.rs:11:5
|
11 | result.as_str()
| ------^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `result` is borrowed here
主要问题就在于,result 在函数结束后就被释放,但是在函数结束后,对 result 的引用依然在继续。在这种情况下,没有办法指定合适的生命周期来让编译通过,因此我们也就在 Rust 中避免了悬垂引用。
那遇到这种情况该怎么办?最好的办法就是返回内部字符串的所有权,然后把字符串的所有权转移给调用者:
fn longest<'a>(_x: &str, _y: &str) -> String {
String::from("really long string")
}
fn main() {
let s = longest("not", "important");
}
至此,可以对生命周期进行下总结:生命周期语法用来将函数的多个引用参数和返回值的作用域关联到一起,一旦关联到一起后,Rust 就拥有充分的信息来确保我们的操作是内存安全的。
结构体中的生命周期
不仅仅函数具有生命周期,结构体其实也有这个概念,只不过我们之前对结构体的使用都停留在非引用类型字段上。细心的同学应该能回想起来,之前为什么不在结构体中使用字符串字面量或者字符串切片,而是统一使用 String 类型?原因很简单,后者在结构体初始化时,只要转移所有权即可,而前者,抱歉,它们是引用,它们不能为所欲为。
既然之前已经理解了生命周期,那么意味着在结构体中使用引用也变得可能:只要为结构体中的每一个引用标注上生命周期即可:
struct ImportantExcerpt<'a> {
part: &'a str,
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().expect("Could not find a '.'");
let i = ImportantExcerpt {
part: first_sentence,
};
}
ImportantExcerpt 结构体中有一个引用类型的字段 part,因此需要为它标注上生命周期。结构体的生命周期标注语法跟泛型参数语法很像,需要对生命周期参数进行声明 <'a>。该生命周期标注说明,结构体 ImportantExcerpt 所引用的字符串 str 必须比该结构体活得更久。
从 main 函数实现来看,ImportantExcerpt 的生命周期从第 4 行开始,到 main 函数末尾结束,而该结构体引用的字符串从第一行开始,也是到 main 函数末尾结束,可以得出结论结构体引用的字符串活得比结构体久,这符合了编译器对生命周期的要求,因此编译通过。
与之相反,下面的代码就无法通过编译:
#[derive(Debug)]
struct ImportantExcerpt<'a> {
part: &'a str,
}
fn main() {
let i;
{
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().expect("Could not find a '.'");
i = ImportantExcerpt {
part: first_sentence,
};
}
println!("{:?}",i);
}
观察代码,可以看出结构体比它引用的字符串活得更久,引用字符串在内部语句块末尾 } 被释放后,println! 依然在外面使用了该结构体,因此会导致无效的引用,不出所料,编译报错:
error[E0597]: `novel` does not live long enough
--> src/main.rs:10:30
|
10 | let first_sentence = novel.split('.').next().expect("Could not find a '.'");
| ^^^^^^^^^^^^^^^^ borrowed value does not live long enough
...
14 | }
| - `novel` dropped here while still borrowed
15 | println!("{:?}",i);
| - borrow later used here
生命周期消除
实际上,对于编译器来说,每一个引用类型都有一个生命周期,那么为什么我们在使用过程中,很多时候无需标注生命周期?例如:
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
该函数的参数和返回值都是引用类型,尽管我们没有显式的为其标注生命周期,编译依然可以通过。其实原因不复杂,编译器为了简化用户的使用,运用了生命周期消除大法。
对于 first_word 函数,它的返回值是一个引用类型,那么该引用只有两种情况:
- 从参数获取
- 从函数体内部新创建的变量获取 如果是后者,就会出现悬垂引用,最终被编译器拒绝,因此只剩一种情况:返回值的引用是获取自参数,这就意味着参数和返回值的生命周期是一样的。道理很简单,我们能看出来,编译器自然也能看出来,因此,就算我们不标注生命周期,也不会产生歧义。
实际上,在 Rust 1.0 版本之前,这种代码果断不给通过,因为 Rust 要求必须显式的为所有引用标注生命周期:
fn first_word<'a>(s: &'a str) -> &'a str {
在写了大量的类似代码后,Rust 社区抱怨声四起,包括开发者自己都忍不了了,最终揭锅而起,这才有了我们今日的幸福。
生命周期消除的规则不是一蹴而就,而是伴随着 总结-改善 流程的周而复始,一步一步走到今天,这也意味着,该规则以后可能也会进一步增加,我们需要手动标注生命周期的时候也会越来越少,hooray!
在开始之前有几点需要注意:
- 消除规则不是万能的,若编译器不能确定某件事是正确时,会直接判为不正确,那么你还是需要手动标注生命周期
- 函数或者方法中,参数的生命周期被称为 输入生命周期,返回值的生命周期被称为 输出生命周期
三条消除规则 编译器使用三条消除规则来确定哪些场景不需要显式地去标注生命周期。其中第一条规则应用在输入生命周期上,第二、三条应用在输出生命周期上。若编译器发现三条规则都不适用时,就会报错,提示你需要手动标注生命周期。
- 每一个引用参数都会获得独自的生命周期 例如一个引用参数的函数就有一个生命周期标注: fn foo<'a>(x: &'a i32),两个引用参数的有两个生命周期标注:fn foo<'a, 'b>(x: &'a i32, y: &'b i32), 依此类推。
- 若只有一个输入生命周期(函数参数中只有一个引用类型),那么该生命周期会被赋给所有的输出生命周期,也就是所有返回值的生命周期都等于该输入生命周期 例如函数 fn foo(x: &i32) -> &i32,x 参数的生命周期会被自动赋给返回值 &i32,因此该函数等同于 fn foo<'a>(x: &'a i32) -> &'a i32
- 若存在多个输入生命周期,且其中一个是 &self 或 &mut self,则 &self 的生命周期被赋给所有的输出生命周期 拥有 &self 形式的参数,说明该函数是一个 方法,该规则让方法的使用便利度大幅提升。
规则其实很好理解,但是,爱思考的读者肯定要发问了,例如第三条规则,若一个方法,它的返回值的生命周期就是跟参数 &self 的不一样怎么办?总不能强迫我返回的值总是和 &self 活得一样久吧?! 问得好,答案很简单:手动标注生命周期,因为这些规则只是编译器发现你没有标注生命周期时默认去使用的,当你标注生命周期后,编译器自然会乖乖听你的话。
让我们假装自己是编译器,然后看下以下的函数该如何应用这些规则:
例子 1
fn first_word(s: &str) -> &str { // 实际项目中的手写代码
首先,我们手写的代码如上所示时,编译器会先应用第一条规则,为每个参数标注一个生命周期:
fn first_word<'a>(s: &'a str) -> &str { // 编译器自动为参数添加生命周期
此时,第二条规则就可以进行应用,因为函数只有一个输入生命周期,因此该生命周期会被赋予所有的输出生命周期:
fn first_word<'a>(s: &'a str) -> &'a str { // 编译器自动为返回值添加生命周期
此时,编译器为函数签名中的所有引用都自动添加了具体的生命周期,因此编译通过,且用户无需手动去标注生命周期,只要按照 fn first_word(s: &str) -> &str { 的形式写代码即可。
例子 2 再来看一个例子:
fn longest(x: &str, y: &str) -> &str { // 实际项目中的手写代码
首先,编译器会应用第一条规则,为每个参数都标注生命周期:
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {
但是此时,第二条规则却无法被使用,因为输入生命周期有两个,第三条规则也不符合,因为它是函数,不是方法,因此没有 &self 参数。在套用所有规则后,编译器依然无法为返回值标注合适的生命周期,因此,编译器就会报错,提示我们需要手动标注生命周期:
error[E0106]: missing lifetime specifier
--> src/main.rs:1:47
|
1 | fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {
| ------- ------- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
note: these named lifetimes are available to use
--> src/main.rs:1:12
|
1 | fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {
| ^^ ^^
help: consider using one of the available lifetimes here
|
1 | fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &'lifetime str {
| +++++++++
不得不说,Rust 编译器真的很强大,还贴心的给我们提示了该如何修改,虽然。。。好像。。。。它的提示貌似不太准确。这里我们更希望参数和返回值都是 'a 生命周期。
方法中的生命周期
先来回忆下泛型的语法:
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
实际上,为具有生命周期的结构体实现方法时,我们使用的语法跟泛型参数语法很相似:
struct ImportantExcerpt<'a> {
part: &'a str,
}
impl<'a> ImportantExcerpt<'a> {
fn level(&self) -> i32 {
3
}
}
其中有几点需要注意的:
impl 中必须使用结构体的完整名称,包括 <'a>,因为生命周期标注也是结构体类型的一部分! 方法签名中,往往不需要标注生命周期,得益于生命周期消除的第一和第三规则 下面的例子展示了第三规则应用的场景:
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {}", announcement);
self.part
}
}
首先,编译器应用第一规则,给予每个输入参数一个生命周期:
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part<'b>(&'a self, announcement: &'b str) -> &str {
println!("Attention please: {}", announcement);
self.part
}
}
需要注意的是,编译器不知道 announcement 的生命周期到底多长,因此它无法简单的给予它生命周期 'a,而是重新声明了一个全新的生命周期 'b。
接着,编译器应用第三规则,将 &self 的生命周期赋给返回值 &str:
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part<'b>(&'a self, announcement: &'b str) -> &'a str {
println!("Attention please: {}", announcement);
self.part
}
}
Bingo,最开始的代码,尽管我们没有给方法标注生命周期,但是在第一和第三规则的配合下,编译器依然完美的为我们亮起了绿灯。
在结束这块儿内容之前,再来做一个有趣的修改,将方法返回的生命周期改为'b:
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part<'b>(&'a self, announcement: &'b str) -> &'b str {
println!("Attention please: {}", announcement);
self.part
}
}
此时,编译器会报错,因为编译器无法知道 'a 和 'b 的关系。 &self 生命周期是 'a,那么 self.part 的生命周期也是 'a,但是好巧不巧的是,我们手动为返回值 self.part 标注了生命周期 'b,因此编译器需要知道 'a 和 'b 的关系。
有一点很容易推理出来:由于 &'a self 是被引用的一方,因此引用它的 &'b str 必须要活得比它短,否则会出现悬垂引用。因此说明生命周期 'b 必须要比 'a 小,只要满足了这一点,编译器就不会再报错:
impl<'a: 'b, 'b> ImportantExcerpt<'a> {
fn announce_and_return_part(&'a self, announcement: &'b str) -> &'b str {
println!("Attention please: {}", announcement);
self.part
}
}
Bang,一个复杂的玩意儿被甩到了你面前,就问怕不怕?
就关键点稍微解释下:
'a: 'b,是生命周期约束语法,跟泛型约束非常相似,用于说明 'a 必须比 'b 活得久 可以把 'a 和 'b 都在同一个地方声明(如上),或者分开声明但通过 where 'a: 'b 约束生命周期关系,如下:
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part<'b>(&'a self, announcement: &'b str) -> &'b str
where
'a: 'b,
{
println!("Attention please: {}", announcement);
self.part
}
}
总之,实现方法比想象中简单:加一个约束,就能暗示编译器,尽管引用吧,反正我想引用的内容比我活得久,爱咋咋地,我怎么都不会引用到无效的内容!
静态生命周期
在 Rust 中有一个非常特殊的生命周期,那就是 'static,拥有该生命周期的引用可以和整个程序活得一样久。
在之前我们学过字符串字面量,提到过它是被硬编码进 Rust 的二进制文件中,因此这些字符串变量全部具有 'static 的生命周期:
let s: &'static str = "我没啥优点,就是活得久,嘿嘿";
这时候,有些聪明的小脑瓜就开始开动了:当生命周期不知道怎么标时,对类型施加一个静态生命周期的约束 T: 'static 是不是很爽?这样我和编译器再也不用操心它到底活多久了。
嗯,只能说,这个想法是对的,在不少情况下,'static 约束确实可以解决生命周期编译不通过的问题,但是问题来了:本来该引用没有活那么久,但是你非要说它活那么久,万一引入了潜在的 BUG 怎么办?
因此,遇到因为生命周期导致的编译不通过问题,首先想的应该是:是否是我们试图创建一个悬垂引用,或者是试图匹配不一致的生命周期,而不是简单粗暴的用 'static 来解决问题。
但是,话说回来,存在即合理,有时候,'static 确实可以帮助我们解决非常复杂的生命周期问题甚至是无法被手动解决的生命周期问题,那么此时就应该放心大胆的用,只要你确定:你的所有引用的生命周期都是正确的,只是编译器太笨不懂罢了。
总结下:
- 生命周期 'static 意味着能和程序活得一样久,例如字符串字面量和特征对象
- 实在遇到解决不了的生命周期标注问题,可以尝试 T: 'static,有时候它会给你奇迹
一个复杂例子: 泛型、特征约束
手指已经疲软无力,我好想停止,但是华丽的开场都要有与之匹配的谢幕,那我们就用一个稍微复杂点的例子来结束:
use std::fmt::Display;
fn longest_with_an_announcement<'a, T>(
x: &'a str,
y: &'a str,
ann: T,
) -> &'a str
where
T: Display,
{
println!("Announcement! {}", ann);
if x.len() > y.len() {
x
} else {
y
}
}
依然是熟悉的配方 longest,但是多了一段废话: ann,因为要用格式化 {} 来输出 ann,因此需要它实现 Display 特征。
1.15 ❌ 返回值和错误类型
@todo
1.16 👜 包和模块
@todo